Numerical data, both discrete and continuous, can be visualized and summarized in many ways. Common plots include histograms, density plots and scatter plots. Summary statistics include measures of location such as mode and median and measures of spread such as variance or median absolute deviation. It is also common to visualize summary statistics, e.g. on box plot.
flowchart TD
A(Numerical data) --> B(Numerical summary)
A(Numerical data) --> C(Graphical summary)
B(Numerical summary) --> D(Measures of location <br/> e.g. mode, average, median)
B --> E(Measures of spread <br/> e.g. quartiles, variance, standard deviation)
C(Graphical summary) --> F(Histogram <br/> Density plot <br/> Box plot <br/> ...)
Figure 5.1: Example of numerical summaries and graphical visualization applicable to numerical data
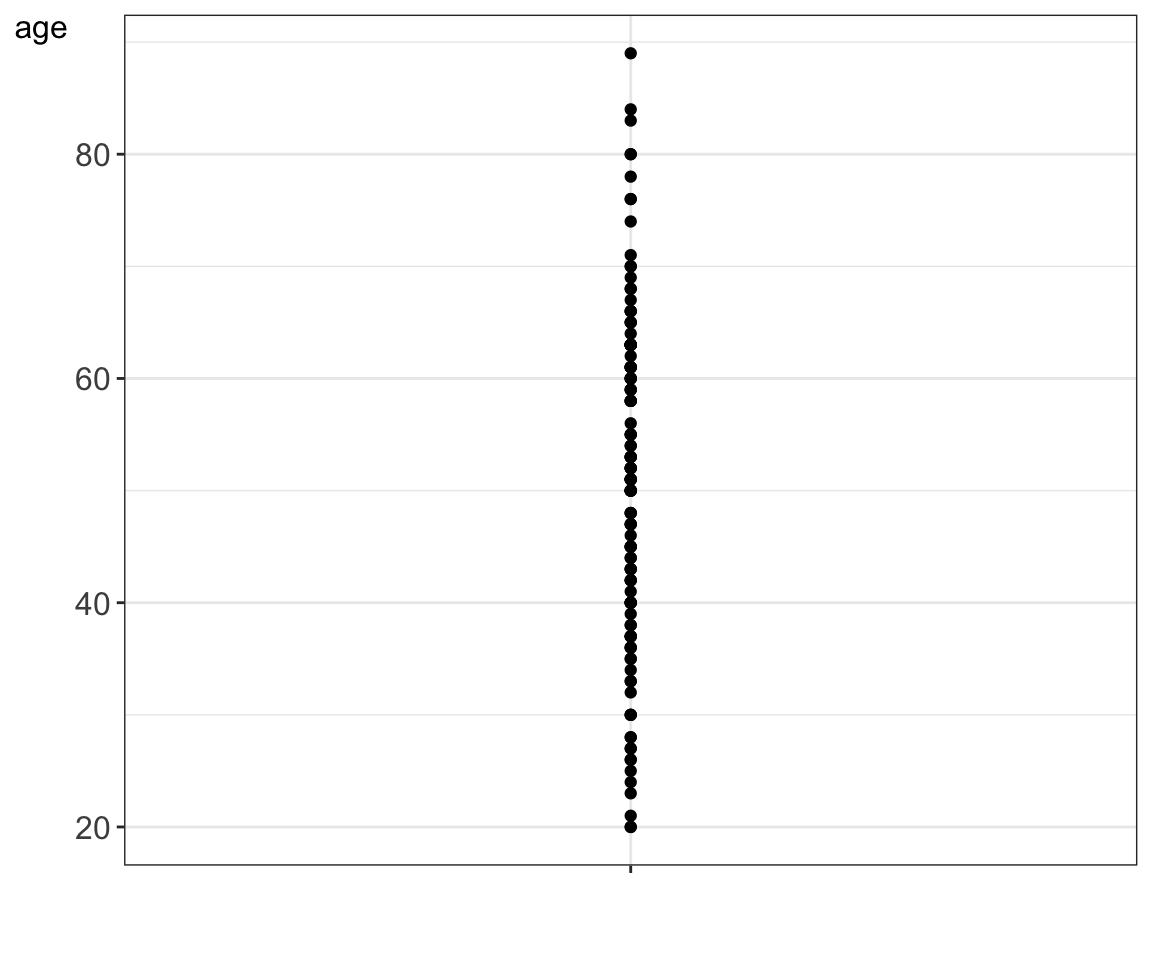
When the data set is not very big, i.e. does not contain millions of measurements for a given numerical variable of interest, it is recommended to visually assess all measurements on a plot. This can be done in a 1D scatter plot, called also a strip plot or a dot plot.
For instance the age values for the 130 participants in the diabetes study are:
Figure 5.2: A strip plot showing age values for the 130 study participants
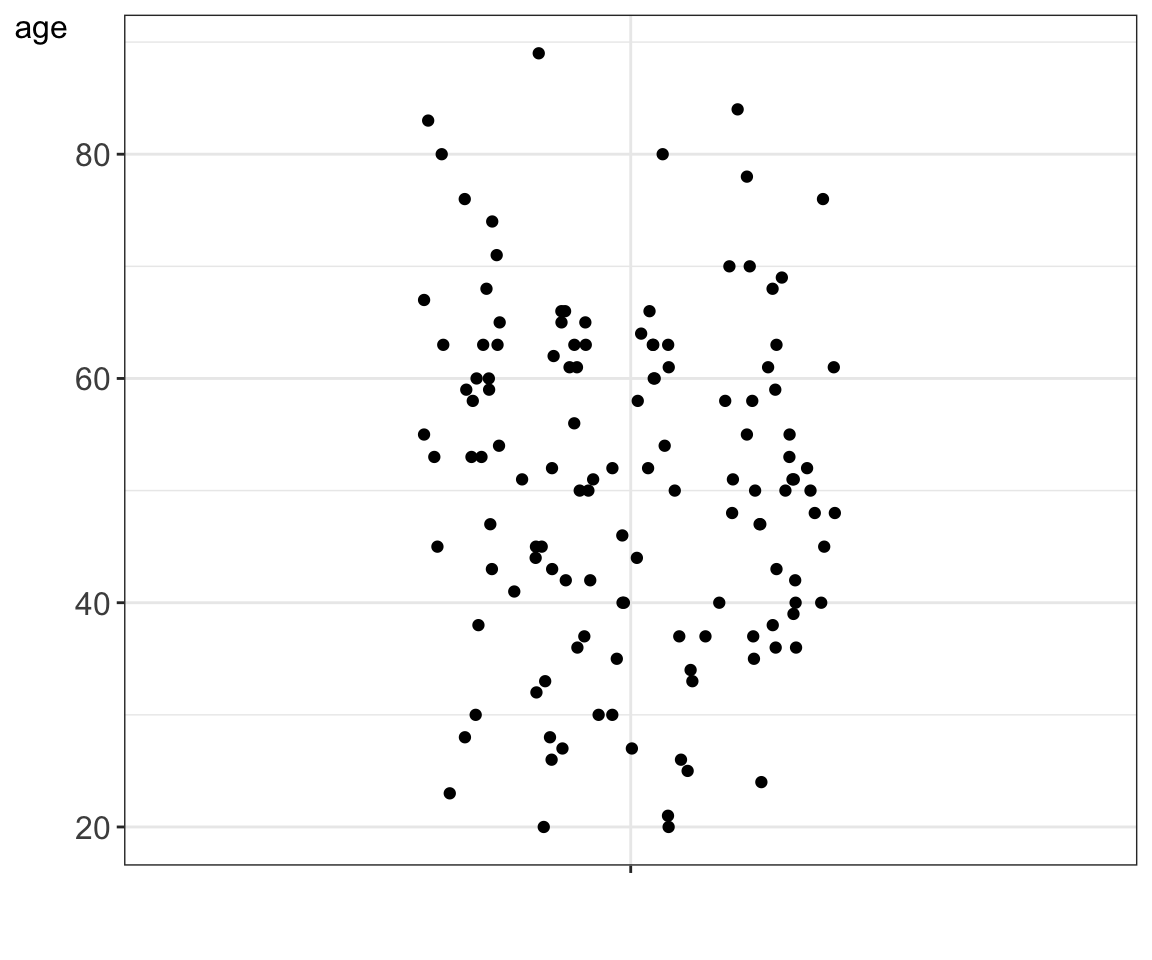
As year was recorded in years and we have over 100 participants, it happens that some age values are repeated, e.g. we have 2 participants who were 20 years old and 3 that were 30 years old at the time of study. These repeated measurements are shown on top of each other and we cannot see them all. A jittered strip plot attempts to reduce such overlays by randomly moving data points by small amounts to the left and right.
Figure 5.3: A jittered strip plot showing age values for the 130 study participants
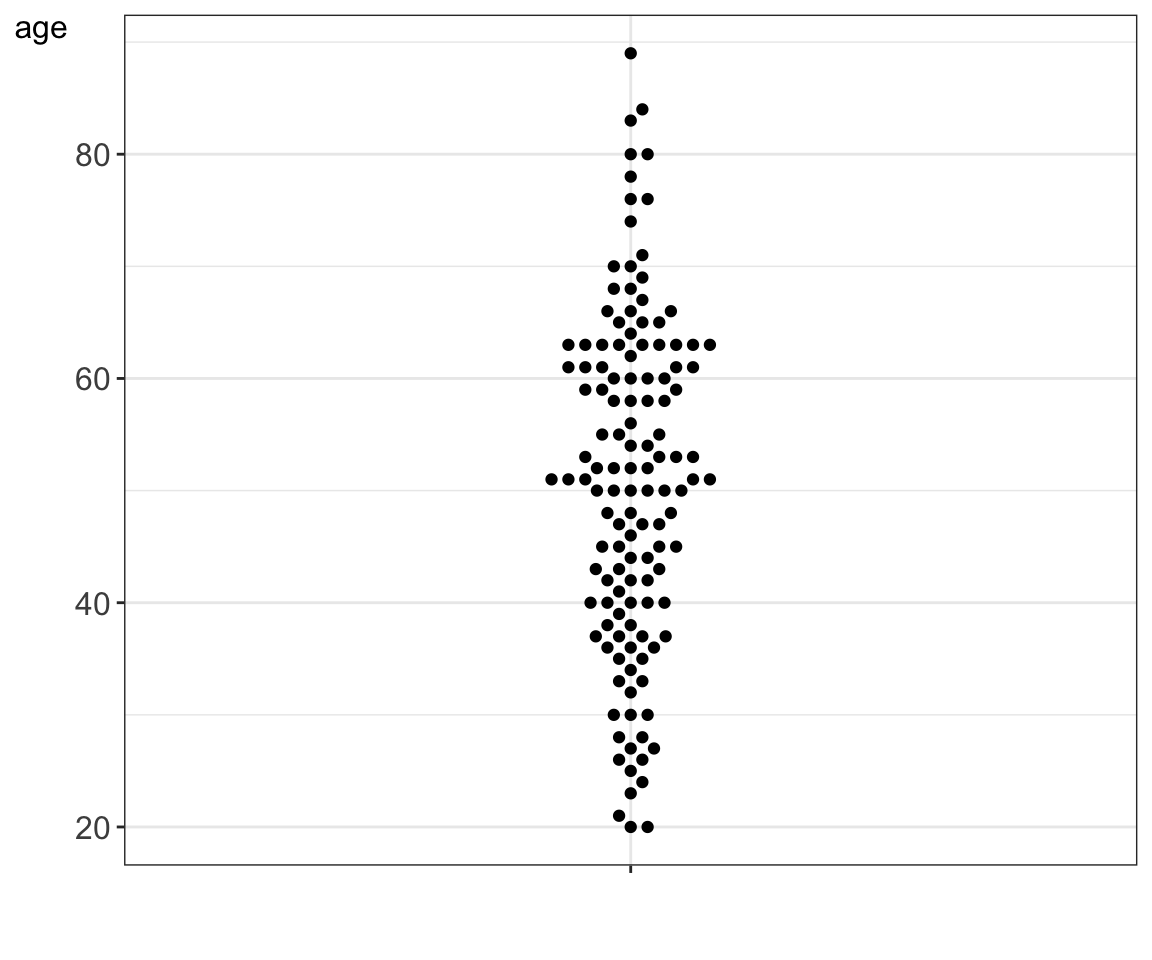
In a jittered strip plot some overlays may still occur, as the data points are moved at random. Further, many data points are moved unnecessarily. In a beeswarm plot data points are moved only when necessary, and even then the data point is only moved by the minimum distance required to avoid overlays.
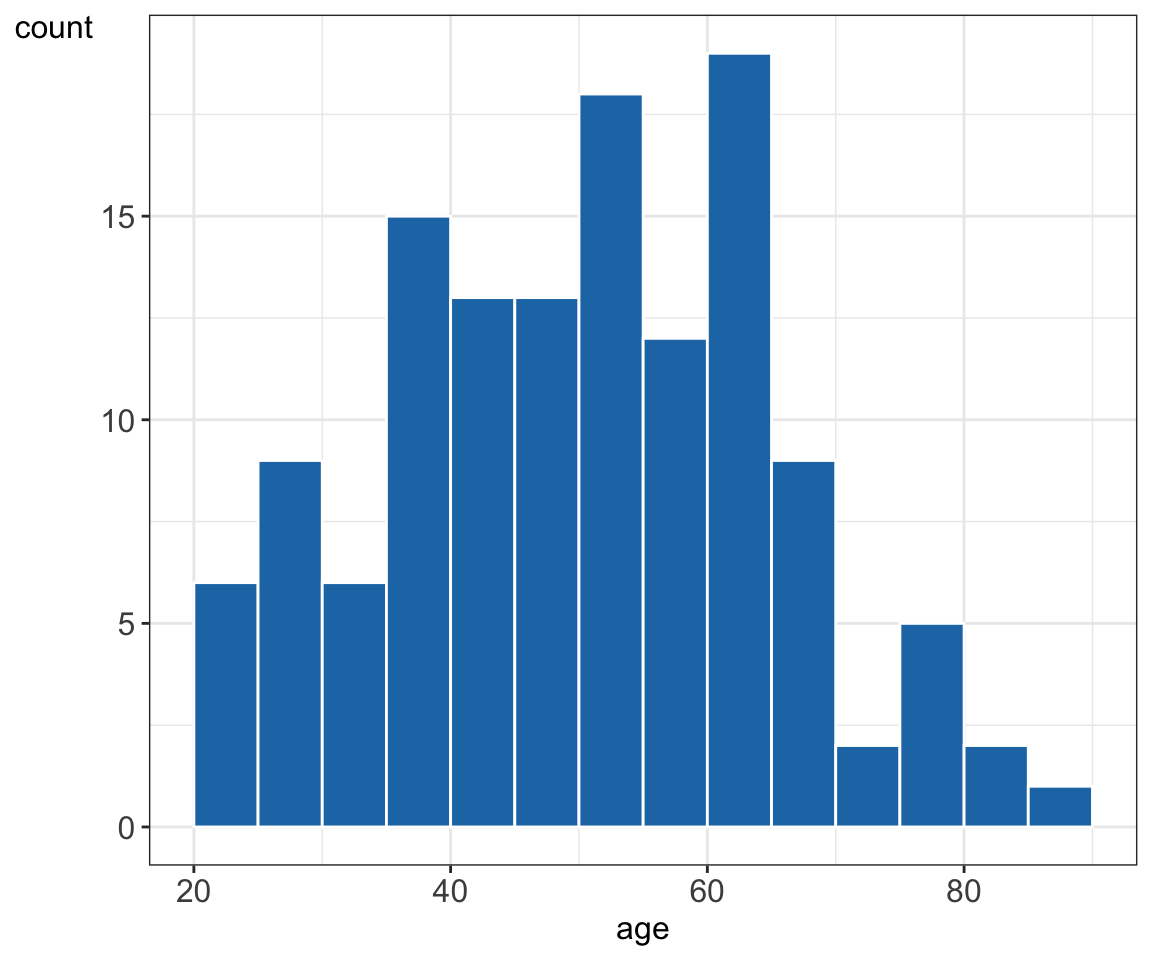
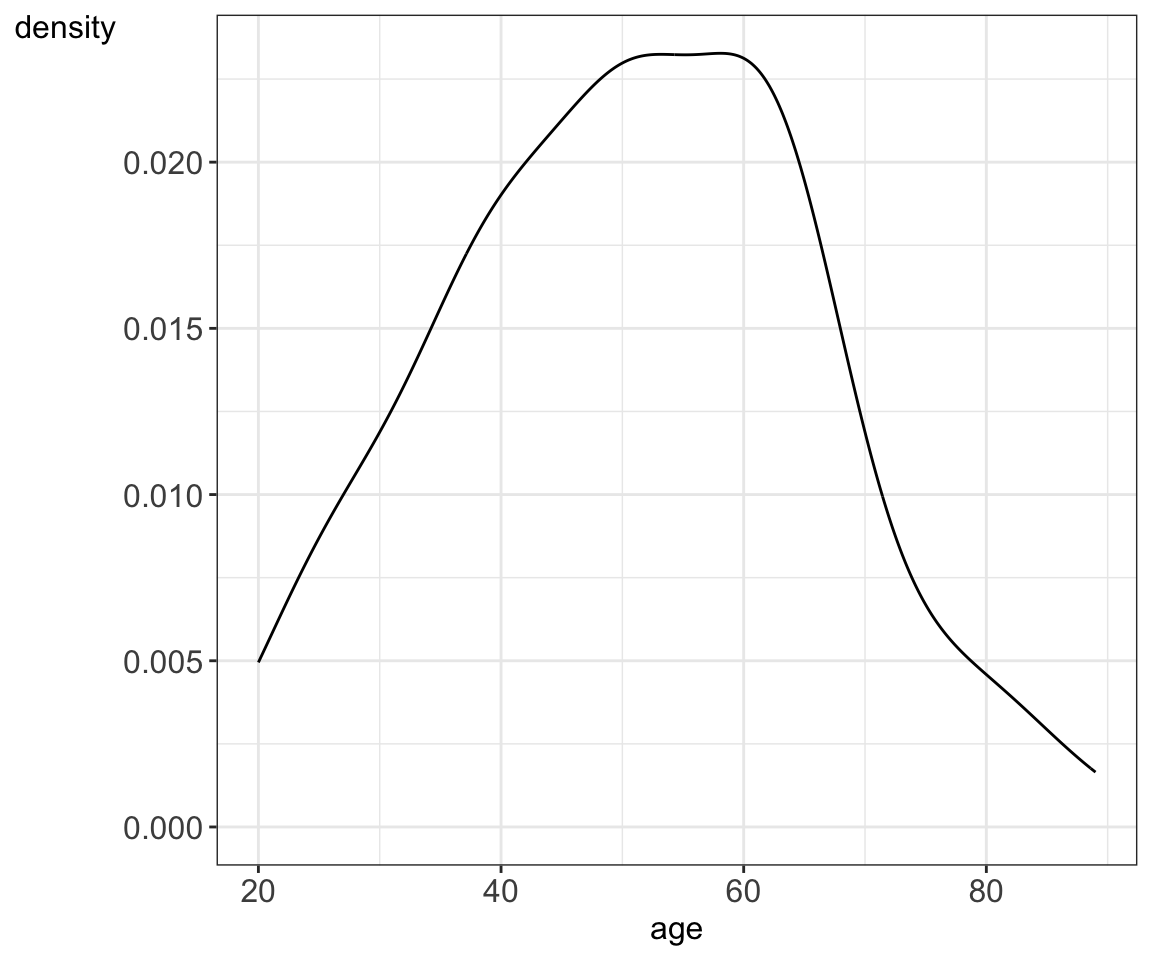
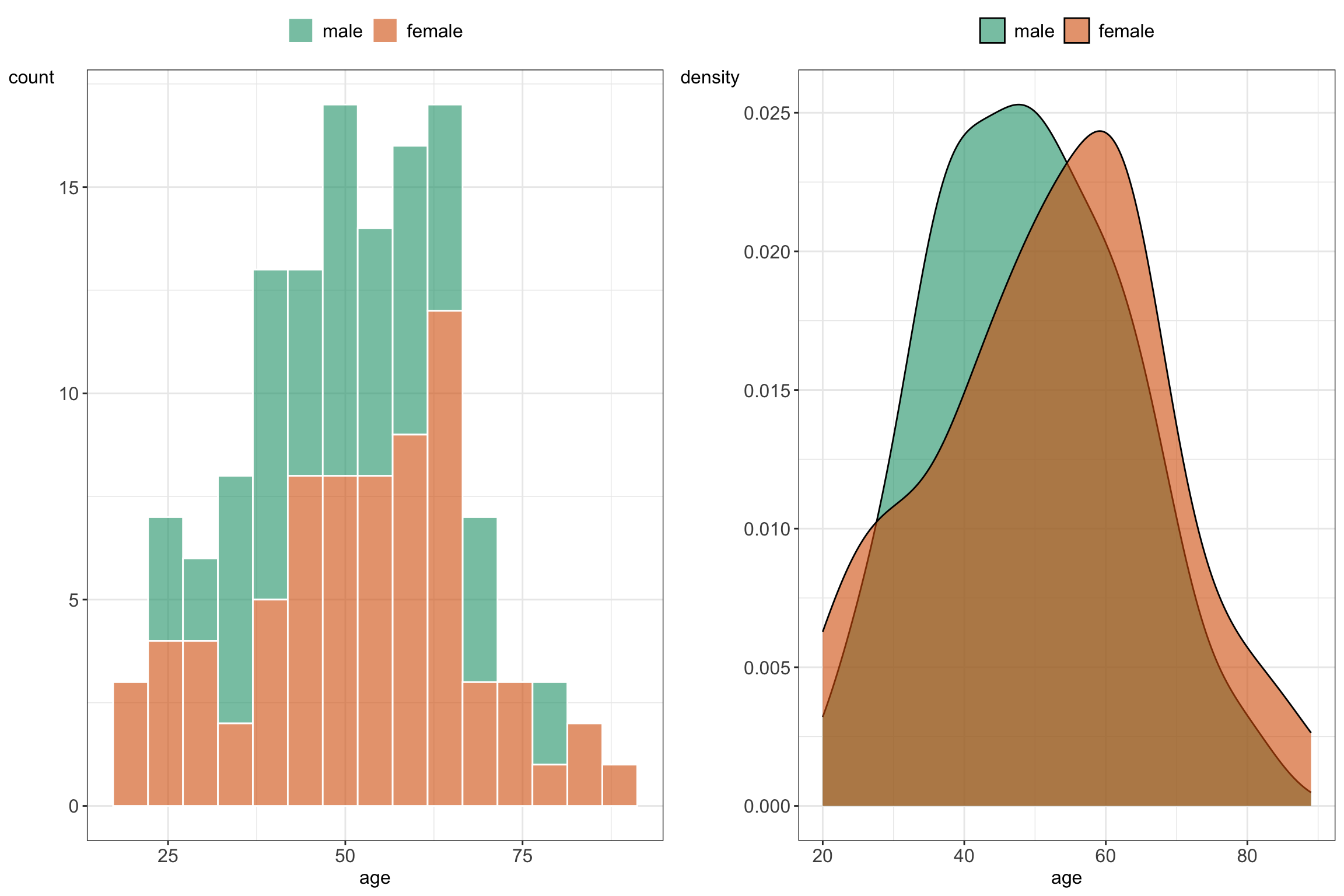
Figure 5.7: Histogram and density plots summarizing age values stratified by gender
5.4 Scatter plot: 2 numerical variables
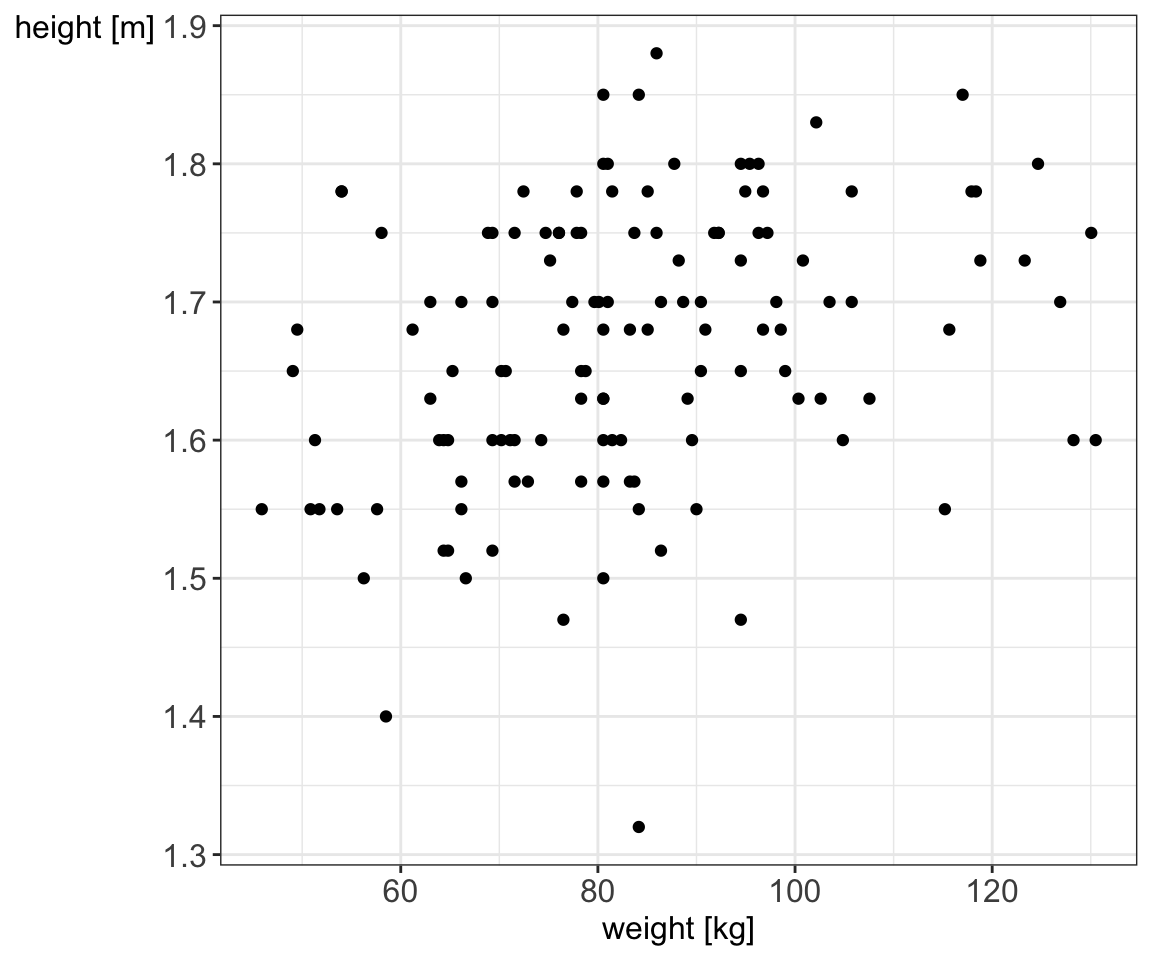
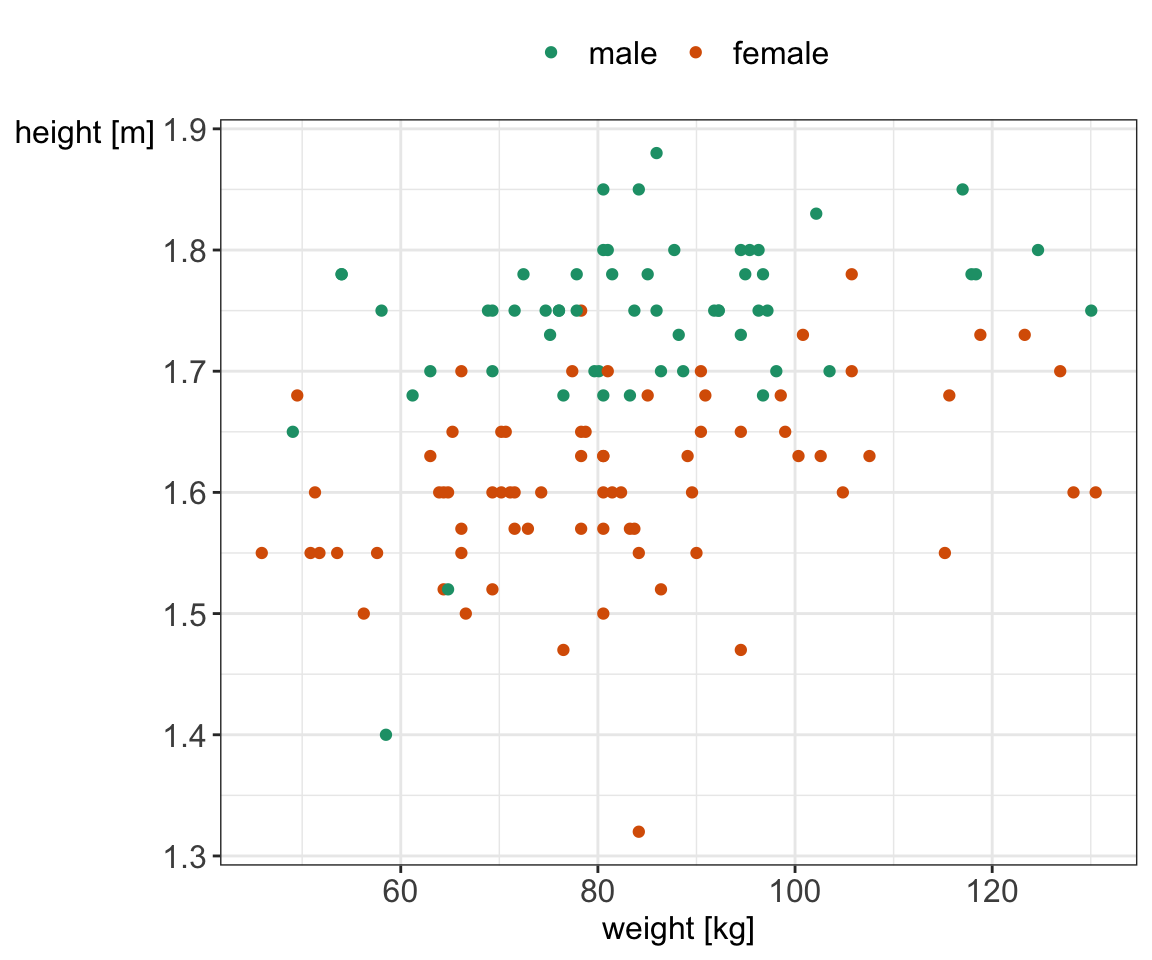
Scatter plots are useful when studying a relationship (association) between two numerical variables. Let’s look at the weight and height for our 130 study participants.
Figure 5.9: Scatter plot showing a relationship between weight and height stratified by gender
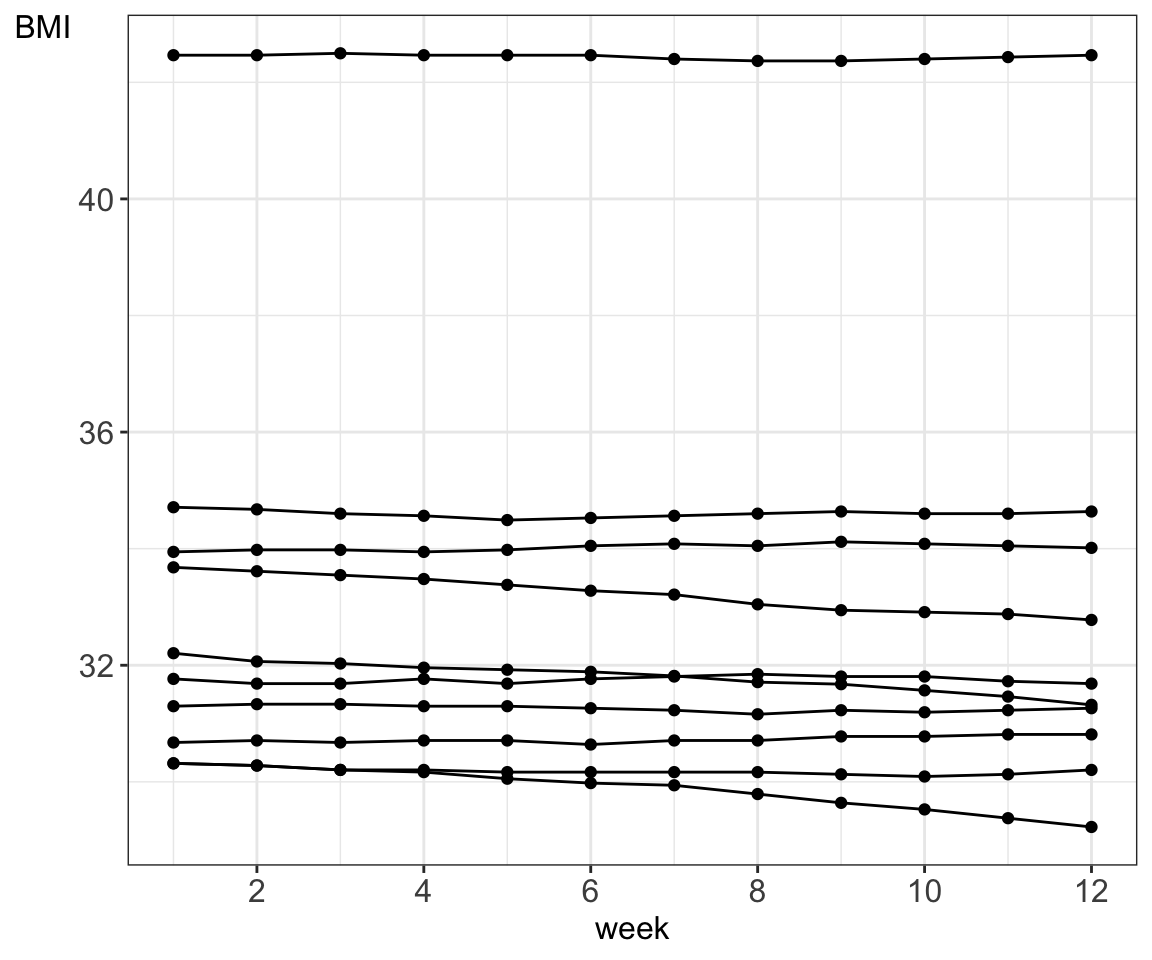
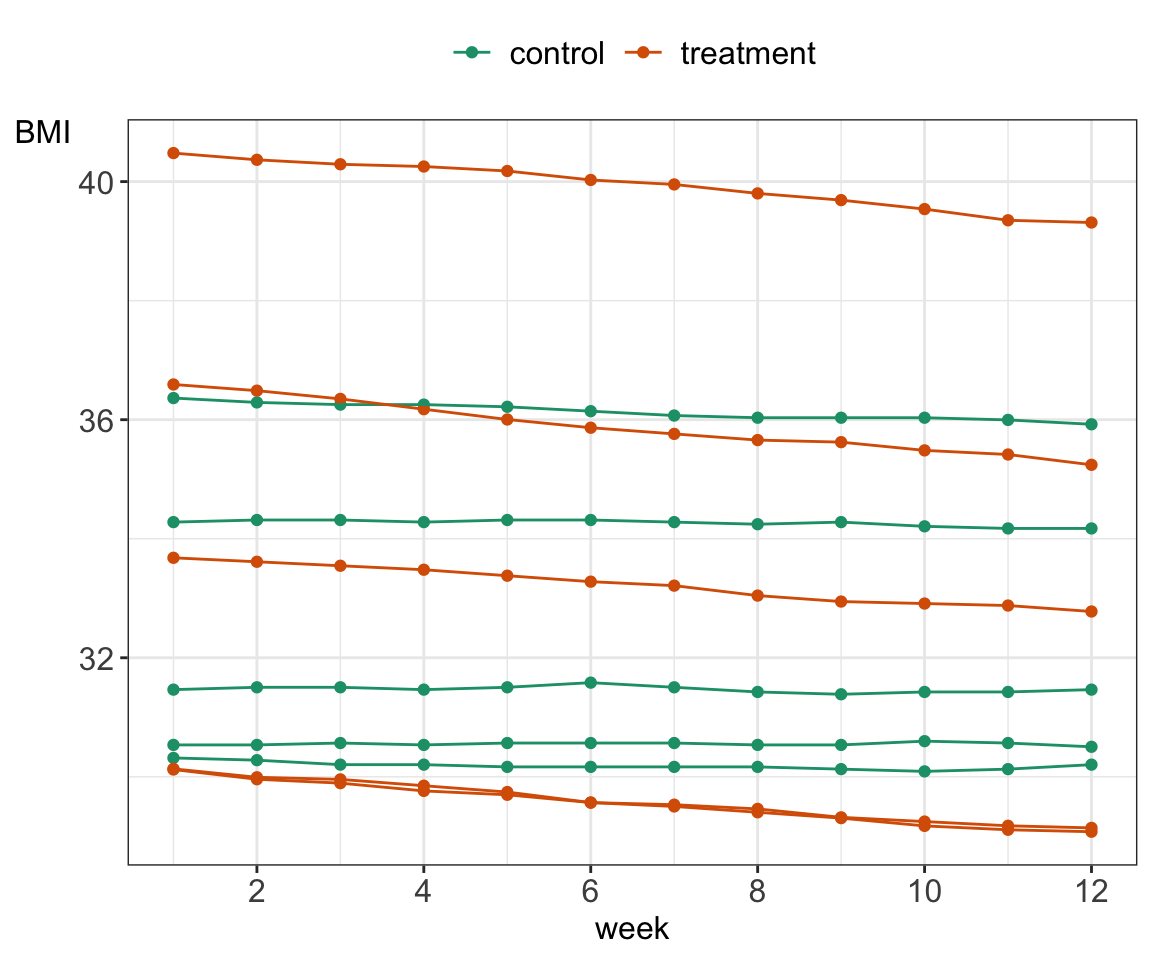
Sometimes, it is useful to connect the observations in the order in which they appear, e.g. when analyzing time series data. The diabetes data set does not contain any measurements over time but we can simulate some BMI values over time for demonstration purposes.
Code
# simulate BMI over time# select participants with BMI >= 30# assign half to control group and half to treatment to reduce weight # add simulated weight loss values to treatment group ca. 0.2 kg per week# add simulated weight fluctuations, ca plus / minus 0.1 kg per weekdata_diabetes_bmi30 <- data_diabetes %>%filter(BMI >=30) %>%select(id, weight, height, BMI) %>%mutate(group=sample(c("control", "treatment"), size=n(), replace=TRUE))# add 52 weeks of simulated BMI valuesno_weeks <-12weight_sim <-matrix(data =NA, nrow =nrow(data_diabetes_bmi30), ncol = no_weeks, dimnames =list(data_diabetes_bmi30$id, paste("week", 1: no_weeks, sep=""))) # initiate matrix to store simulated BMI valuesweight_sim[, 1] <- data_diabetes_bmi30$weight # first column: baseline weightfor (n in1:nrow(data_diabetes_bmi30)){for (p in2:ncol(weight_sim)){# if control group: just fluctuate weight by random values between 0 and 0.2 kg# if treatment: decrease by random values between 0.1 and 0.5 kg fromif (data_diabetes_bmi30$group[n] =="treatment"){ loss <-runif(1, 0.1, 0.5) %>%round(1) weight_sim[n, p] <- weight_sim[n, p-1] - loss } else{ fluctuation <-runif(1, -0.2, 0.2) %>%round(1) weight_sim[n, p] <- weight_sim[n, p-1] + fluctuation } }}# convert to tibbleweight_sim <- weight_sim %>%as_tibble(rownames ="id") %>%mutate(id =as.numeric(id))# join data_diabetes_bmi30 with simulated# keep 5 treatment and 5 control participantsdata_diabets_sim <- data_diabetes_bmi30 %>%as_tibble() %>%left_join(weight_sim, by ="id")# plot BMI over timedata_plot <- data_diabets_sim %>%slice_sample(n =10) %>%select(-weight, -BMI) %>%pivot_longer(-c("id", "group", "height"), names_to ="week", values_to ="weight") %>%mutate(BMI = weight / (height^2)) %>%mutate(week =gsub("week", "", week)) %>%mutate(week =as.numeric(week)) data_plot %>%ggplot(aes(x = week, y = BMI, group = id)) +geom_point() +geom_line() +xlab("week") +ylab("BMI") +theme_bw() +scale_color_brewer(palette ="Dark2") +scale_x_continuous(breaks=pretty_breaks()) + my.ggtheme
Figure 5.10: A line plot for BMI simulated values over 12 weeks for 10 randomly selected study participants