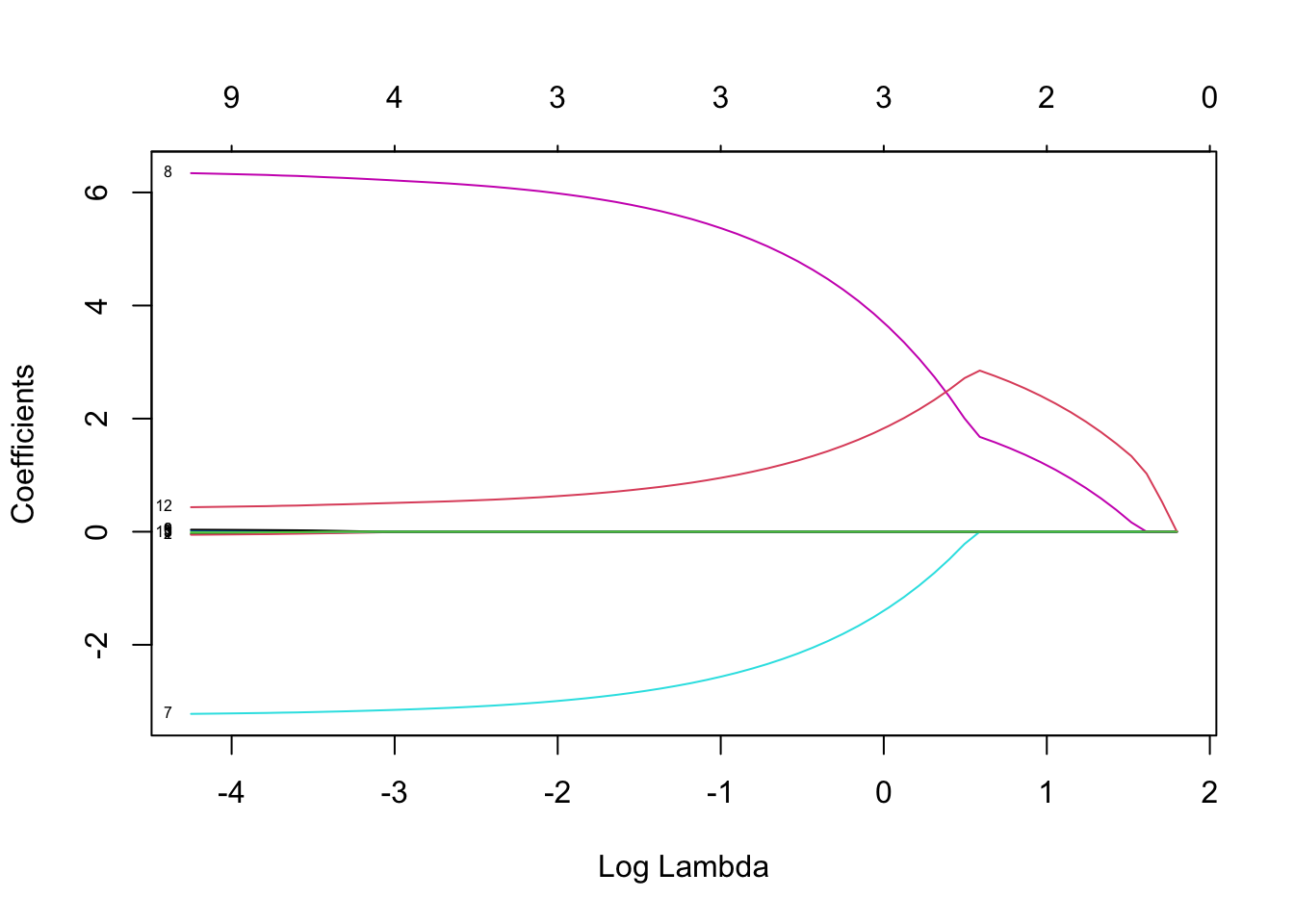
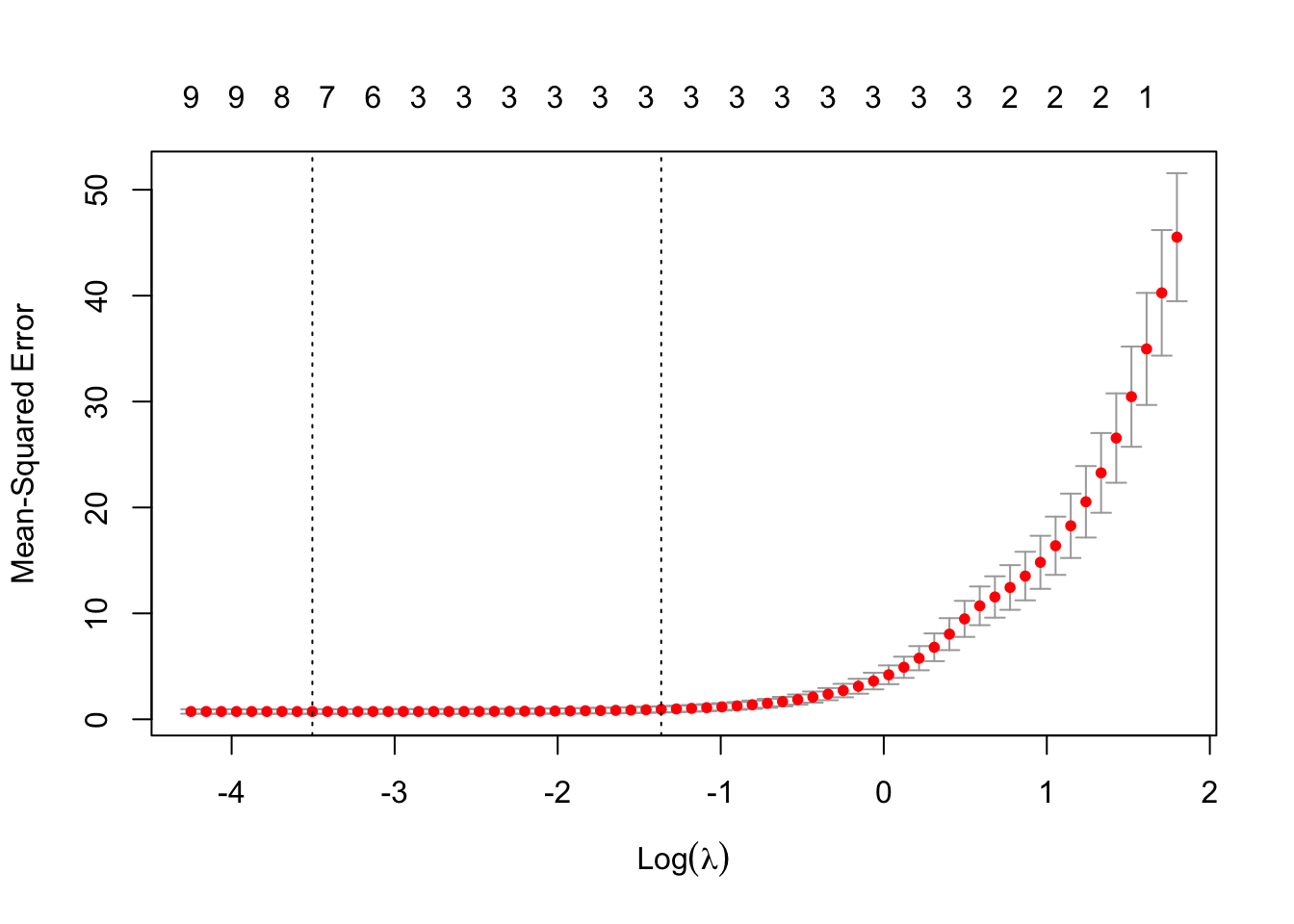
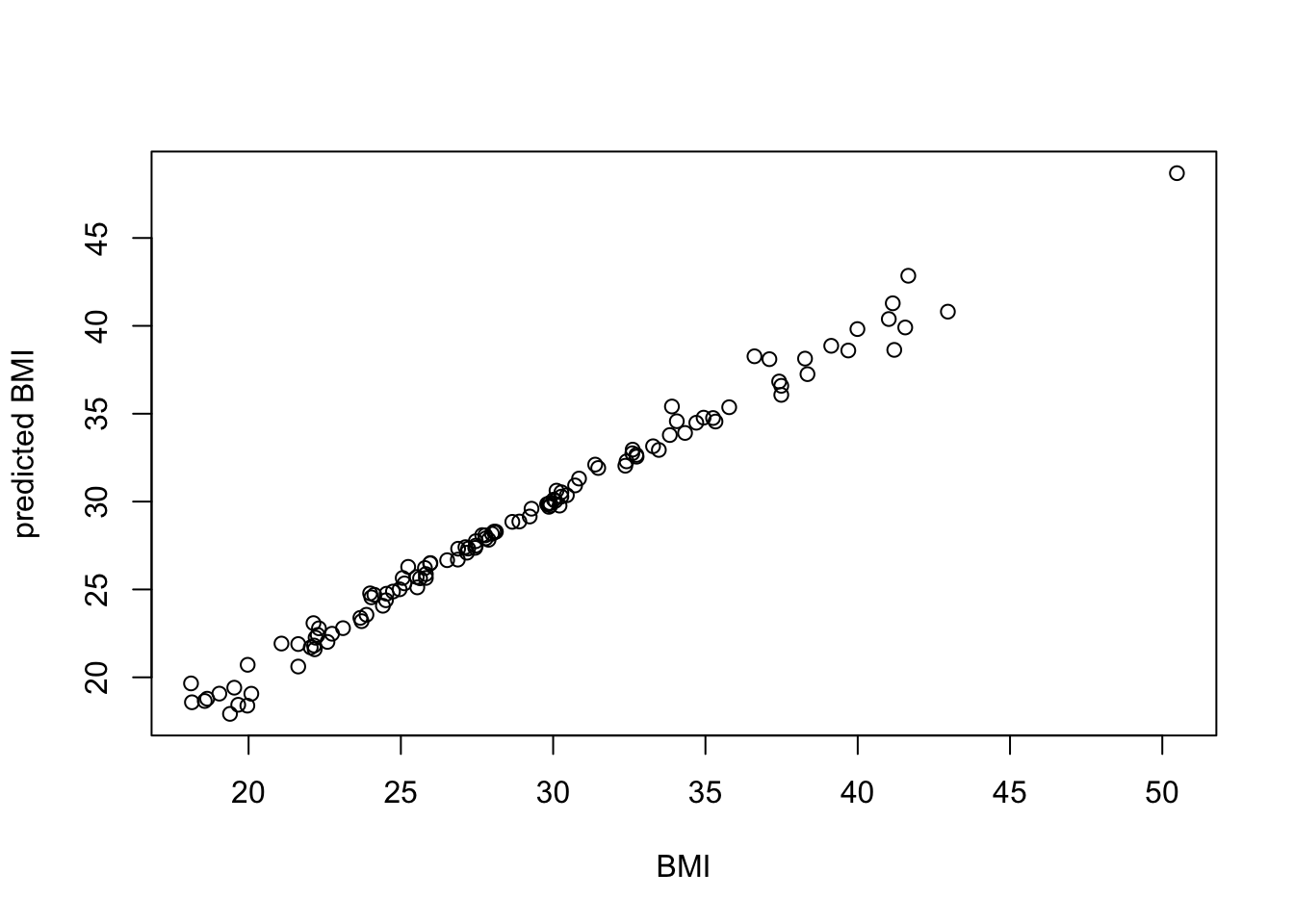
Rows: 403
Columns: 19
$ id <dbl> 1000, 1001, 1002, 1003, 1005, 1008, 1011, 1015, 1016, 1022, 1…
$ chol <dbl> 203, 165, 228, 78, 249, 248, 195, 227, 177, 263, 242, 215, 23…
$ stab.glu <dbl> 82, 97, 92, 93, 90, 94, 92, 75, 87, 89, 82, 128, 75, 79, 76, …
$ hdl <dbl> 56, 24, 37, 12, 28, 69, 41, 44, 49, 40, 54, 34, 36, 46, 30, 4…
$ ratio <dbl> 3.6, 6.9, 6.2, 6.5, 8.9, 3.6, 4.8, 5.2, 3.6, 6.6, 4.5, 6.3, 6…
$ glyhb <dbl> 4.31, 4.44, 4.64, 4.63, 7.72, 4.81, 4.84, 3.94, 4.84, 5.78, 4…
$ location <chr> "Buckingham", "Buckingham", "Buckingham", "Buckingham", "Buck…
$ age <dbl> 46, 29, 58, 67, 64, 34, 30, 37, 45, 55, 60, 38, 27, 40, 36, 3…
$ gender <chr> "female", "female", "female", "male", "male", "male", "male",…
$ height <dbl> 62, 64, 61, 67, 68, 71, 69, 59, 69, 63, 65, 58, 60, 59, 69, 6…
$ weight <dbl> 121, 218, 256, 119, 183, 190, 191, 170, 166, 202, 156, 195, 1…
$ frame <chr> "medium", "large", "large", "large", "medium", "large", "medi…
$ bp.1s <dbl> 118, 112, 190, 110, 138, 132, 161, NA, 160, 108, 130, 102, 13…
$ bp.1d <dbl> 59, 68, 92, 50, 80, 86, 112, NA, 80, 72, 90, 68, 80, NA, 66, …
$ bp.2s <dbl> NA, NA, 185, NA, NA, NA, 161, NA, 128, NA, 130, NA, NA, NA, N…
$ bp.2d <dbl> NA, NA, 92, NA, NA, NA, 112, NA, 86, NA, 90, NA, NA, NA, NA, …
$ waist <dbl> 29, 46, 49, 33, 44, 36, 46, 34, 34, 45, 39, 42, 35, 37, 36, 3…
$ hip <dbl> 38, 48, 57, 38, 41, 42, 49, 39, 40, 50, 45, 50, 41, 43, 40, 4…
$ time.ppn <dbl> 720, 360, 180, 480, 300, 195, 720, 1020, 300, 240, 300, 90, 7…
Rows: 375
Columns: 14
$ BMI <dbl> 22.13, 37.42, 48.37, 18.64, 27.82, 26.50, 28.20, 24.51, 35.78…
$ chol <dbl> 203, 165, 228, 78, 249, 248, 195, 177, 263, 242, 215, 238, 19…
$ stab.glu <dbl> 82, 97, 92, 93, 90, 94, 92, 87, 89, 82, 128, 75, 76, 83, 78, …
$ hdl <dbl> 56, 24, 37, 12, 28, 69, 41, 49, 40, 54, 34, 36, 30, 47, 38, 6…
$ ratio <dbl> 3.6, 6.9, 6.2, 6.5, 8.9, 3.6, 4.8, 3.6, 6.6, 4.5, 6.3, 6.6, 6…
$ glyhb <dbl> 4.31, 4.44, 4.64, 4.63, 7.72, 4.81, 4.84, 4.84, 5.78, 4.77, 4…
$ age <dbl> 46, 29, 58, 67, 64, 34, 30, 45, 55, 60, 38, 27, 36, 33, 50, 2…
$ height <dbl> 62, 64, 61, 67, 68, 71, 69, 69, 63, 65, 58, 60, 69, 65, 65, 6…
$ weight <dbl> 121, 218, 256, 119, 183, 190, 191, 166, 202, 156, 195, 170, 1…
$ bp.1s <dbl> 118, 112, 190, 110, 138, 132, 161, 160, 108, 130, 102, 130, 1…
$ bp.1d <dbl> 59, 68, 92, 50, 80, 86, 112, 80, 72, 90, 68, 80, 66, 90, 100,…
$ waist <dbl> 29, 46, 49, 33, 44, 36, 46, 34, 45, 39, 42, 35, 36, 37, 37, 3…
$ hip <dbl> 38, 48, 57, 38, 41, 42, 49, 40, 50, 45, 50, 41, 40, 41, 43, 3…
$ time.ppn <dbl> 720, 360, 180, 480, 300, 195, 720, 300, 240, 300, 90, 720, 22…