Exercise 1 (KNN with k-fold cross-validation) Modify the demo example to select best value of \(k\) using 5-fold cross validation. Do we get a different value of the best \(k\)? Does it improve the performance on the test data?
Hint: you can use “create_folds()” function from “library(splitTools)” to create the folds.
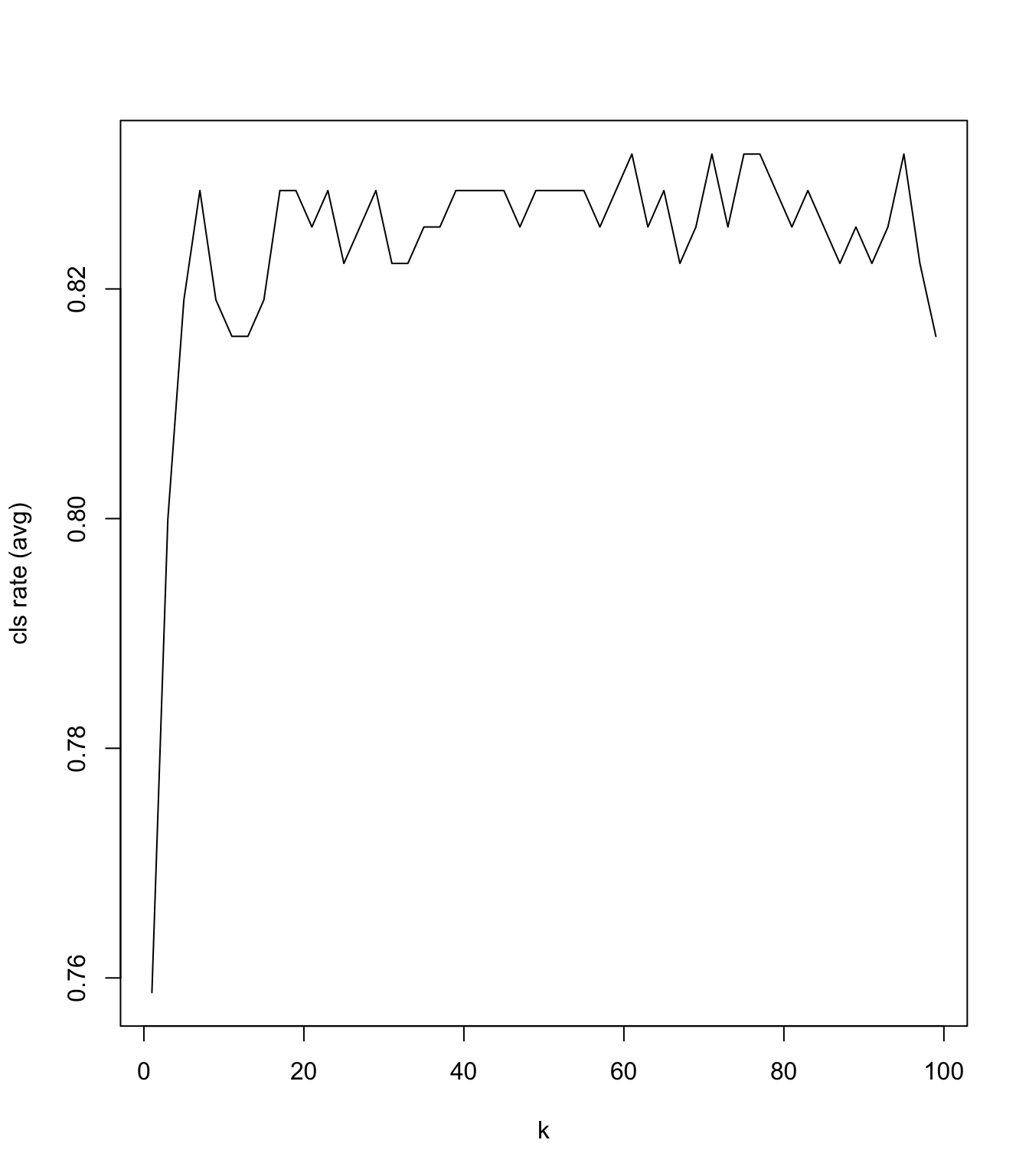
# load librarieslibrary(tidyverse)library(splitTools)library(kknn)# input datainput_diabetes <-read_csv("data/data-diabetes.csv")# clean datainch2cm <-2.54pound2kg <-0.45data_diabetes <- input_diabetes %>%mutate(height = height * inch2cm /100, height =round(height, 2)) %>%mutate(waist = waist * inch2cm) %>%mutate(weight = weight * pound2kg, weight =round(weight, 2)) %>%mutate(BMI = weight / height^2, BMI =round(BMI, 2)) %>%mutate(obese =cut(BMI, breaks =c(0, 29.9, 100), labels =c("No", "Yes"))) %>%mutate(diabetic =ifelse(glyhb >7, "Yes", "No"), diabetic =factor(diabetic, levels =c("No", "Yes"))) %>%mutate(location =factor(location)) %>%mutate(frame =factor(frame)) %>%mutate(gender =factor(gender))# select data for KNNdata_input <- data_diabetes %>%select(obese, waist, hdl) %>%na.omit()# set random seedrandseed <-123set.seed(randseed)# split data into other (non-test) and testsplits <-partition(data_input$obese, p =c(other =0.80, test =0.20))data_test <- data_input[splits$test, ]data_other <- data_input[splits$other, ]# create train and validation foldskfolds_train <-create_folds(data_other$obese, k =5, seed = randseed)kfolds_valid <-create_folds(data_other$obese, k =5, invert =TRUE, # gives back indices of the validation samplesseed = randseed) # OBS! use the same seed as above in kfolds_train()# prepare parameters search spacen <-nrow(data_other)k_values <-seq(1, 100, 2) # check every odd value of k between 1 and 50# allocate empty matrix to collect overall classification rate for each k and 5-foldsfolds <-5cls_rate <-matrix(data =NA, ncol = folds, nrow =length(k_values))colnames(cls_rate) <-paste("kfold", 1:folds, sep="")rownames(cls_rate) <-paste("k", k_values, sep="")for (k inseq_along(k_values)){# for every value of k # fit model on every train fold and evaluate on every validation foldfor (f in1:folds){ data_train <- data_other[kfolds_train[[f]], ] data_valid <- data_other[kfolds_valid[[f]], ]# fit model given k value model <-kknn(obese ~., data_train, data_valid, k = k_values[k], kernel ="rectangular")# extract predicted class (predicted obesity status) cls_pred <- model$fitted.values# define actual class (actual obesity status) cls_true <- data_valid$obese# calculate overall classification rate cls_rate[k, f] <-sum((cls_pred == cls_true))/length(cls_pred) }}# plot average classification rate (across folds) as a function of kcls_rate_avg <-apply(cls_rate, 1, mean)plot(k_values, cls_rate_avg, type="l", xlab="k", ylab="cls rate (avg)")
# For which value of k do we reach the highest classification rate?k_best <- k_values[which.max(cls_rate_avg)]print(k_best)## [1] 71# How would our model perform on the future data using the optimal k?model_final <-kknn(obese ~., data_other, data_test, k=k_best, kernel ="rectangular")cls_pred <- model_final$fitted.valuescls_true <- data_test$obesecls_rate <-sum((cls_pred == cls_true))/length(cls_pred)print(cls_rate)## [1] 0.8481013