import numpy as np
import pandas as pd
import scanpy as sc
import matplotlib.pyplot as plt
import warnings
import os
import subprocess
warnings.simplefilter(action='ignore', category=Warning)
# verbosity: errors (0), warnings (1), info (2), hints (3)
sc.settings.verbosity = 3
sc.settings.set_figure_params(dpi=80)
%matplotlib inline
Note
Code chunks run Python commands unless it starts with %%bash, in which case, those chunks run shell commands.
In this tutorial we will look at different ways of integrating multiple single cell RNA-seq datasets. We will explore a few different methods to correct for batch effects across datasets. Seurat uses the data integration method presented in Comprehensive Integration of Single Cell Data, while Scran and Scanpy use a mutual Nearest neighbour method (MNN). Below you can find a list of some methods for single data integration:
| Markdown | Language | Library | Ref |
|---|---|---|---|
| CCA | R | Seurat | Cell |
| MNN | R/Python | Scater/Scanpy | Nat. Biotech. |
| Conos | R | conos | Nat. Methods |
| Scanorama | Python | scanorama | Nat. Biotech. |
1 Data preparation
Let’s first load necessary libraries and the data saved in the previous lab.
Create individual adata objects per batch.
# download pre-computed data if missing or long compute
fetch_data = True
# url for source and intermediate data
path_data = "https://nextcloud.dc.scilifelab.se/public.php/webdav"
curl_upass = "zbC5fr2LbEZ9rSE:scRNAseq2025"
path_results = "data/covid/results"
if not os.path.exists(path_results):
os.makedirs(path_results, exist_ok=True)
path_file = "data/covid/results/scanpy_covid_qc_dr.h5ad"
if fetch_data and not os.path.exists(path_file):
file_url = os.path.join(path_data, "covid/results_scanpy/scanpy_covid_qc_dr.h5ad")
subprocess.call(["curl", "-u", curl_upass, "-o", path_file, file_url ])
adata = sc.read_h5ad(path_file)
adataAnnData object with n_obs × n_vars = 7222 × 2626
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap'
obsm: 'X_pca', 'X_tsne', 'X_umap'
varm: 'PCs'
obsp: 'connectivities', 'distances'print(adata.X.shape)(7222, 2626)As the stored AnnData object contains scaled data based on variable genes, we need to make a new object with the logtransformed normalized counts. The new variable gene selection should not be performed on the scaled data matrix.
# First store the old set of hvgs
var_genes_all = adata.var.highly_variable
print("Highly variable genes: %d"%sum(var_genes_all))
adata = adata.raw.to_adata()
# in some versions of Anndata there is an issue with information on the logtransformation in the slot log1p.base so we set it to None to not get errors.
adata.uns['log1p']['base']=None
# check that the matrix looks like normalized counts
print(adata.X[1:10,1:10])Highly variable genes: 2626
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 2 stored elements and shape (9, 9)>
Coords Values
(0, 3) 0.7825693876867097
(7, 6) 1.13110413367469852 Detect variable genes
Variable genes can be detected across the full dataset, but then we run the risk of getting many batch-specific genes that will drive a lot of the variation. Or we can select variable genes from each batch separately to get only celltype variation. In the dimensionality reduction exercise, we already selected variable genes, so they are already stored in adata.var.highly_variable.
Detect variable genes in each dataset separately using the batch_key parameter.
sc.pp.highly_variable_genes(adata, min_mean=0.0125, max_mean=3, min_disp=0.5, batch_key = 'sample')
print("Highly variable genes intersection: %d"%sum(adata.var.highly_variable_intersection))
print("Number of batches where gene is variable:")
print(adata.var.highly_variable_nbatches.value_counts())
var_genes_batch = adata.var.highly_variable_nbatches > 0extracting highly variable genes
finished (0:00:01)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
Highly variable genes intersection: 122
Number of batches where gene is variable:
highly_variable_nbatches
0 7876
1 4163
2 3161
3 2025
4 1115
5 559
6 277
7 170
8 122
Name: count, dtype: int64Compare overlap of variable genes with batches or with all data.
print("Any batch var genes: %d"%sum(var_genes_batch))
print("All data var genes: %d"%sum(var_genes_all))
print("Overlap: %d"%sum(var_genes_batch & var_genes_all))
print("Variable genes in all batches: %d"%sum(adata.var.highly_variable_nbatches == 6))
print("Overlap batch instersection and all: %d"%sum(var_genes_all & adata.var.highly_variable_intersection))Any batch var genes: 11592
All data var genes: 2626
Overlap: 2625
Variable genes in all batches: 277
Overlap batch instersection and all: 122
NoteDiscuss
Did you understand the difference between running variable gene selection per dataset and combining them vs running it on all samples together. Can you think of any situation where it would be best to run it on all samples and a situation where it should be done by batch?
Select all genes that are variable in at least 2 datasets and use for remaining analysis.
var_select = adata.var.highly_variable_nbatches > 2
var_genes = var_select.index[var_select]
len(var_genes)4268Run scaling and pca with that set of genes.
# first store again the full matrix to the raw slot.
adata.raw = adata
adata = adata[:,var_genes]
sc.pp.scale(adata)
sc.pp.pca(adata, svd_solver='arpack', random_state=573)computing PCA
with n_comps=50
finished (0:00:01)Before running integrations and new dimensionality reduction, lets save the old Umap and tSNE into a new slot in obsm.
adata.obsm['X_umap_uncorr'] = adata.obsm['X_umap']
adata.obsm['X_tsne_uncorr'] = adata.obsm['X_tsne']3 BBKNN
First, we will run BBKNN, it takes the anndata object and calculates a knn graph that is batch balanced. We can then use that graph to run Umap, tSNE and/or clustering.
sc.external.pp.bbknn(adata, 'sample')
sc.tl.umap(adata, random_state=331)
sc.tl.tsne(adata, random_state=75)
# save new umap/tsne to new slots in obsm
adata.obsm['X_umap_bbknn'] = adata.obsm['X_umap']
adata.obsm['X_tsne_bbknn'] = adata.obsm['X_tsne']computing batch balanced neighbors
WARNING: consider updating your call to make use of `computation`
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:02)
computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm)
'umap', UMAP parameters (adata.uns) (0:00:36)
computing tSNE
using 'X_pca' with n_pcs = 50
using sklearn.manifold.TSNE
finished: added
'X_tsne', tSNE coordinates (adata.obsm)
'tsne', tSNE parameters (adata.uns) (0:00:11)We can now plot the unintegrated and the integrated space reduced dimensions.
fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.embedding(adata, "X_umap_uncorr",color="sample", title="Uncorrected umap", ax=axs[0,0], show=False)
sc.pl.embedding(adata, "X_tsne_uncorr",color="sample", title="Uncorrected tsne", ax=axs[0,1], show=False)
sc.pl.embedding(adata, "X_umap_bbknn",color="sample", title="BBKNN Corrected umap", ax=axs[1,0], show=False)
sc.pl.embedding(adata, "X_tsne_bbknn",color="sample", title="BBKNN Corrected tsne", ax=axs[1,1], show=False)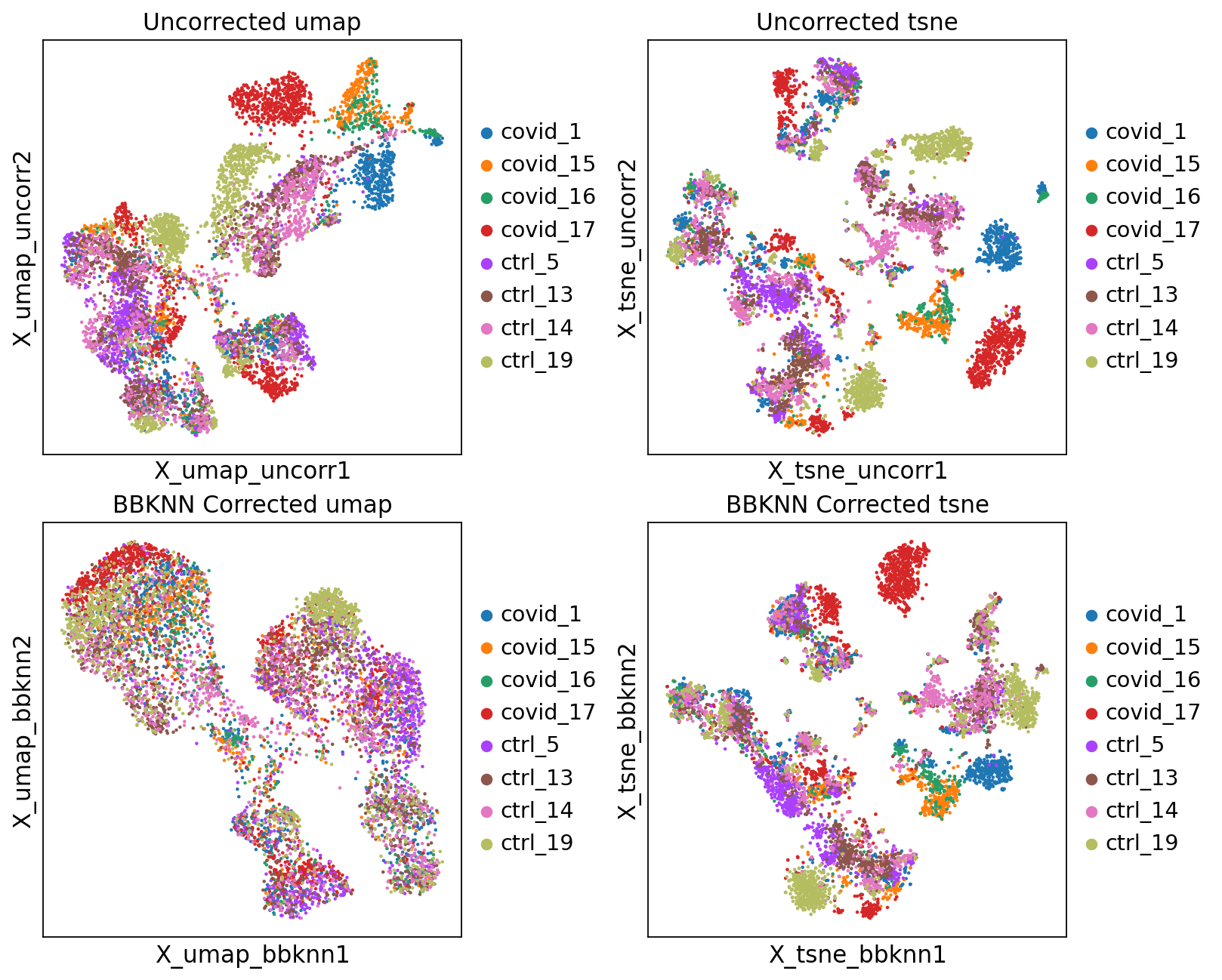
Let’s save the integrated data for further analysis.
save_file = './data/covid/results/scanpy_covid_qc_dr_bbknn.h5ad'
adata.write_h5ad(save_file)4 Harmony
An alternative method for integration is Harmony, for more details on the method, please se their paper Nat. Methods. This method runs the integration on a dimensionality reduction, in most applications the PCA.
import scanpy.external as sce
import harmonypy as hm
## KNOWN BUG:
# harmonypy==0.2.0 has a known bug described in https://github.com/slowkow/harmonypy/issues/49
## Actual function call to run harmony:
# sce.pp.harmony_integrate(adata, 'sample')
## Fix to get 'X_pca_harmony' of the correct shape:
# Extract PCs
_pcs = adata.obsm['X_pca'] # (n_cells, n_pcs)
# Run Harmony
_harmony_out = hm.run_harmony(_pcs, adata.obs, 'sample')
# Z_corr is already a numpy array with shape (n_cells, n_pcs)
adata.obsm['X_pca_harmony'] = _harmony_out.Z_corr
# Then we calculate a new umap and tsne.
sc.pp.neighbors(adata, n_neighbors=10, n_pcs=30, use_rep='X_pca_harmony', random_state=159)
sc.tl.umap(adata, random_state=331)
sc.tl.tsne(adata, use_rep='X_pca_harmony', random_state=75)
sc.tl.leiden(adata, resolution=0.5, random_state=137)computing neighbors
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:00)
computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm)
'umap', UMAP parameters (adata.uns) (0:00:08)
computing tSNE
using sklearn.manifold.TSNE
finished: added
'X_tsne', tSNE coordinates (adata.obsm)
'tsne', tSNE parameters (adata.uns) (0:00:11)
running Leiden clustering
finished: found 12 clusters and added
'leiden', the cluster labels (adata.obs, categorical) (0:00:00)fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.embedding(adata, 'X_tsne_bbknn', color="sample", title="BBKNN tsne", ax=axs[0,0], show=False)
sc.pl.tsne(adata, color="sample", title="Harmony tsne", ax=axs[0,1], show=False)
sc.pl.embedding(adata, 'X_umap_bbknn', color="sample", title="BBKNN umap", ax=axs[1,0], show=False)
sc.pl.umap(adata, color="sample", title="Harmony umap", ax=axs[1,1], show=False)
Let’s save the integrated data for further analysis.
# Store this umap and tsne with a new name.
adata.obsm['X_umap_harmony'] = adata.obsm['X_umap']
adata.obsm['X_tsne_harmony'] = adata.obsm['X_tsne']
#save to file
save_file = './data/covid/results/scanpy_covid_qc_dr_harmony.h5ad'
adata.write_h5ad(save_file)5 Combat
Batch correction can also be performed with combat. Note that ComBat batch correction requires a dense matrix format as input (which is already the case in this example).
# create a new object with lognormalized counts
adata_combat = sc.AnnData(X=adata.raw.X, var=adata.raw.var, obs = adata.obs)
# first store the raw data
adata_combat.raw = adata_combat
# run combat
sc.pp.combat(adata_combat, key='sample')Standardizing Data across genes.
Found 8 batches
Found 0 numerical variables:
Found 39 genes with zero variance.
Fitting L/S model and finding priors
Finding parametric adjustments
Adjusting data
Then we run the regular steps of dimensionality reduction on the combat corrected data. Variable gene selection, pca and umap with combat data.
sc.pp.highly_variable_genes(adata_combat)
print("Highly variable genes: %d"%sum(adata_combat.var.highly_variable))
sc.pl.highly_variable_genes(adata_combat)
sc.pp.pca(adata_combat, n_comps=30, use_highly_variable=True, svd_solver='arpack', random_state=573)
sc.pp.neighbors(adata_combat, random_state=159)
sc.tl.umap(adata_combat, random_state=331)
sc.tl.tsne(adata_combat, random_state=75)extracting highly variable genes
finished (0:00:00)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
Highly variable genes: 3923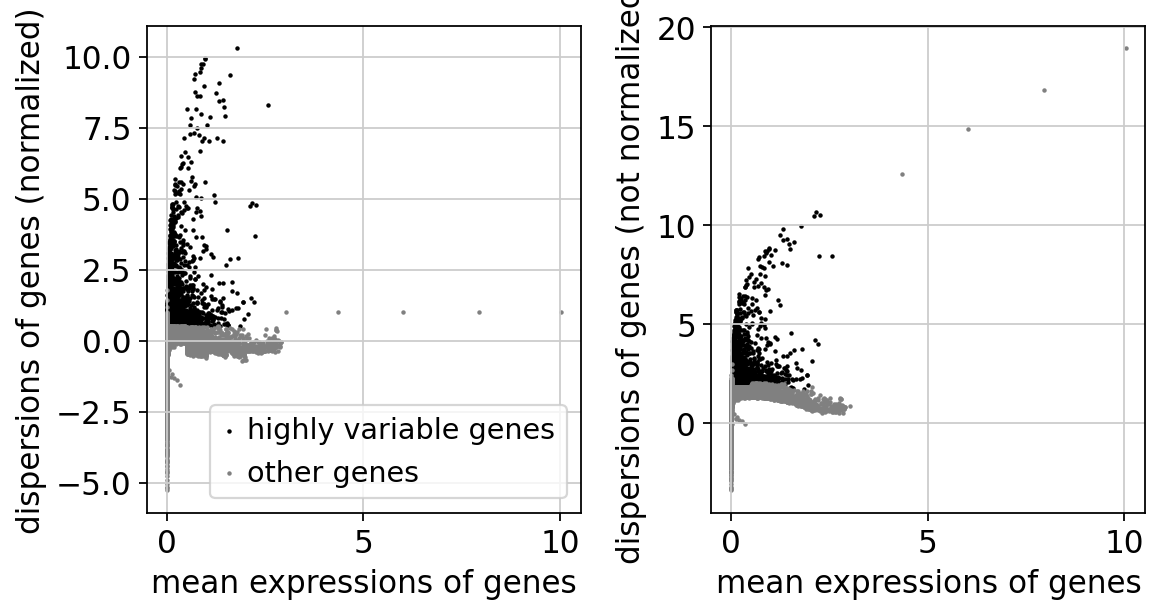
computing PCA
with n_comps=30
finished (0:00:01)
computing neighbors
using 'X_pca' with n_pcs = 30
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:00)
computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm)
'umap', UMAP parameters (adata.uns) (0:00:09)
computing tSNE
using 'X_pca' with n_pcs = 30
using sklearn.manifold.TSNE
finished: added
'X_tsne', tSNE coordinates (adata.obsm)
'tsne', tSNE parameters (adata.uns) (0:00:11)# compare var_genes
var_genes_combat = adata_combat.var.highly_variable
print("With all data %d"%sum(var_genes_all))
print("With combat %d"%sum(var_genes_combat))
print("Overlap %d"%sum(var_genes_all & var_genes_combat))
print("With 2 batches %d"%sum(var_select))
print("Overlap %d"%sum(var_genes_combat & var_select))With all data 2626
With combat 3923
Overlap 1984
With 2 batches 4268
Overlap 2729We can now plot the unintegrated and the integrated space reduced dimensions.
fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.tsne(adata, color="sample", title="Harmony tsne", ax=axs[0,0], show=False)
sc.pl.tsne(adata_combat, color="sample", title="Combat tsne", ax=axs[0,1], show=False)
sc.pl.umap(adata, color="sample", title="Harmony umap", ax=axs[1,0], show=False)
sc.pl.umap(adata_combat, color="sample", title="Combat umap", ax=axs[1,1], show=False)
Let’s save the integrated data for further analysis.
# Add the dimred to the other adata object
adata.obsm['X_umap_combat'] = adata_combat.obsm['X_umap']
adata.obsm['X_tsne_combat'] = adata_combat.obsm['X_tsne']
adata.obsm['X_pca_combat'] = adata_combat.obsm['X_pca']
#save to file
save_file = './data/covid/results/scanpy_covid_qc_dr_combat.h5ad'
adata_combat.write_h5ad(save_file)6 Scanorama
Try out Scanorama for data integration as well. First we need to create individual AnnData objects from each of the datasets.
OBS! There is a function sc.external.pp.scanorama_integrate implemented in the scanpy toolkit. However, it runs scanorama on the PCA embedding and does not give us nice results when we have tested it, so we are not using it here.
# split per batch into new objects.
batches = adata.obs['sample'].cat.categories.tolist()
alldata = {}
for batch in batches:
alldata[batch] = adata[adata.obs['sample'] == batch,]
alldata {'covid_1': View of AnnData object with n_obs × n_vars = 876 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances',
'covid_15': View of AnnData object with n_obs × n_vars = 591 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances',
'covid_16': View of AnnData object with n_obs × n_vars = 370 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances',
'covid_17': View of AnnData object with n_obs × n_vars = 1084 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances',
'ctrl_5': View of AnnData object with n_obs × n_vars = 1017 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances',
'ctrl_13': View of AnnData object with n_obs × n_vars = 1121 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances',
'ctrl_14': View of AnnData object with n_obs × n_vars = 1030 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances',
'ctrl_19': View of AnnData object with n_obs × n_vars = 1133 × 4268
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info', 'leiden'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'tsne', 'umap', 'leiden'
obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_umap_uncorr', 'X_tsne_uncorr', 'X_umap_bbknn', 'X_tsne_bbknn', 'X_pca_harmony', 'X_umap_harmony', 'X_tsne_harmony', 'X_umap_combat', 'X_tsne_combat', 'X_pca_combat'
varm: 'PCs'
obsp: 'connectivities', 'distances'}import scanorama
#subset the individual dataset to the variable genes we defined at the beginning
alldata2 = dict()
for ds in alldata.keys():
print(ds)
alldata2[ds] = alldata[ds][:,var_genes]
#convert to list of AnnData objects
adatas = list(alldata2.values())
# run scanorama.integrate
scanorama.integrate_scanpy(adatas, dimred = 50)covid_1
covid_15
covid_16
covid_17
ctrl_5
ctrl_13
ctrl_14
ctrl_19
Found 4268 genes among all datasets
[[0. 0.57021997 0.6027027 0.31642066 0.55251142 0.52054795
0.46917808 0.19064431]
[0. 0. 0.73773266 0.31472081 0.46411013 0.29780034
0.40270728 0.23350254]
[0. 0. 0. 0.24594595 0.48108108 0.57567568
0.48918919 0.28918919]
[0. 0. 0. 0. 0.28613569 0.12084871
0.17804428 0.24448367]
[0. 0. 0. 0. 0. 0.86627335
0.69714848 0.30008826]
[0. 0. 0. 0. 0. 0.
0.86797502 0.46248897]
[0. 0. 0. 0. 0. 0.
0. 0.83053839]
[0. 0. 0. 0. 0. 0.
0. 0. ]]
Processing datasets (5, 6)
Processing datasets (4, 5)
Processing datasets (6, 7)
Processing datasets (1, 2)
Processing datasets (4, 6)
Processing datasets (0, 2)
Processing datasets (2, 5)
Processing datasets (0, 1)
Processing datasets (0, 4)
Processing datasets (0, 5)
Processing datasets (2, 6)
Processing datasets (2, 4)
Processing datasets (0, 6)
Processing datasets (1, 4)
Processing datasets (5, 7)
Processing datasets (1, 6)
Processing datasets (0, 3)
Processing datasets (1, 3)
Processing datasets (4, 7)
Processing datasets (1, 5)
Processing datasets (2, 7)
Processing datasets (3, 4)
Processing datasets (2, 3)
Processing datasets (3, 7)
Processing datasets (1, 7)
Processing datasets (0, 7)
Processing datasets (3, 6)
Processing datasets (3, 5)#scanorama adds the corrected matrix to adata.obsm in each of the datasets in adatas.
adatas[0].obsm['X_scanorama'].shape(876, 50)# Get all the integrated matrices.
scanorama_int = [ad.obsm['X_scanorama'] for ad in adatas]
# make into one matrix.
all_s = np.concatenate(scanorama_int)
print(all_s.shape)
# add to the AnnData object, create a new object first
adata.obsm["Scanorama"] = all_s(7222, 50)# tsne and umap
sc.pp.neighbors(adata, n_pcs =30, use_rep = "Scanorama", random_state=159)
sc.tl.umap(adata, random_state=331)
sc.tl.tsne(adata, n_pcs = 30, use_rep = "Scanorama", random_state=75)computing neighbors
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:00)
computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm)
'umap', UMAP parameters (adata.uns) (0:00:08)
computing tSNE
using sklearn.manifold.TSNE
finished: added
'X_tsne', tSNE coordinates (adata.obsm)
'tsne', tSNE parameters (adata.uns) (0:00:11)We can now plot the unintegrated and the integrated space reduced dimensions.
fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.embedding(adata, 'X_tsne_harmony', color="sample", title="Harmony tsne", ax=axs[0,0], show=False)
sc.pl.tsne(adata, color="sample", title="Scanorama tsne", ax=axs[0,1], show=False)
sc.pl.embedding(adata, 'X_umap_harmony', color="sample", title="Harmony umap", ax=axs[1,0], show=False)
sc.pl.umap(adata, color="sample", title="Scanorama umap", ax=axs[1,1], show=False)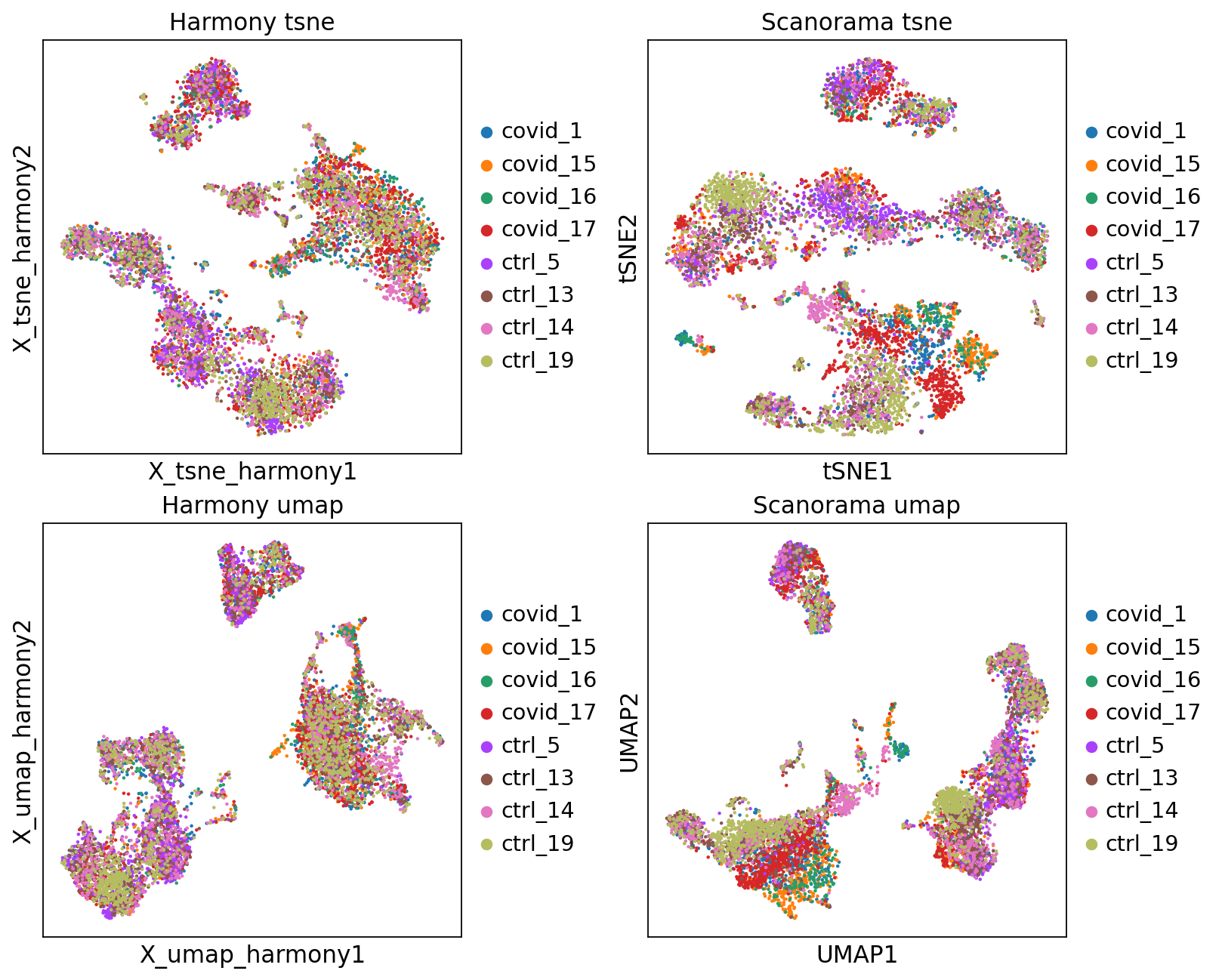
Let’s save the integrated data for further analysis.
# Store this umap and tsne with a new name.
adata.obsm['X_umap_scanorama'] = adata.obsm['X_umap']
adata.obsm['X_tsne_scanorama'] = adata.obsm['X_tsne']
#save to file, now contains all integrations except the combat one.
save_file = './data/covid/results/scanpy_covid_qc_dr_int.h5ad'
adata.write_h5ad(save_file)7 Overview all methods
Now we will plot UMAPS with all three integration methods side by side.
fig, axs = plt.subplots(2, 3, figsize=(10,8),constrained_layout=True)
sc.pl.embedding(adata, 'X_umap_uncorr', color="sample", title="Uncorrected", ax=axs[0,0], show=False)
sc.pl.embedding(adata, 'X_umap_bbknn', color="sample", title="BBKNN", ax=axs[0,1], show=False)
sc.pl.umap(adata_combat, color="sample", title="Combat", ax=axs[0,2], show=False)
sc.pl.embedding(adata, 'X_umap_harmony', color="sample", title="Harmony", ax=axs[1,0], show=False)
sc.pl.umap(adata, color="sample", title="Scanorama", ax=axs[1,1], show=False)
NoteDiscuss
Look at the different integration results, which one do you think looks the best? How would you motivate selecting one method over the other? How do you think you could best evaluate if the integration worked well?
8 Extra task
Have a look at the documentation for BBKNN
Try changing some of the parameteres in BBKNN, such as distance metric, number of PCs and number of neighbors. How does the results change with different parameters? Can you explain why?
9 Session info
Click here
sc.logging.print_versions()Dependencies
| Dependency | Version |
|---|---|
| joblib | 1.5.3 |
| torch | 2.10.0 |
| PyYAML | 6.0.3 |
| annoy | 1.17.3 |
| igraph | 1.0.0 |
| llvmlite | 0.46.0 |
| intervaltree | 3.1.0 |
| natsort | 8.4.0 |
| comm | 0.2.3 |
| sparse | 0.18.0 |
| google-crc32c | 1.8.0 |
| pynndescent | 0.5.13 |
| texttable | 1.7.0 |
| sortedcontainers | 2.4.0 |
| h5py | 3.15.1 |
| fbpca | 1.0 |
| decorator | 5.2.1 |
| traitlets | 5.14.3 |
| stack_data | 0.6.3 |
| tqdm | 4.67.3 |
| tornado | 6.5.3 |
| parso | 0.8.6 |
| pytz | 2025.2 |
| msgpack | 1.1.2 |
| pyparsing | 3.3.2 |
| threadpoolctl | 3.6.0 |
| matplotlib-inline | 0.2.1 |
| cycler | 0.12.1 |
| setuptools | 82.0.0 |
| session-info2 | 0.4 |
| donfig | 0.8.1.post1 |
| zarr | 3.1.5 |
| six | 1.17.0 |
| bbknn | 1.6.0 |
| jupyter_core | 5.9.1 |
| pure_eval | 0.2.3 |
| patsy | 1.0.2 |
| kiwisolver | 1.4.9 |
| executing | 2.2.1 |
| wcwidth | 0.6.0 |
| typing_extensions | 4.15.0 |
| scikit-learn | 1.6.1 |
| ipykernel | 7.2.0 |
| pillow | 12.1.1 |
| platformdirs | 4.9.2 |
| packaging | 26.0 |
| debugpy | 1.8.20 |
| scipy | 1.16.3 |
| leidenalg | 0.11.0 |
| psutil | 7.2.2 |
| charset-normalizer | 3.4.4 |
| numcodecs | 0.16.5 |
| python-dateutil | 2.9.0.post0 |
| ipython | 9.10.0 |
| umap-learn | 0.5.11 |
| pyzmq | 27.1.0 |
| legacy-api-wrap | 1.5 |
| asttokens | 3.0.1 |
| prompt_toolkit | 3.0.52 |
| jedi | 0.19.2 |
| numba | 0.63.1 |
| jupyter_client | 8.8.0 |
| xarray | 2026.2.0 |
| opt_einsum | 3.4.0 |
| fast-array-utils | 1.3.1 |
| backports.zstd | 1.3.0 |
| Pygments | 2.19.2 |
| fsspec | 2026.2.0 |
Copyable Markdown
| Package | Version | | ---------- | ------- | | numpy | 2.3.5 | | pandas | 2.3.3 | | scanpy | 1.12 | | matplotlib | 3.10.8 | | anndata | 0.12.10 | | harmonypy | 0.2.0 | | scanorama | 1.7.4 | | Dependency | Version | | ------------------ | ----------- | | joblib | 1.5.3 | | torch | 2.10.0 | | PyYAML | 6.0.3 | | annoy | 1.17.3 | | igraph | 1.0.0 | | llvmlite | 0.46.0 | | intervaltree | 3.1.0 | | natsort | 8.4.0 | | comm | 0.2.3 | | sparse | 0.18.0 | | google-crc32c | 1.8.0 | | pynndescent | 0.5.13 | | texttable | 1.7.0 | | sortedcontainers | 2.4.0 | | h5py | 3.15.1 | | fbpca | 1.0 | | decorator | 5.2.1 | | traitlets | 5.14.3 | | stack_data | 0.6.3 | | tqdm | 4.67.3 | | tornado | 6.5.3 | | parso | 0.8.6 | | pytz | 2025.2 | | msgpack | 1.1.2 | | pyparsing | 3.3.2 | | threadpoolctl | 3.6.0 | | matplotlib-inline | 0.2.1 | | cycler | 0.12.1 | | setuptools | 82.0.0 | | session-info2 | 0.4 | | donfig | 0.8.1.post1 | | zarr | 3.1.5 | | six | 1.17.0 | | bbknn | 1.6.0 | | jupyter_core | 5.9.1 | | pure_eval | 0.2.3 | | patsy | 1.0.2 | | kiwisolver | 1.4.9 | | executing | 2.2.1 | | wcwidth | 0.6.0 | | typing_extensions | 4.15.0 | | scikit-learn | 1.6.1 | | ipykernel | 7.2.0 | | pillow | 12.1.1 | | platformdirs | 4.9.2 | | packaging | 26.0 | | debugpy | 1.8.20 | | scipy | 1.16.3 | | leidenalg | 0.11.0 | | psutil | 7.2.2 | | charset-normalizer | 3.4.4 | | numcodecs | 0.16.5 | | python-dateutil | 2.9.0.post0 | | ipython | 9.10.0 | | umap-learn | 0.5.11 | | pyzmq | 27.1.0 | | legacy-api-wrap | 1.5 | | asttokens | 3.0.1 | | prompt_toolkit | 3.0.52 | | jedi | 0.19.2 | | numba | 0.63.1 | | jupyter_client | 8.8.0 | | xarray | 2026.2.0 | | opt_einsum | 3.4.0 | | fast-array-utils | 1.3.1 | | backports.zstd | 1.3.0 | | Pygments | 2.19.2 | | fsspec | 2026.2.0 | | Component | Info | | --------- | ------------------------------------------------------------------------------ | | Python | 3.12.12 | packaged by conda-forge | (main, Jan 26 2026, 23:51:32) [GCC 14.3.0] | | OS | Linux-6.12.5-linuxkit-x86_64-with-glibc2.35 | | CPU | 16 logical CPU cores, x86_64 | | GPU | No GPU found | | Updated | 2026-04-17 10:23 |