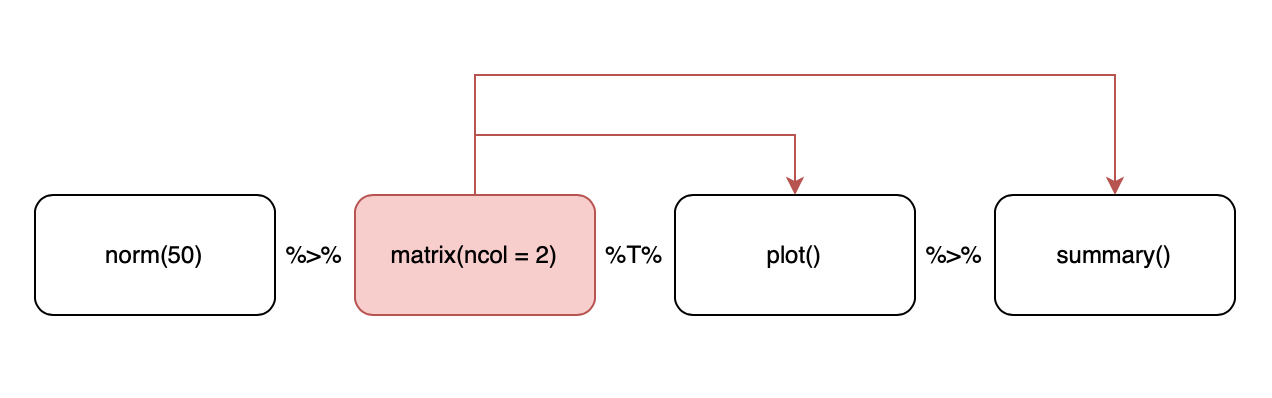
Sometimes we want to pass the resulting data to other than the first argument of the next function in chain. magritter provides placeholder mechanism for this:
[1] mountains <NA> seaside swamps
attr(,"problems")
# A tibble: 1 × 4
row col expected actual
<int> <int> <chr> <chr>
1 2 NA value in level set plains
Levels: mountains swamps seaside
Other Parsing Functions
parse_
vector, time, number, logical, integer, double, character, date, datetime,
# A tibble: 4 × 5
color clarity x y z
<ord> <ord> <dbl> <dbl> <dbl>
1 E SI2 3.95 3.98 2.43
2 E SI1 3.89 3.84 2.31
3 E VS1 4.05 4.07 2.31
4 I VS2 4.2 4.23 2.63
bijou %>%select(-(x:z)) %>%head(n =5)
# A tibble: 5 × 7
carat cut color clarity depth table price
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int>
1 0.23 Ideal E SI2 61.5 55 326
2 0.21 Premium E SI1 59.8 61 326
3 0.23 Good E VS1 56.9 65 327
4 0.29 Premium I VS2 62.4 58 334
5 0.31 Good J SI2 63.3 58 335
Renaming variables
Note
rename is a variant of select, here used with everything() to move x to the beginning and rename it to var_x
bijou %>%rename(var_x = x) %>%head(n =2)
# A tibble: 2 × 10
carat cut color clarity depth table price var_x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
Bring columns to front
Tip
use everything() to bring some columns to the front
bijou %>%select(x:z, everything()) %>%head(n =2)
# A tibble: 2 × 10
x y z carat cut color clarity depth table price
<dbl> <dbl> <dbl> <dbl> <ord> <ord> <ord> <dbl> <dbl> <int>
1 3.95 3.98 2.43 0.23 Ideal E SI2 61.5 55 326
2 3.89 3.84 2.31 0.21 Premium E SI1 59.8 61 326
Create/alter new Variables with mutate
bijou %>%mutate(p = x + z, q = p + y) %>%select(-(depth:price)) %>%head(n =5)
# A tibble: 5 × 9
carat cut color clarity x y z p q
<dbl> <ord> <ord> <ord> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 3.95 3.98 2.43 6.38 10.4
2 0.21 Premium E SI1 3.89 3.84 2.31 6.2 10.0
3 0.23 Good E VS1 4.05 4.07 2.31 6.36 10.4
4 0.29 Premium I VS2 4.2 4.23 2.63 6.83 11.1
5 0.31 Good J SI2 4.34 4.35 2.75 7.09 11.4
Create/alter new Variables with transmute 🧙♂️
Caution
Only the transformed variables will be retained.
bijou %>%transmute(carat, cut, sum = x + y + z) %>%head(n =5)
# A tibble: 5 × 3
carat cut sum
<dbl> <ord> <dbl>
1 0.23 Ideal 10.4
2 0.21 Premium 10.0
3 0.23 Good 10.4
4 0.29 Premium 11.1
5 0.31 Good 11.4
# A tibble: 2 × 6
cut price clarity x y z
<ord> <int> <ord> <dbl> <dbl> <dbl>
1 Ideal 326 SI2 3.95 3.98 2.43
2 Premium 326 SI1 3.89 3.84 2.31
Note
Here, sep is here interpreted as the position to split on. It can also be a regular expression or a delimiting string/character. Pretty flexible approach!
Tidying Data with unite
If some of your columns contain more than one value
# A tibble: 5 × 7
cut price clarity_prefix clarity_suffix x y z
<ord> <int> <chr> <chr> <dbl> <dbl> <dbl>
1 Ideal 326 SI 2 3.95 3.98 2.43
2 Premium 326 SI 1 3.89 3.84 2.31
3 Good 327 VS 1 4.05 4.07 2.31
4 Premium 334 VS 2 4.2 4.23 2.63
5 Good 335 SI 2 4.34 4.35 2.75
# A tibble: 7 × 4
cut continent clarity price
<ord> <chr> <ord> <int>
1 Fair Aus <NA> NA
2 Fair Eur <NA> NA
3 Good Aus VS1 327
4 Good Eur SI2 335
5 Very Good Aus VVS2 336
6 Very Good Eur <NA> NA
7 Premium Aus SI1 326
Combining Datasets
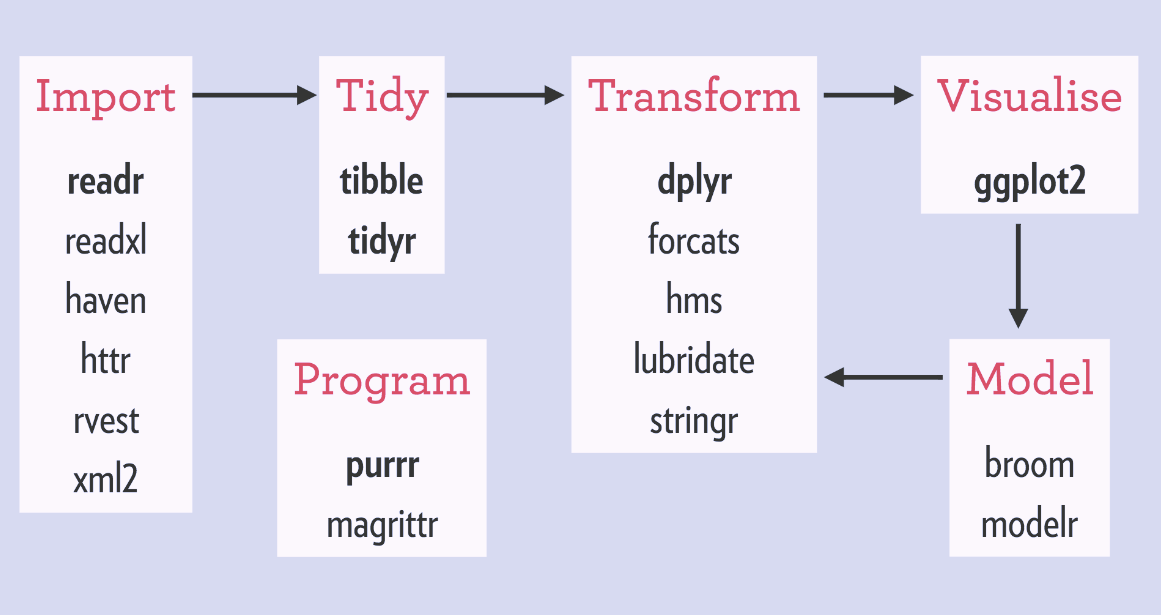
Often, we need to combine a number of data tables (relational data) to get the full picture of the data. Here different types of joins come to help:
mutating joins that add new variables to data table A based on matching observations (rows) from data table B
filtering joins that filter observations from data table A based on whether they match observations in data table B
set operations that treat observations in A and B as elements of a set.
Let us create two example tibbles that share a key:
key
x
a
A1
b
A2
c
A3
e
A4
key
y
a
B1
b
NA
c
B3
d
B4
The Joins Family — inner_join
key
x
a
A1
b
A2
c
A3
e
A4
key
y
a
B1
b
NA
c
B3
d
B4
A %>%inner_join(B, by ='key')# All non-matching rows are dropped!
# A tibble: 3 × 3
key x y
<chr> <chr> <chr>
1 a A1 B1
2 b A2 <NA>
3 c A3 B3
The Joins Family — left_join
key
x
a
A1
b
A2
c
A3
e
A4
key
y
a
B1
b
NA
c
B3
d
B4
A %>%left_join(B, by ='key')
# A tibble: 4 × 3
key x y
<chr> <chr> <chr>
1 a A1 B1
2 b A2 <NA>
3 c A3 B3
4 e A4 <NA>
The Joins Family — right_join
key
x
a
A1
b
A2
c
A3
e
A4
key
y
a
B1
b
NA
c
B3
d
B4
A %>%right_join(B, by ='key')
# A tibble: 4 × 3
key x y
<chr> <chr> <chr>
1 a A1 B1
2 b A2 <NA>
3 c A3 B3
4 d <NA> B4
The Joins Family — full_join
key
x
a
A1
b
A2
c
A3
e
A4
key
y
a
B1
b
NA
c
B3
d
B4
A %>%full_join(B, by ='key')
# A tibble: 5 × 3
key x y
<chr> <chr> <chr>
1 a A1 B1
2 b A2 <NA>
3 c A3 B3
4 e A4 <NA>
5 d <NA> B4
Some Other Friends
stringr for string manipulation and regular expressions
forcats for working with factors
lubridate for working with dates
Thank you! Questions?
_
platform x86_64-pc-linux-gnu
os linux-gnu
major 4
minor 3.2





{kind=link}