Debugging, Profiling, and a Bit of Optimization
RaukR 2024 • Advanced R for Bioinformatics
21-Jun-2024
Run Forrest, run!
- My code does not run! – debugging
- Now it does run but… out of memory! – profiling
- It runs! It says it will finish in 5
minutesyears. – optimization

Handling Errors
Let us generate some errors:
input <- c(1, 10, -7, -2/5, 0, 'char', 100, pi, NaN)
for (val in input) {
(paste0('Log of ', val, 'is ', log10(val)))
}Error in log10(val): non-numeric argument to mathematical function
So, how to handle this mess?
Option 3: step-by-step debugging

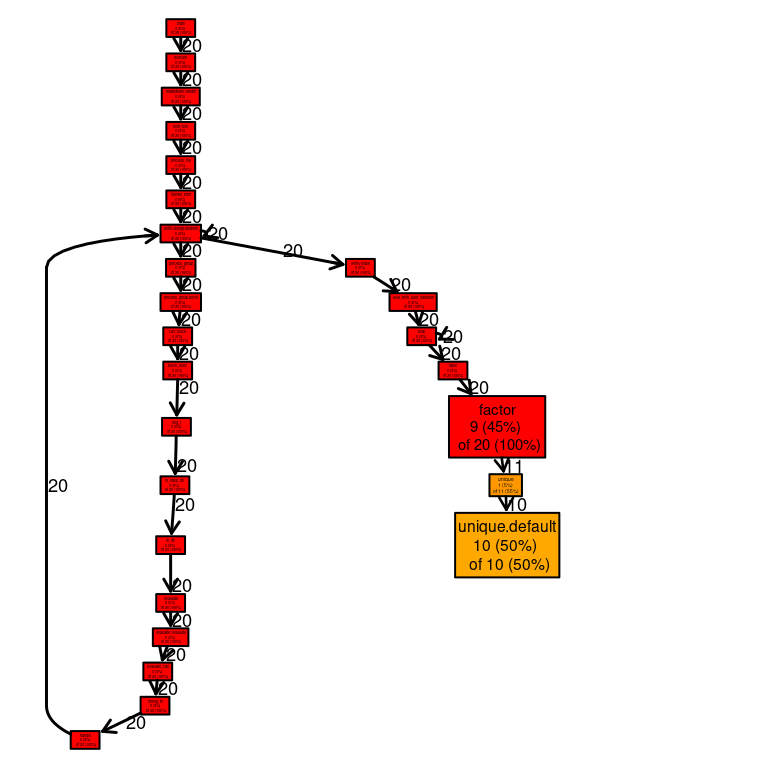
Profiling – profr package cted.
We can also plot the results using – proftools package-
Optimizing your code
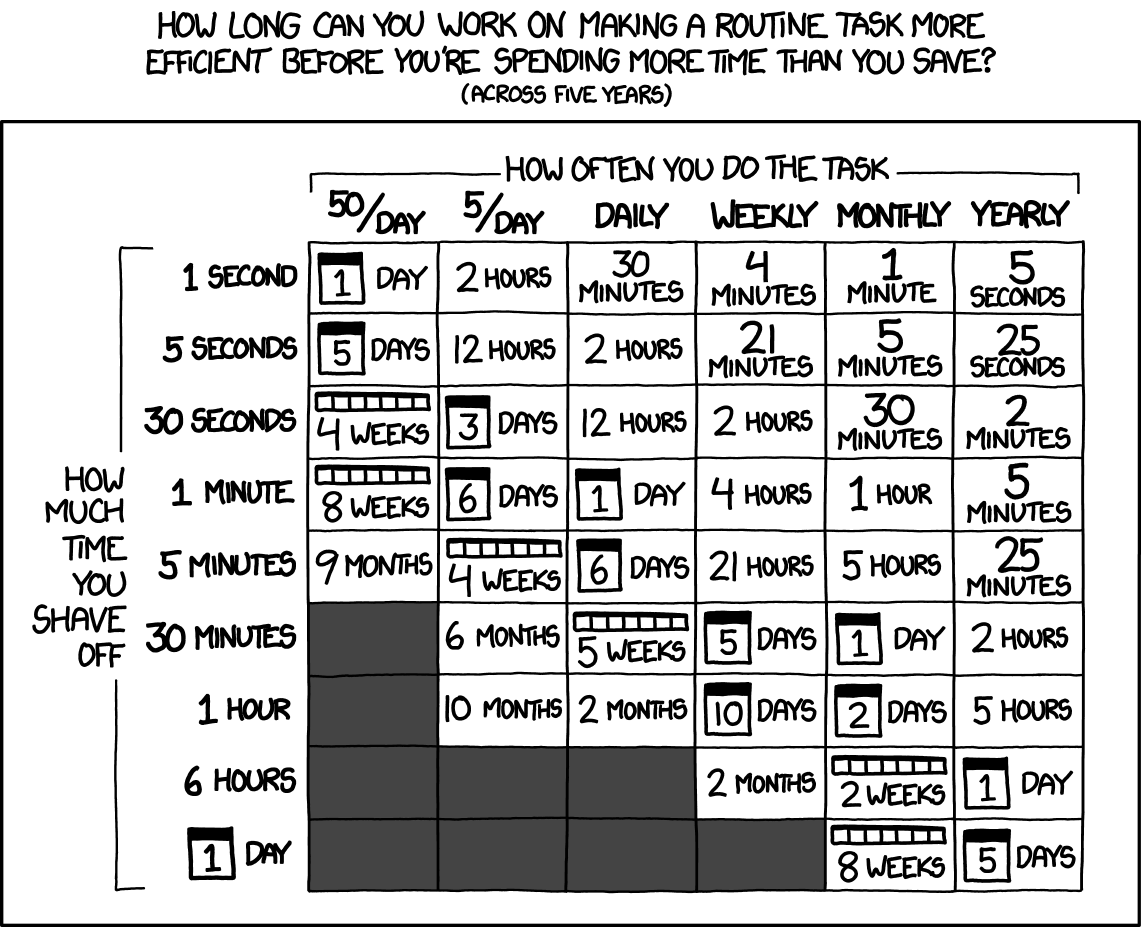
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be deluded into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified.
– Donald Knuth

source: http://www.xkcd/com/1319
source: http://www.xkcd/com/1205
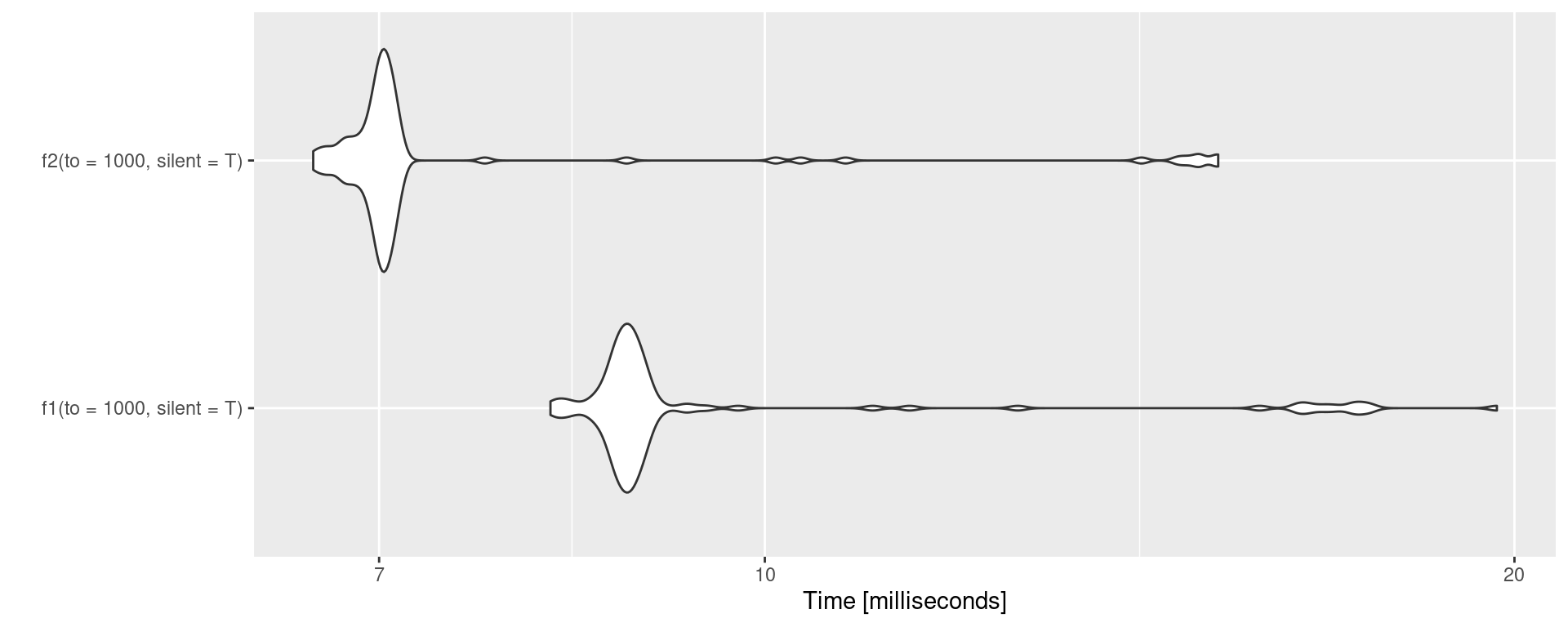
Allocating memory – benchmark.
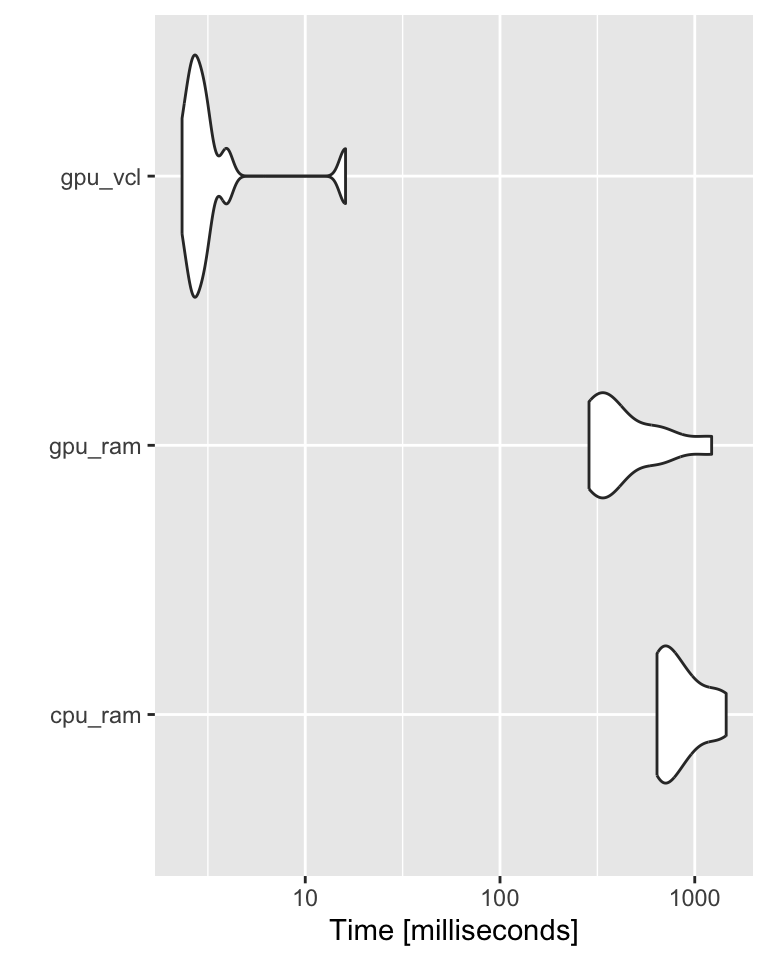
GPU cted.
Thank you! Questions?
_
platform x86_64-pc-linux-gnu
os linux-gnu
major 4
minor 3.2 2024 • SciLifeLab • NBIS • RaukR

