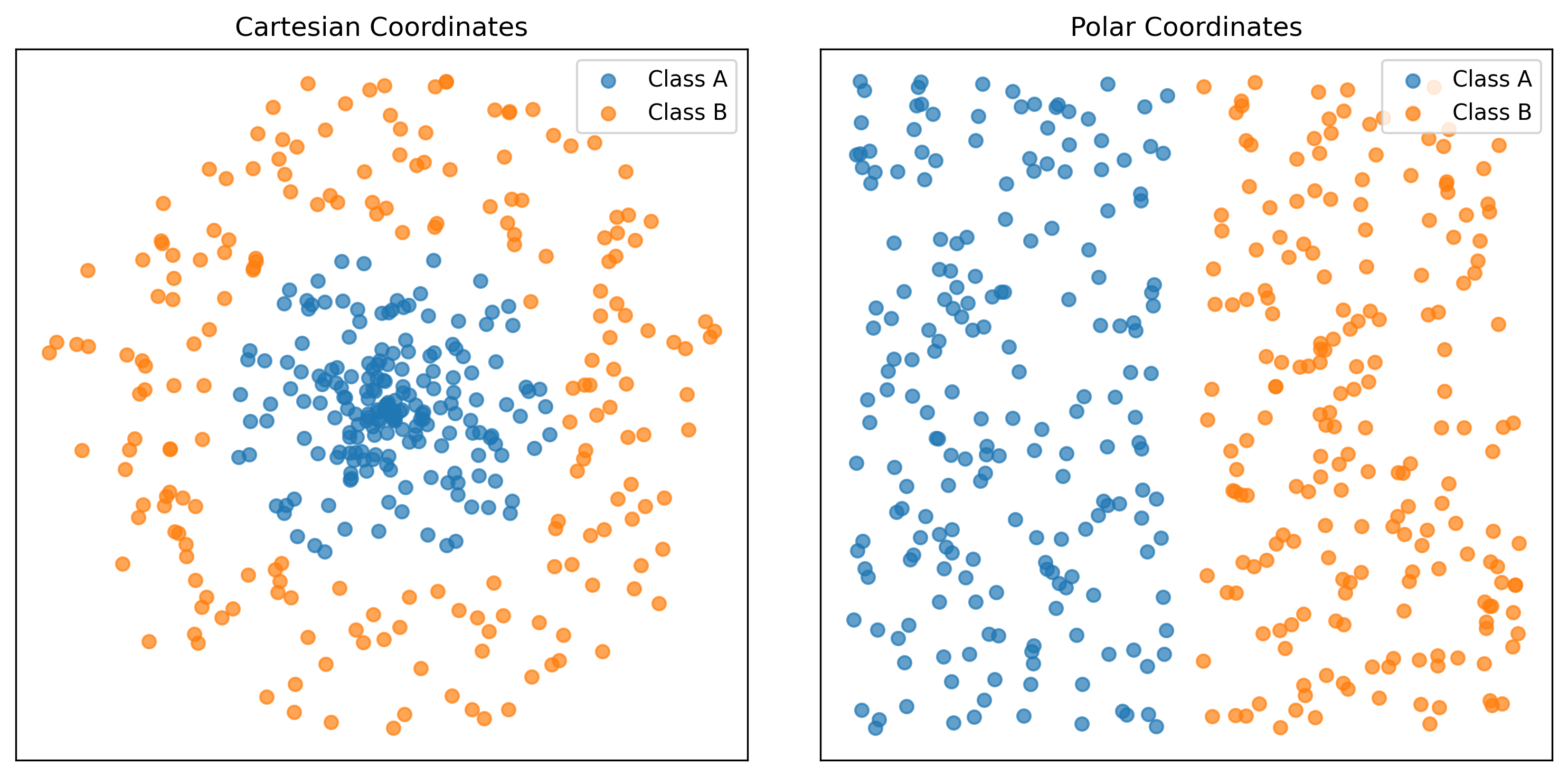
Dot product is directly connected to the angle (alignment) between vectors
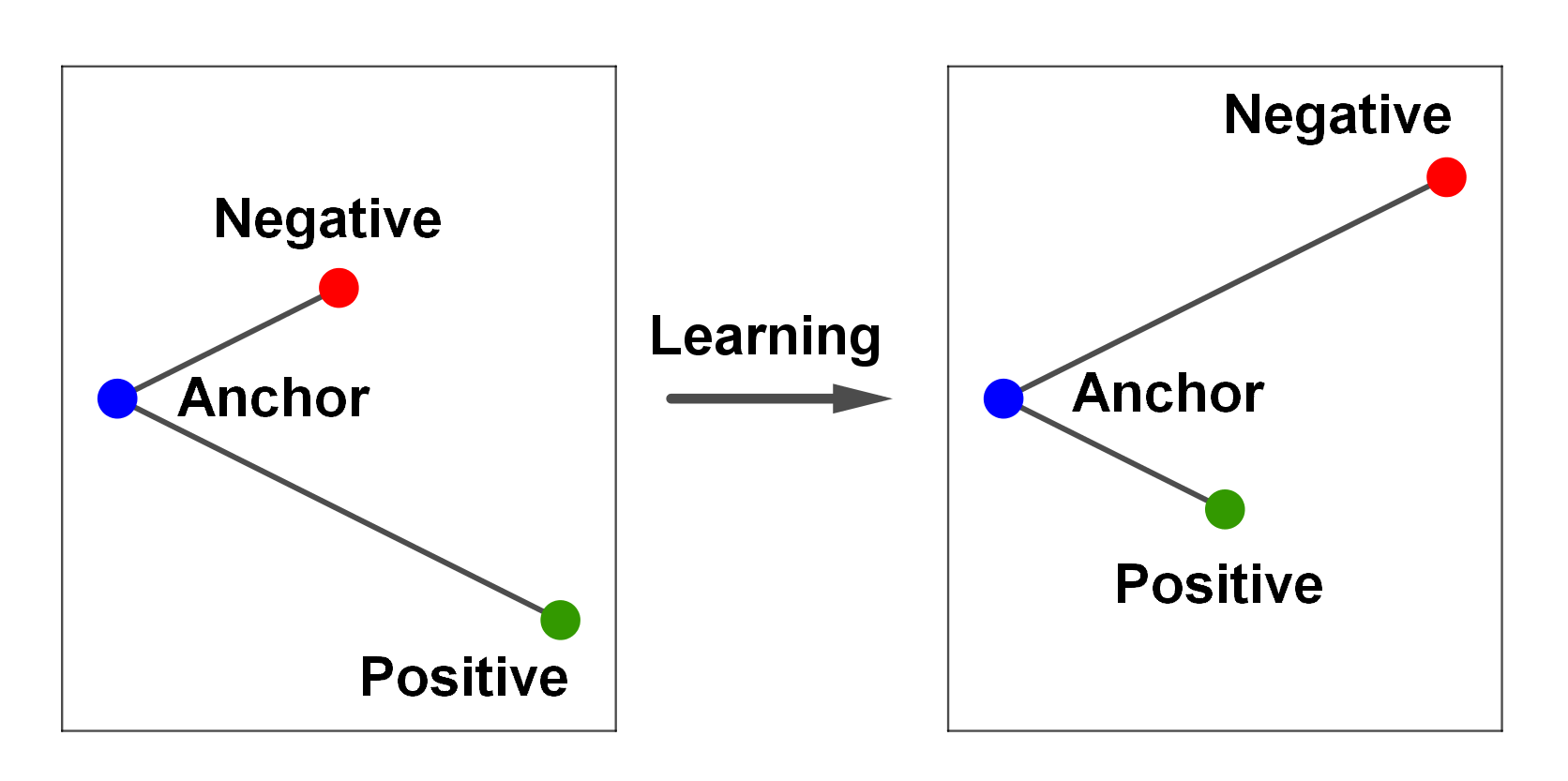
Neural Network learns by aligning vectors
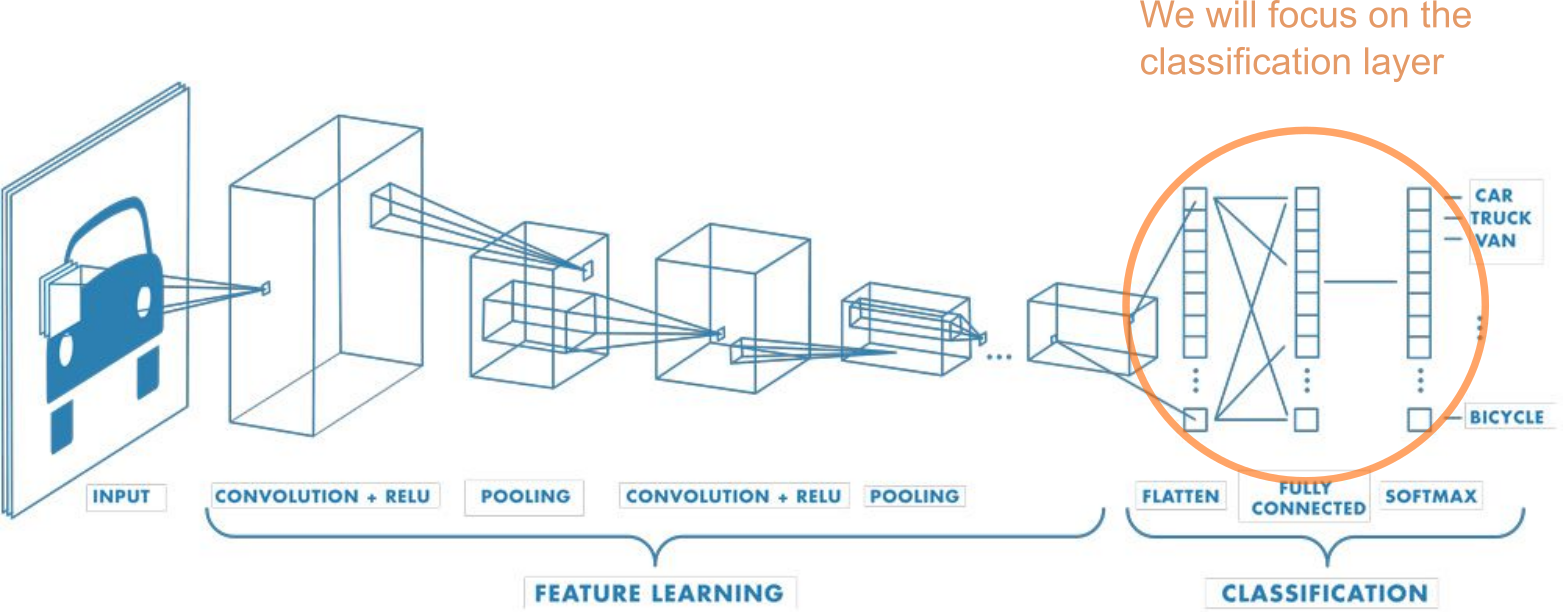
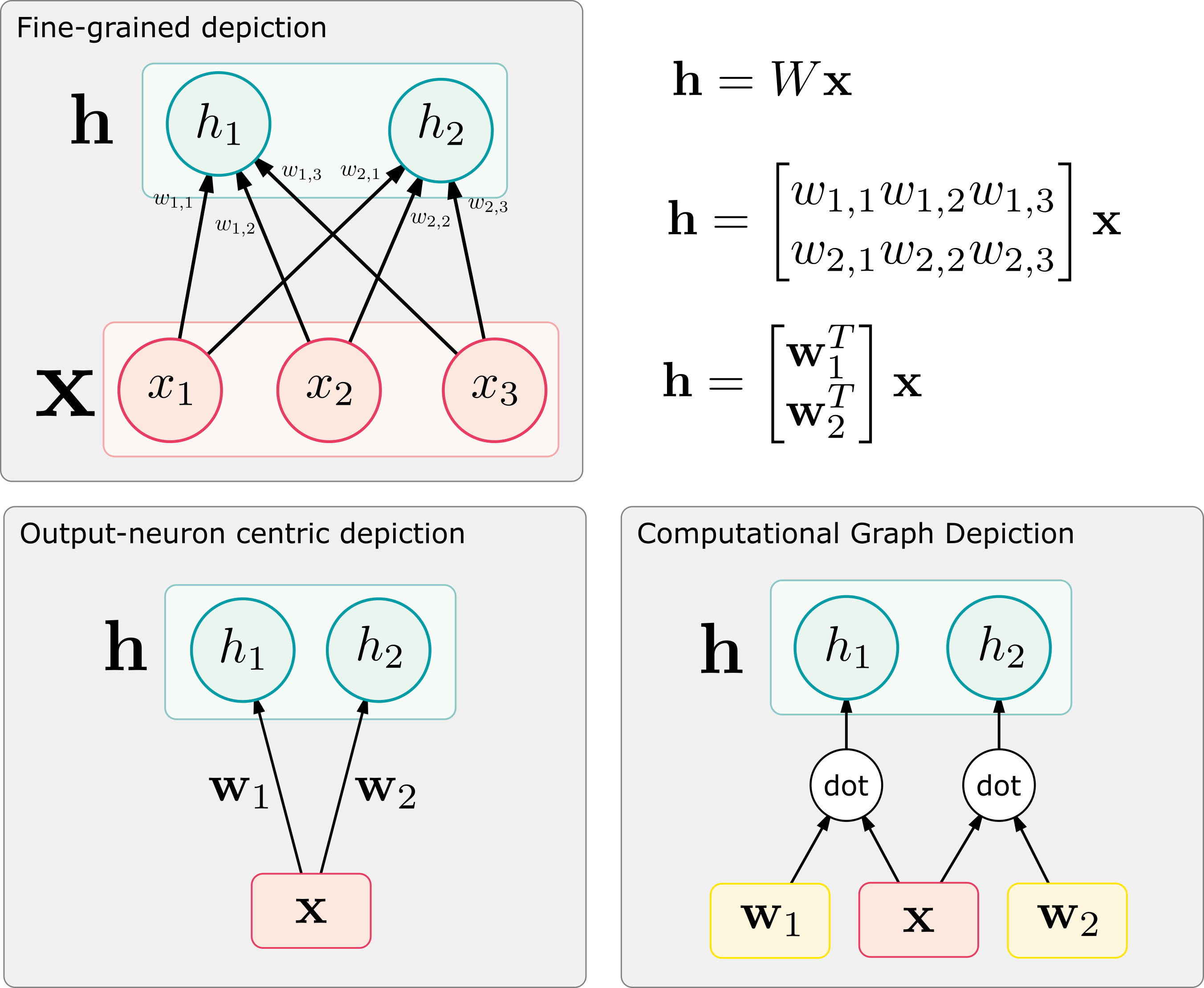
Graphical representations of neural networks
Different graphical representations of neural networks
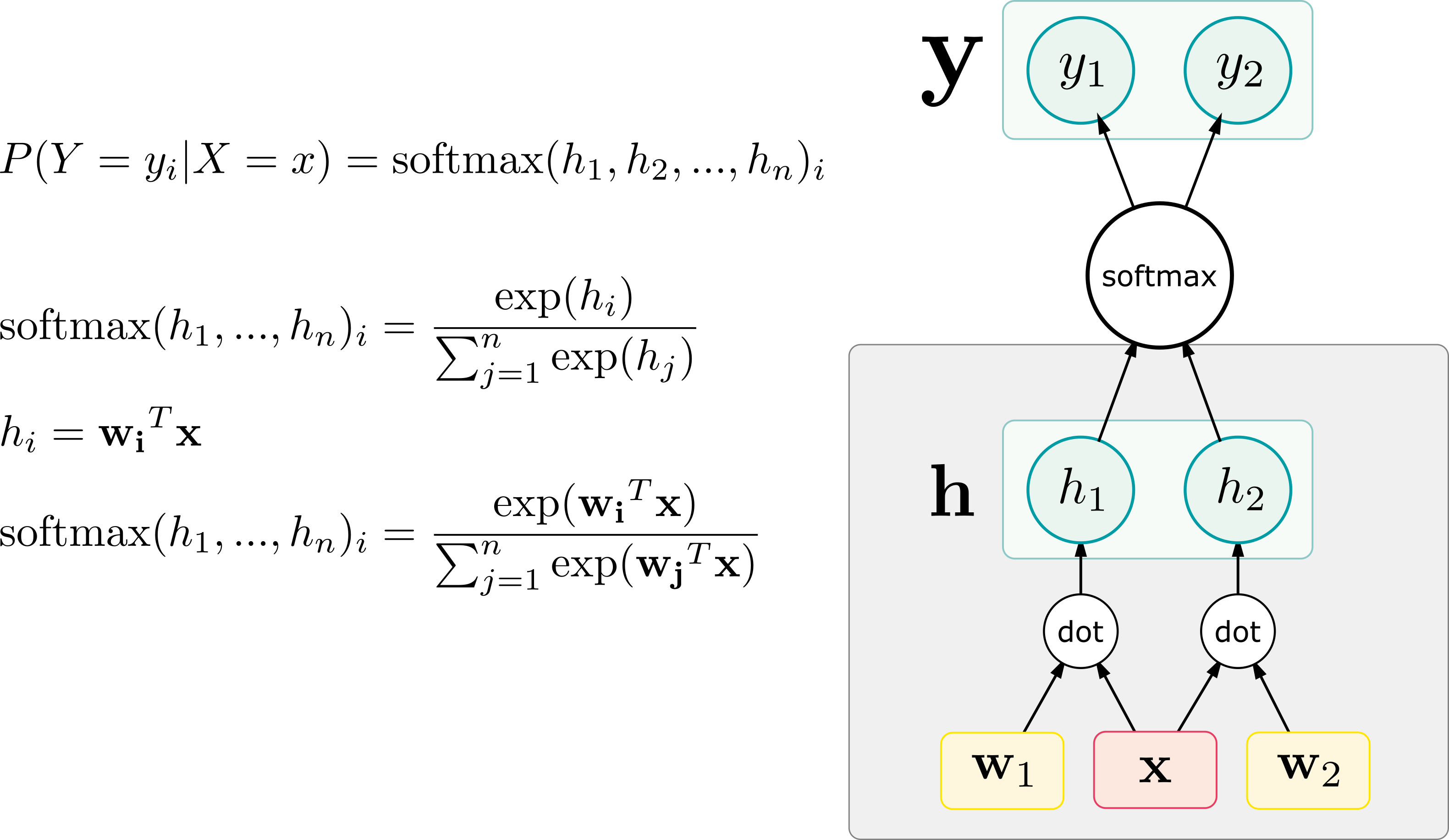
Graphically representing softmax
Computational graph view of softmax
Graphically representing softmax
Computational graph view of softmax
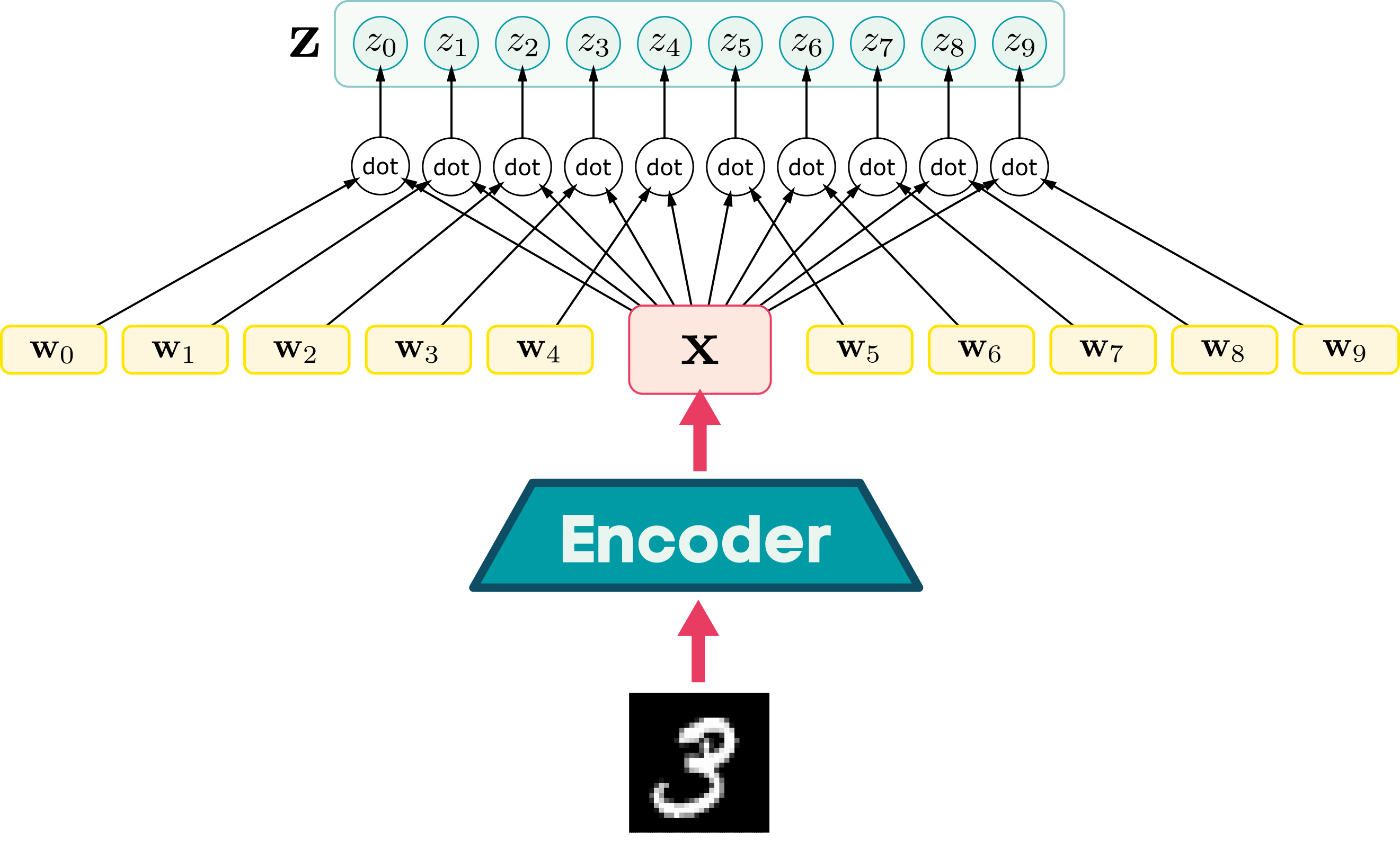
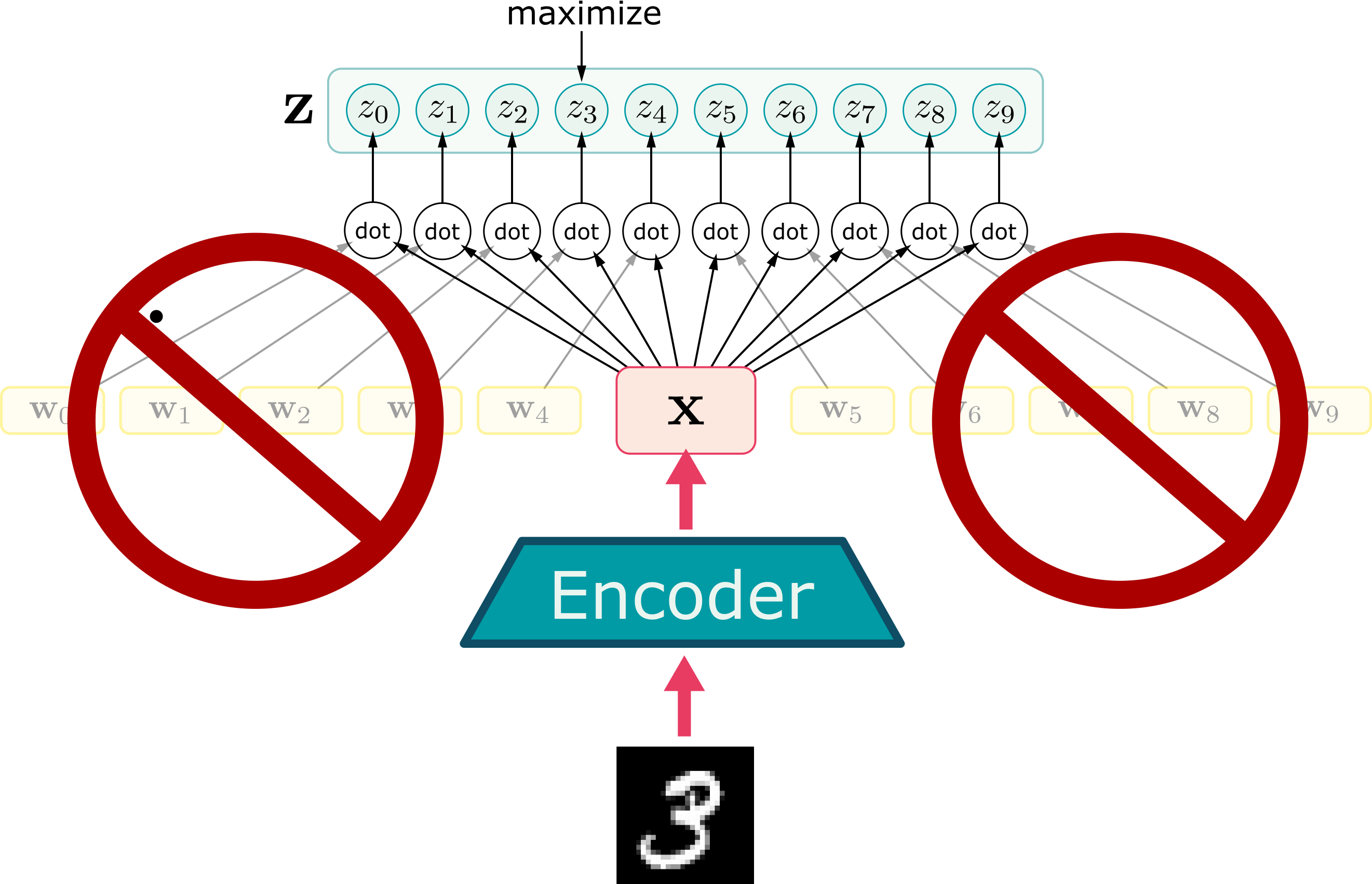
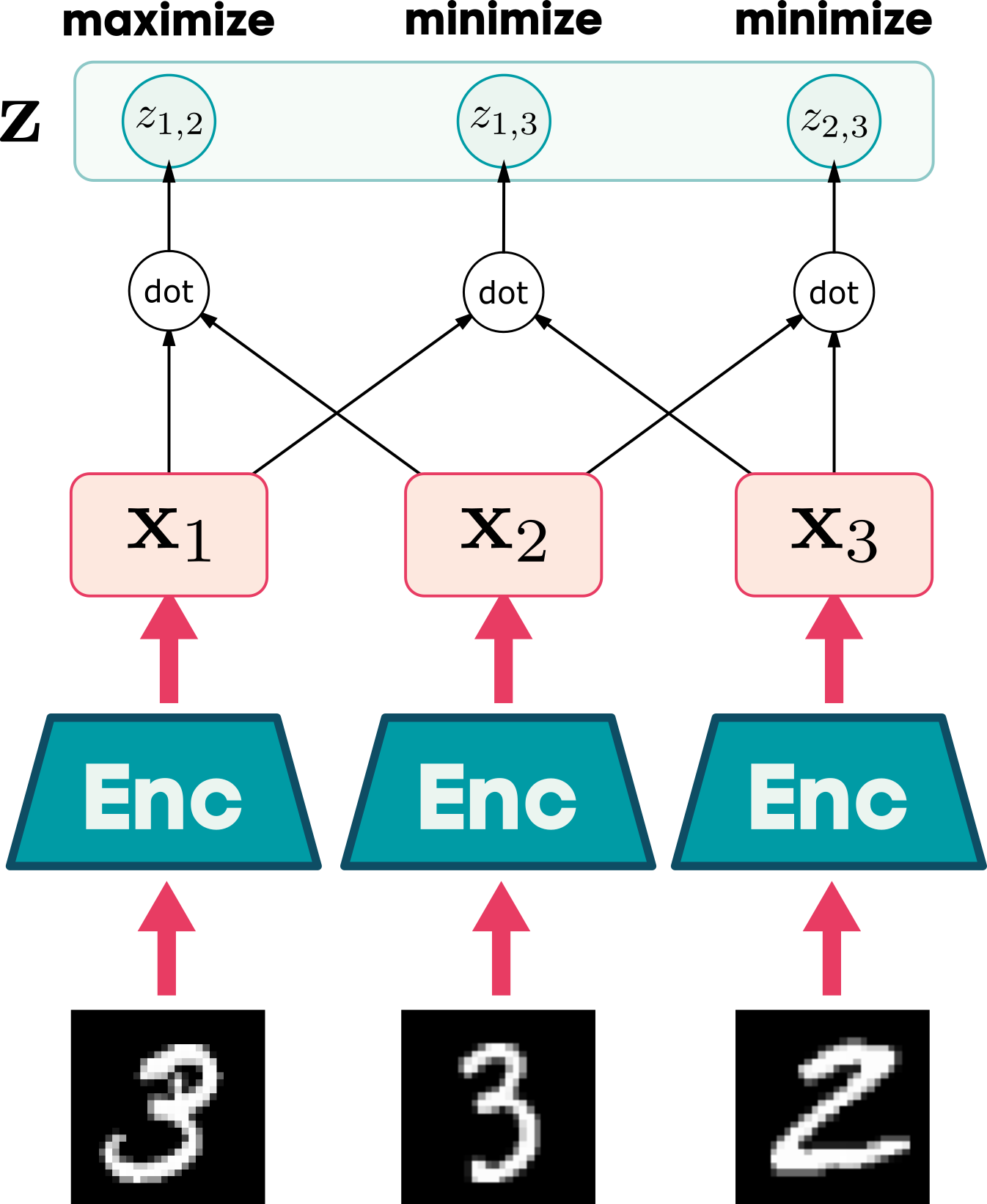
MNIST example
Softmax angle alignment
Computational graph view of softmax
Contrastive learning
Using computed “softmax” weights
No fixed “class” vectors
Embeddings of other examples act as the “class” vectors
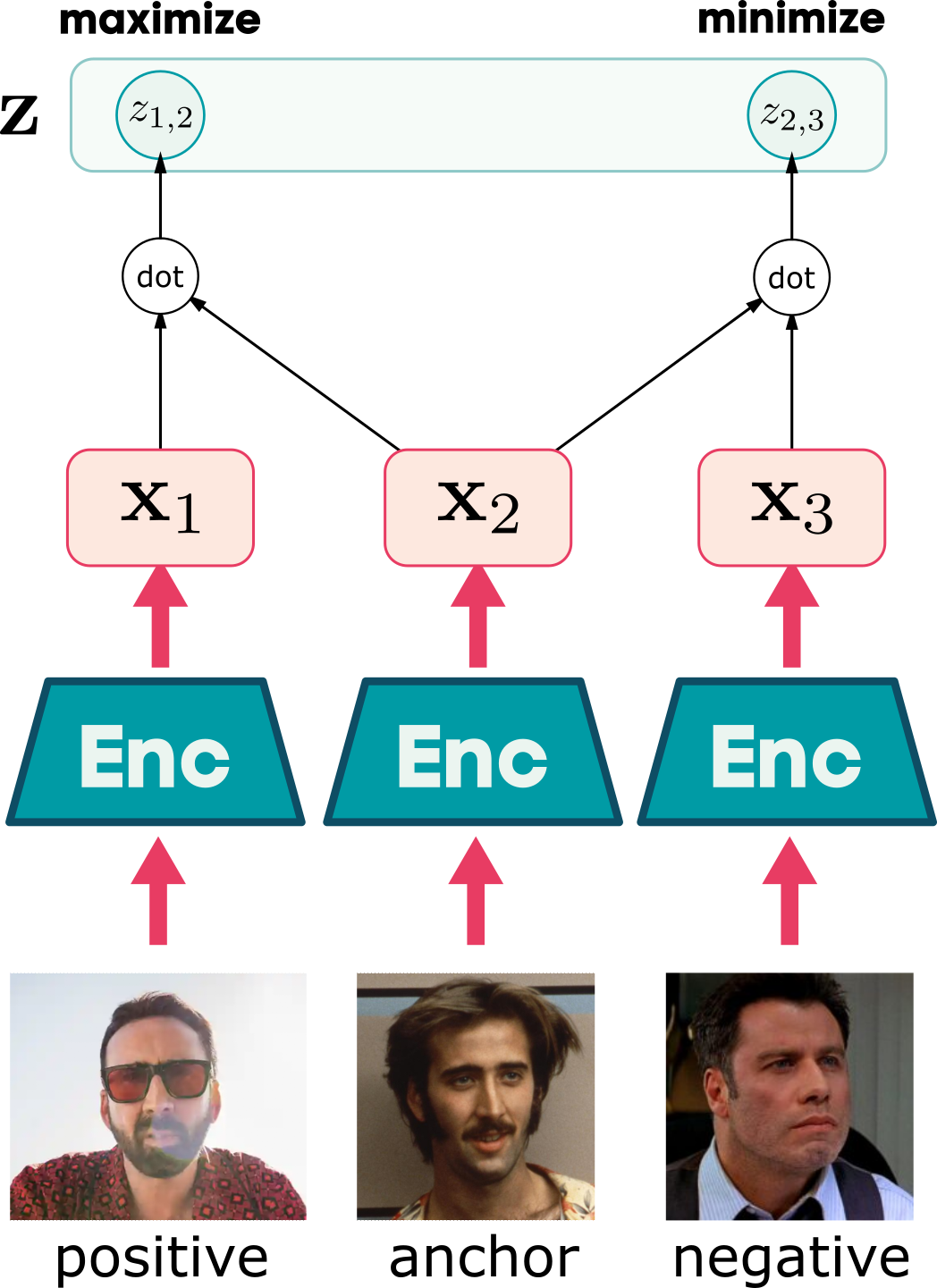
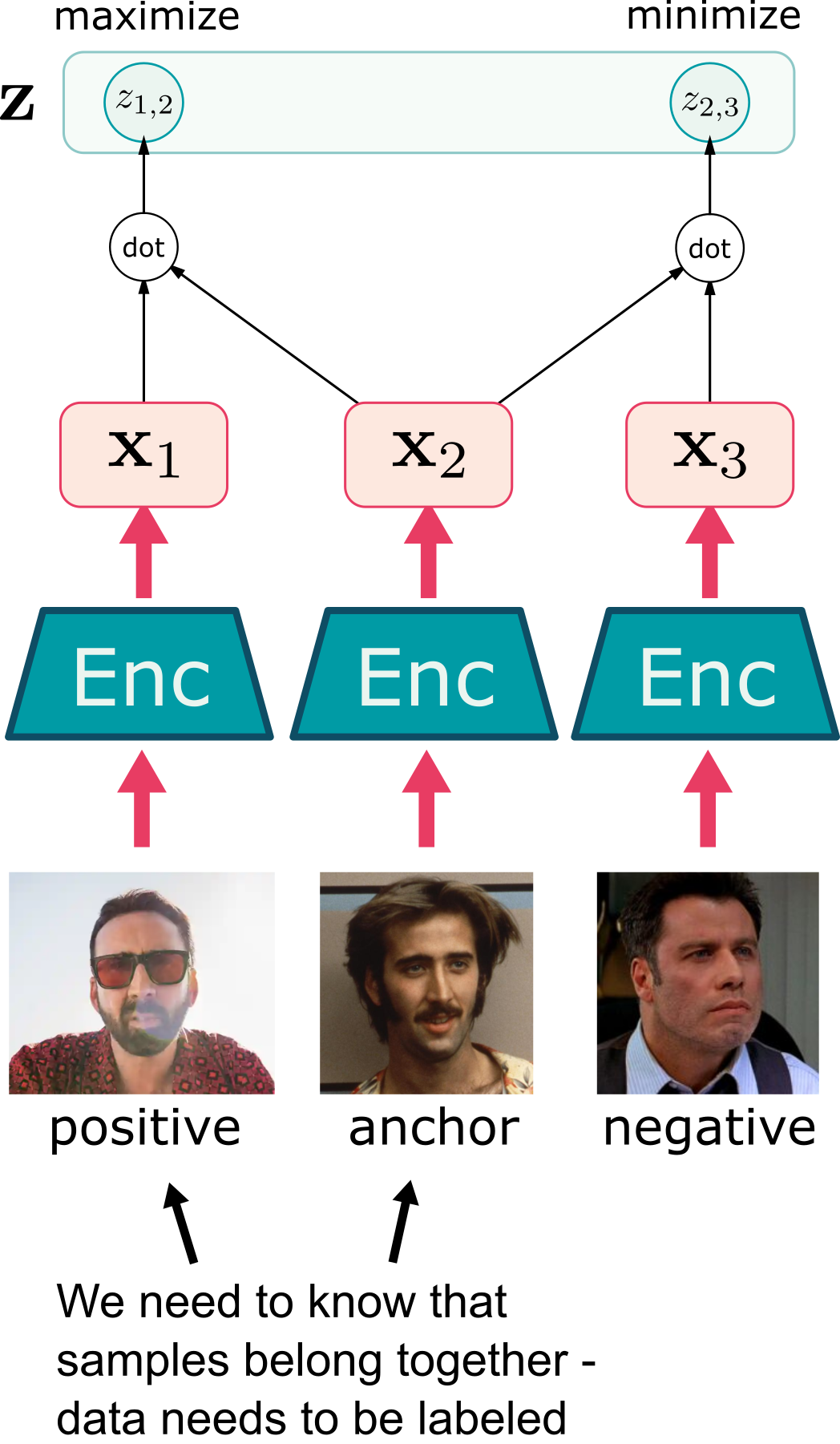
Contrastive learning - triplet loss
By Krishnachandranvn - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=138534332
Triplet loss — the formula
Each training step takes three L2-normalised embeddings — an anchor x_a, a positive x_p (same class), and a negative x_n (different class) — and asks the model to align the anchor with the positive more than with the negative:
x_a \cdot x_p — cosine similarity to the positive; we want this high (close to 1), so the term -x_a \cdot x_p contributes negatively — the loss decreases as the positive aligns.
x_a \cdot x_n — cosine similarity to the negative; we want this low (close to −1), so this term pushes the loss up if the negative is too close.
m > 0 (margin) — enforces a minimum separation: x_a \cdot x_p - x_a \cdot x_n \geq m. Without it, collapsing all embeddings to one point satisfies both terms trivially.
\max(0, \cdot) (hinge) — the loss is exactly zero once the margin is satisfied; gradients vanish on already-correct triples.
Negative samples
Even when the formula is satisfied on average, the model can stagnate if the chosen negatives are too easy:
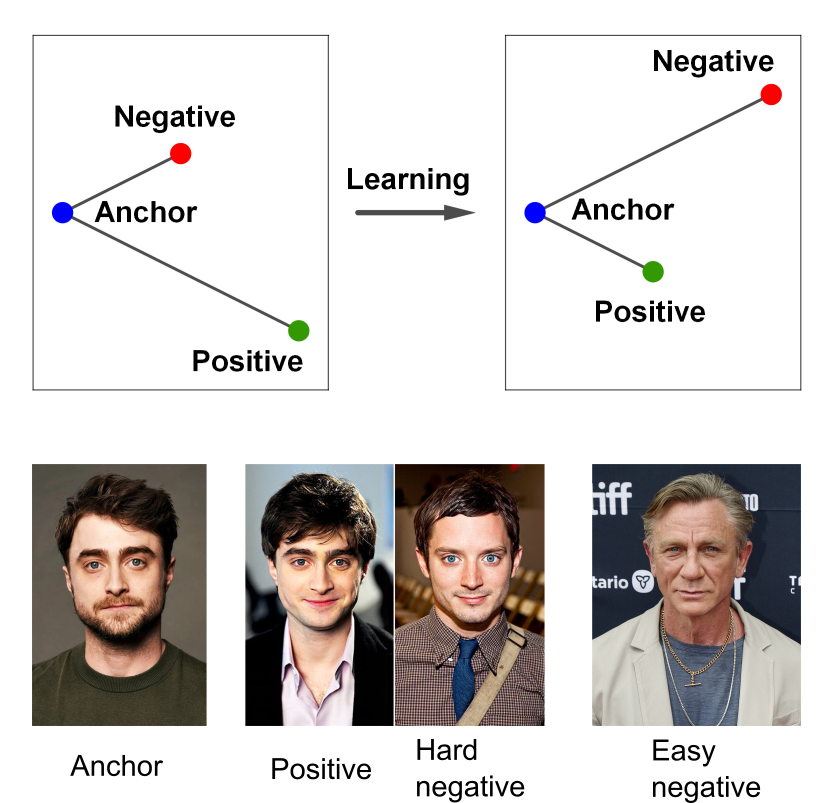
Most randomly sampled negatives are easy; the model therefore needs a hard-negative mining strategy to find informative triples. This adds overhead to the training since we need to introduce a clustering phase which recalculates the neighborhoods at regular intervals.
The setup learns more from hard negatives
Supervised Contrastive (SupCon) loss
Instead of one positive and one negative per anchor, the SupCon loss uses all same-class examples in the batch (i \in I) as positives and all other examples as negatives simultaneously:
From the Deep Learning book (Goodfellow, Bengio, Courville)
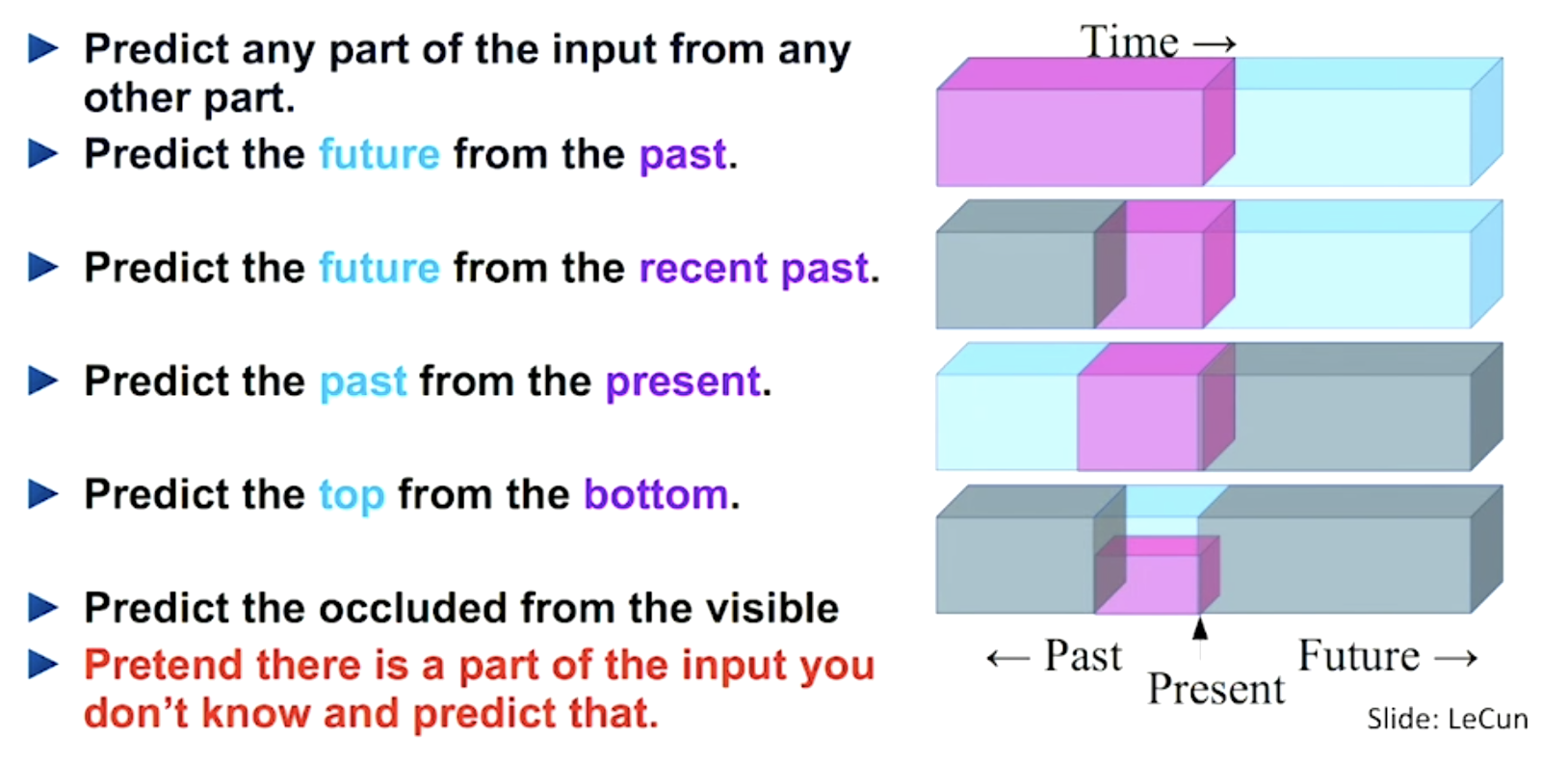
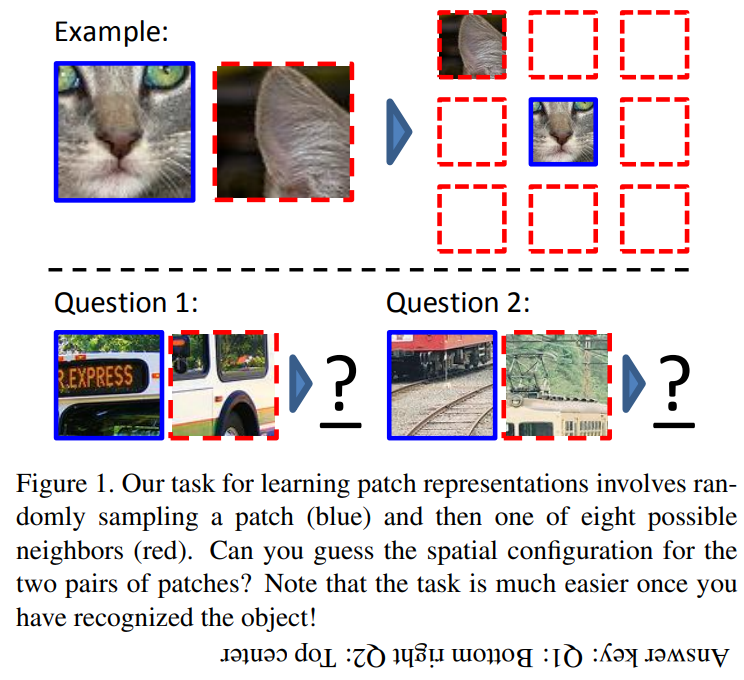
Self-supervised examples - predict in context
Pathak, Deepak, et al. “Context encoders: Feature learning by inpainting.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Noroozi, Mehdi, and Paolo Favaro. “Unsupervised learning of visual representations by solving jigsaw puzzles.” European conference on computer vision. Cham: Springer International Publishing, 2016.
Doersch, Carl, Abhinav Gupta, and Alexei A. Efros. “Unsupervised visual representation learning by context prediction.” Proceedings of the IEEE international conference on computer vision. 2015.
Figure 1
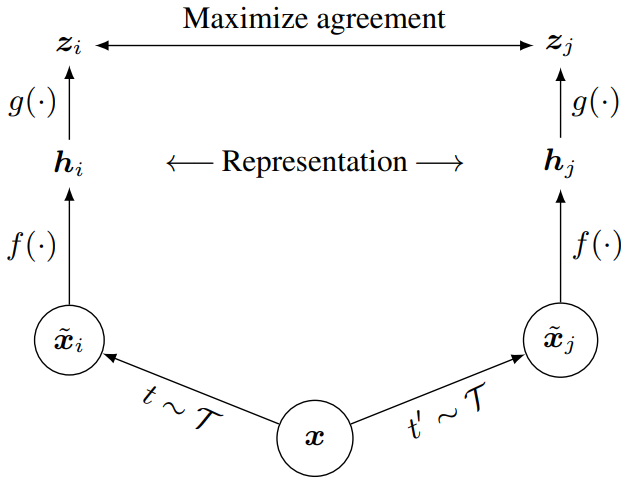
Constrastive self-supervised learning
Instead of relying on existing positive pairs, we can create them
As long as the pairs we create have a semantic association, there is something to learn
SimCLR is a very successful example of this
Chen, Ting, et al. “A simple framework for contrastive learning of visual representations.” International conference on machine learning. PmLR, 2020.
SimCLR - Findings
Finding 1: The combinations of image transformations used to generate corresponding views are critical.
We found that while no single transformation (that we studied) suffices to define a prediction task that yields the best representations, two transformations stand out: random cropping and random color distortion. Although neither cropping nor color distortion leads to high performance on its own, composing these two transformations leads to state-of-the-art results.
Finding 2: The nonlinear projection is important
In our experiments, we found that using such a nonlinear projection helps improve the representation quality, improving the performance of a linear classifier trained on the SimCLR-learned representation by more than 10%.
Finding 3: Scaling up significantly improves performance.
we observe that the performance of a supervised ResNet peaked between 90 and 300 training epochs (on ImageNet), but SimCLR can continue its improvement even after 800 epochs of training
SimCLR — NT-Xent loss
For each image, SimCLR creates two augmented views(x_i, x_j), encodes and projects both to get normalised embeddings z_i, z_j. The NT-Xent (Normalised Temperature-scaled Cross-Entropy) loss asks the model to identify the matching view among all 2(N-1) other views in the batch:
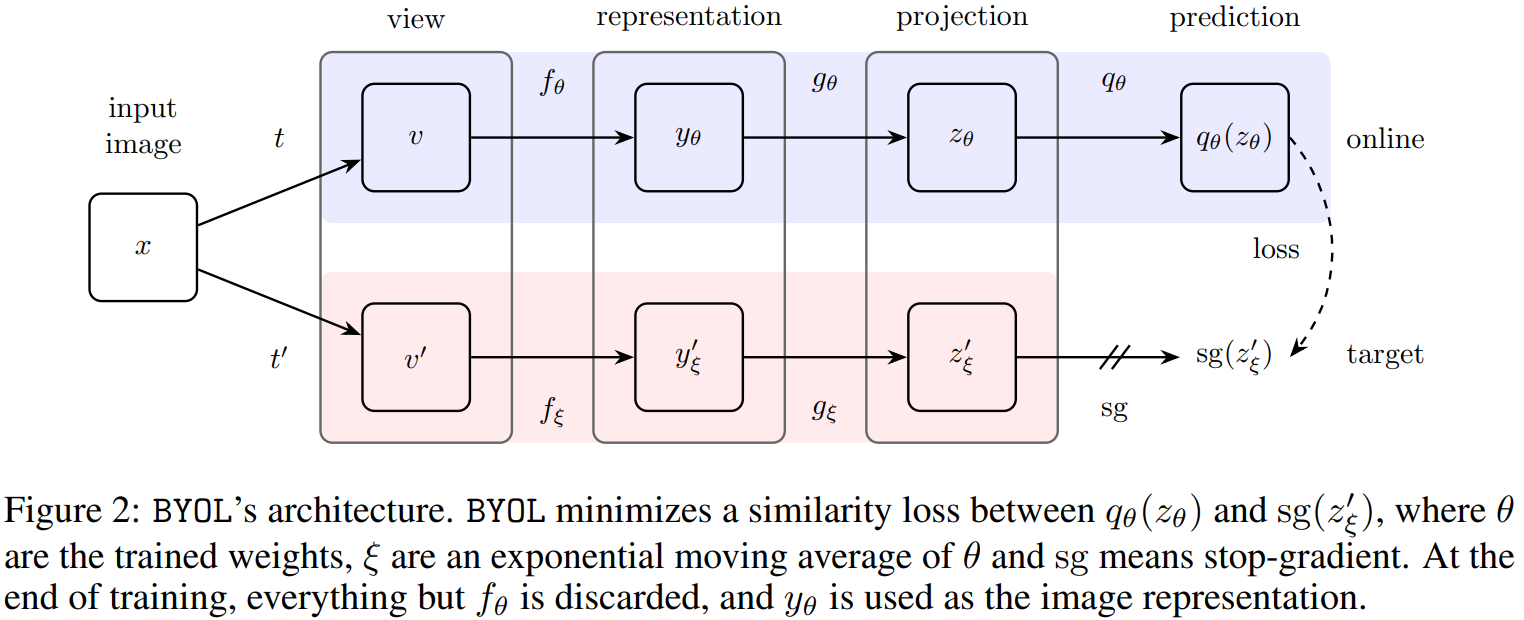
Instead of avoiding representation collapse by using negative contrastive examples, what if we have two different models?
The main network we try to train – the online network
Another network we use to create the representations – the target network
Grill, Jean-Bastien, et al. “Bootstrap your own latent - a new approach to self-supervised learning.” Advances in neural information processing systems 33 (2020): 21271-21284.
BYOL — loss and update rule
BYOL trains an online network (parameters \theta) to predict the representations of a target network (parameters \xi). There are no negative pairs; collapse is prevented by the asymmetry between the two networks.
Target projection for a different augmented view x'
q_\theta(\cdot)
Online predictor head (extra MLP absent from target network)
\bar{v} = v / \|v\|_2
L2-normalised vector
\xi \leftarrow \lambda\,\xi + (1-\lambda)\,\theta
Target updated via EMA — no gradient flows through it
The predictorq_\theta creates the key asymmetry: the target has no predictor, so the online network must actively predict rather than just copy, preventing trivial collapse.
The EMA target acts as a slowly evolving, consistent supervision signal — a “momentum encoder”.
Grill, Jean-Bastien, et al. “Bootstrap your own latent.” NeurIPS, 2020.
DINO = BYOL + Vision Transformers
Caron, Mathilde, et al. “Emerging properties in self-supervised vision transformers.” Proceedings of the IEEE/CVF international conference on computer vision. 2021.
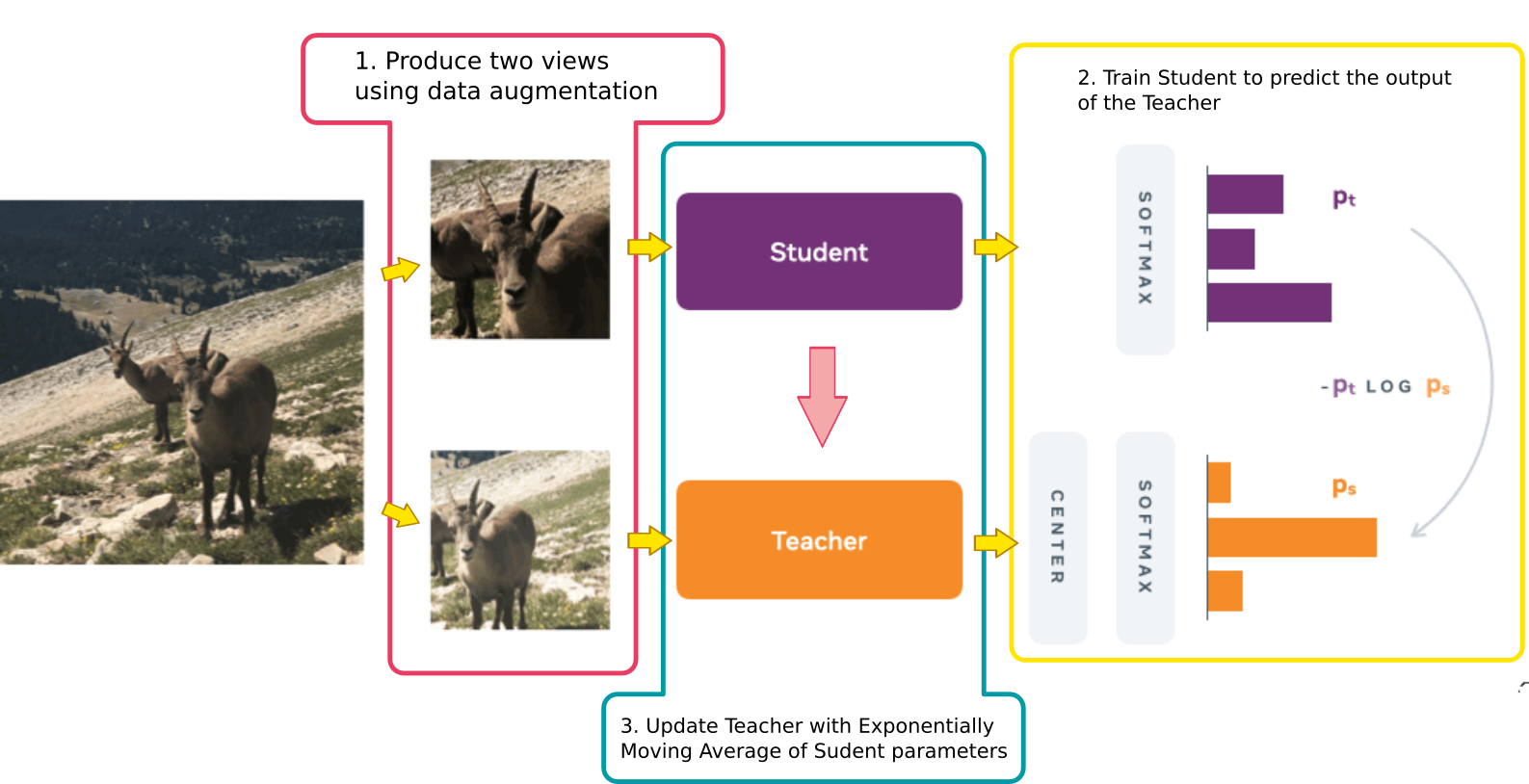
DINO — self-distillation loss
DINO uses a self-distillation objective: the student learns to match the (sharper) teacher’s output distribution over a set of learned prototype dimensions.
Student temperature higher — teacher output is sharper (more confident)
c
Centering vector: EMA of teacher outputs, subtracted to prevent one-prototype collapse
\mathcal{V}
Multi-crop views: 2 global + several local crops
\theta_t \leftarrow m\,\theta_t + (1-m)\,\theta_s
Teacher updated by EMA only — no backprop through teacher
Global-to-local consistency: teacher sees only global crops; student sees local crops too — forcing the student to infer global structure from a small patch.
Collapse is prevented by two complementary mechanisms: centering (shifts teacher logits) and sharpening (low \tau_t makes teacher peaked).
Caron, Mathilde, et al. “Emerging properties in self-supervised vision transformers.” ICCV, 2021.
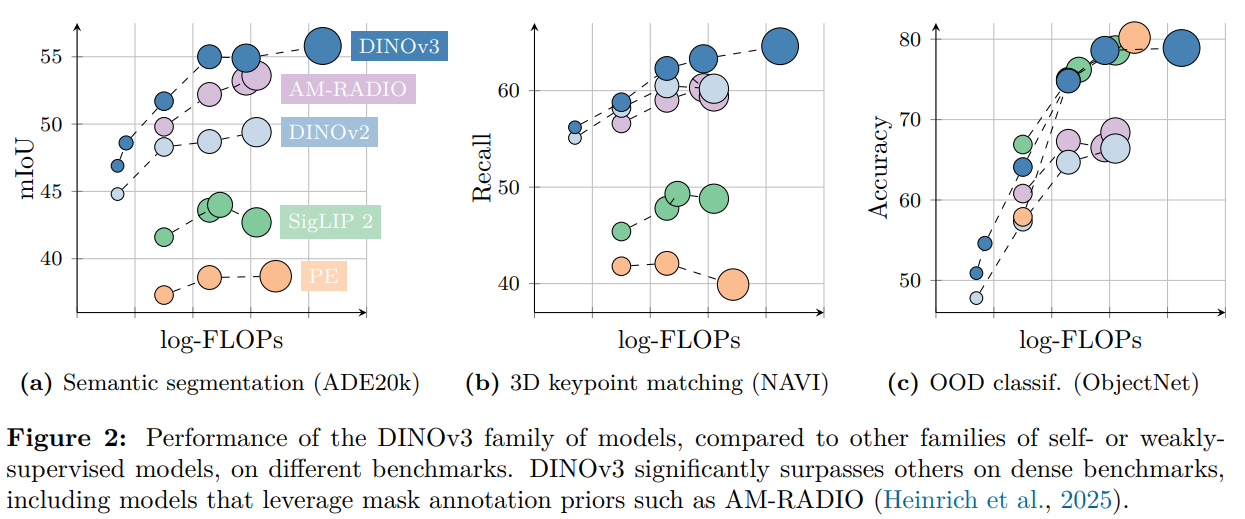
DINO v3
Development of DINO v2 to increase model scale
Large data with auto curation
Regularized patch representations with Gram matching
Siméoni, Oriane, et al. “Dinov3.” arXiv preprint arXiv:2508.10104 (2025).
With supervised contrastive learning we need to label the data
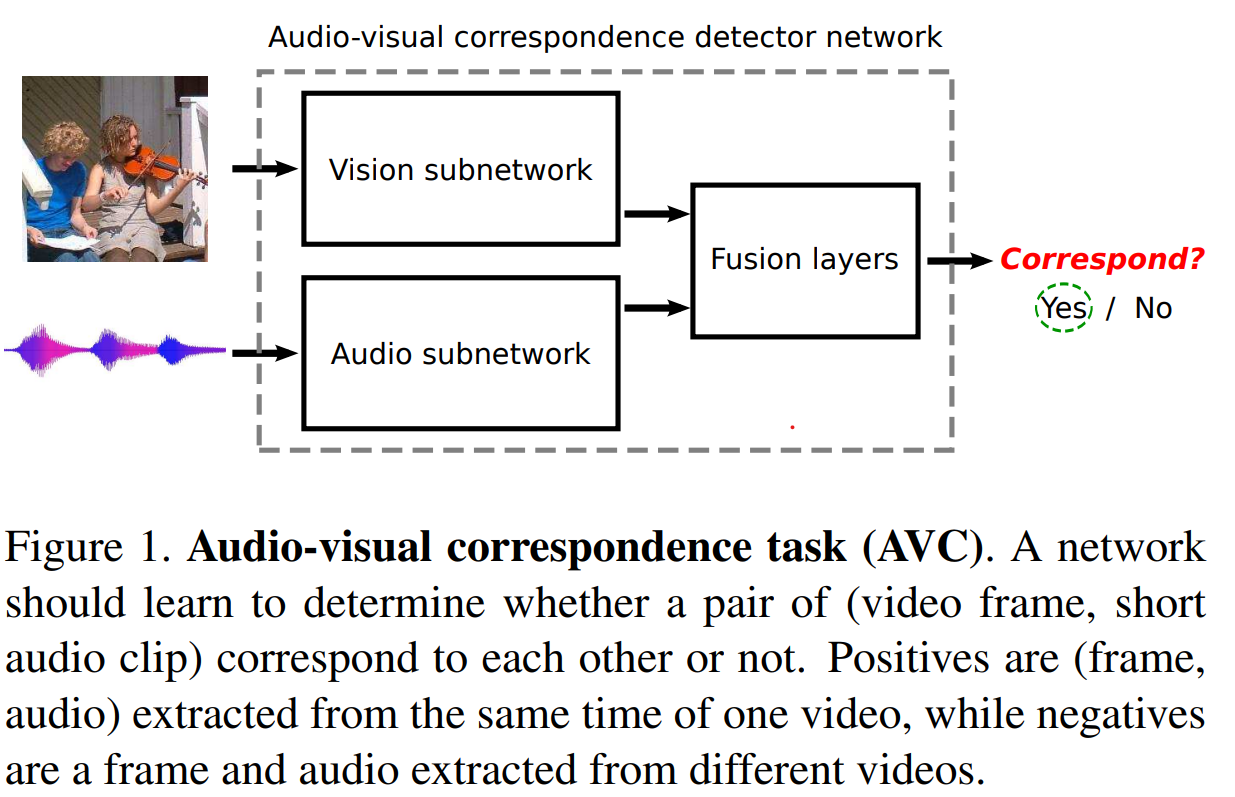
Arandjelovic, Relja, and Andrew Zisserman. “Look, listen and learn.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
With multimodal data we have “natural” associations in the separate modalities.
Use modalities to label each other
Figure 3: Arandjelovic, Relja, and Andrew Zisserman. “Look, listen and learn.” Proceedings of the IEEE International Conference on Computer Vision. 2017. za
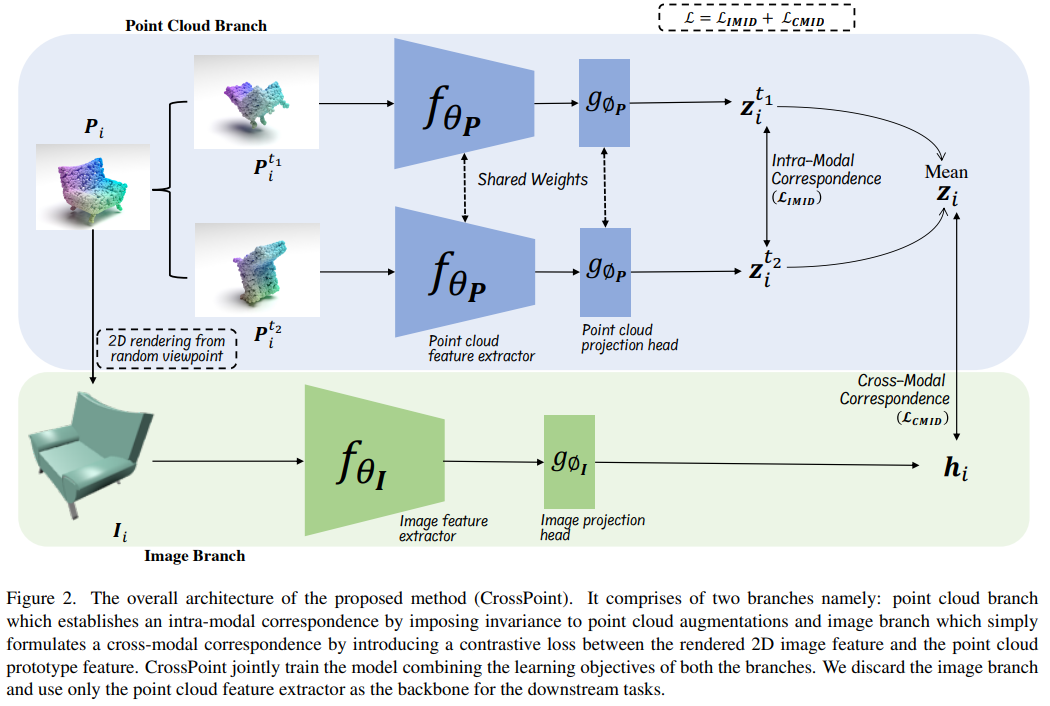
Use modalities to label each other
Afham, Mohamed, et al. “Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
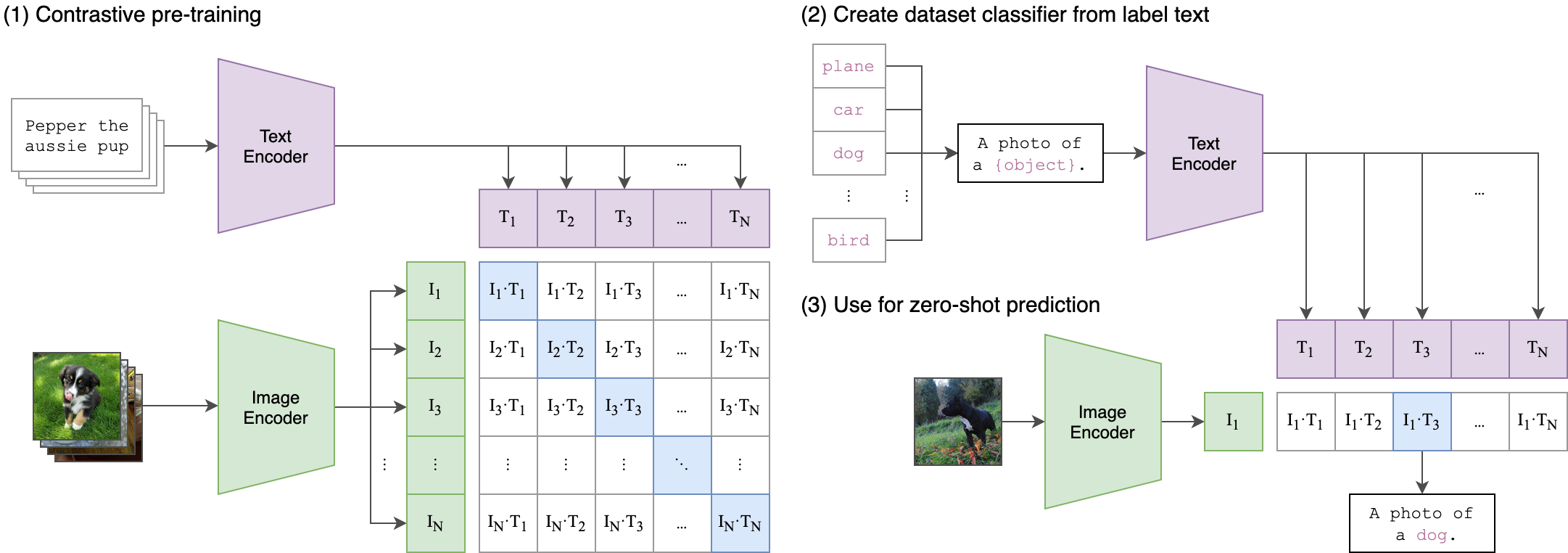
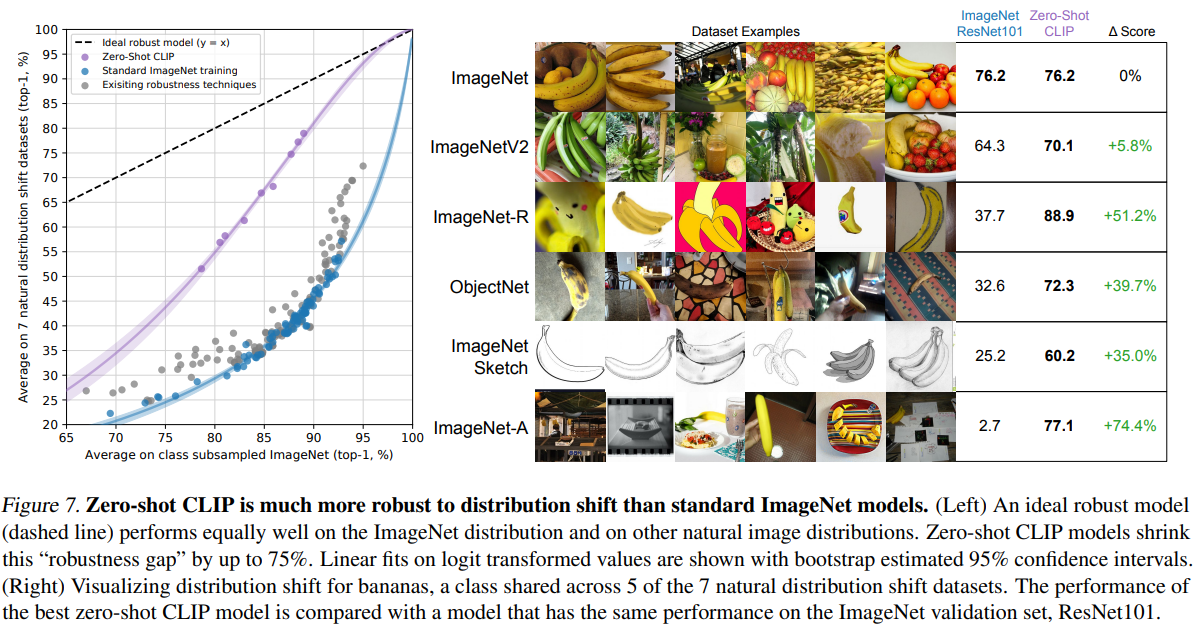
CLIP
https://github.com/openai/CLIP
CLIP
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
CLIP — symmetric contrastive loss
For a batch of N image–text pairs, CLIP computes L2-normalised embeddings from two separate encoders and applies a symmetric NT-Xent loss across modalities:
L2-normalised text embedding for paired caption c_i
\tau
Learned temperature (not a fixed hyperparameter as in SimCLR)
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” ICML, 2021.
CLIP — symmetric contrastive loss
For a batch of N image–text pairs, CLIP computes L2-normalised embeddings from two separate encoders and applies a symmetric NT-Xent loss across modalities:
vs SimCLR: identical NT-Xent structure — one positive per anchor, all others are implicit negatives — but the “two views” come from different modalities rather than image augmentations. The loss is also symmetrised (both I \to T and T \to I).
vs SupCon: each anchor has exactly |P(i)| = 1 positive (its paired caption), making it the single-positive special case of SupCon. Scaling to very large batches gives the same benefit SupCon gets from many in-batch positives: a rich, continuous repulsion against all other examples.
The key novelty is using natural image–language pairing as supervision — no augmentation strategy needed, just internet-scale (image, caption) pairs.
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” ICML, 2021.
Summary
Contrastive learning is a general technique for learning representations
Self-supervised learning is about crafting ways of learning from unlabeled data
Clever augmentations technique can use contrastive learning without labled data
Multimodal data is perfect for contrastive learning, the modalities “label each other”