Practical Advice
Generalization, hyperparameters, and practical deep learning
08-May-2026
How generalization fails
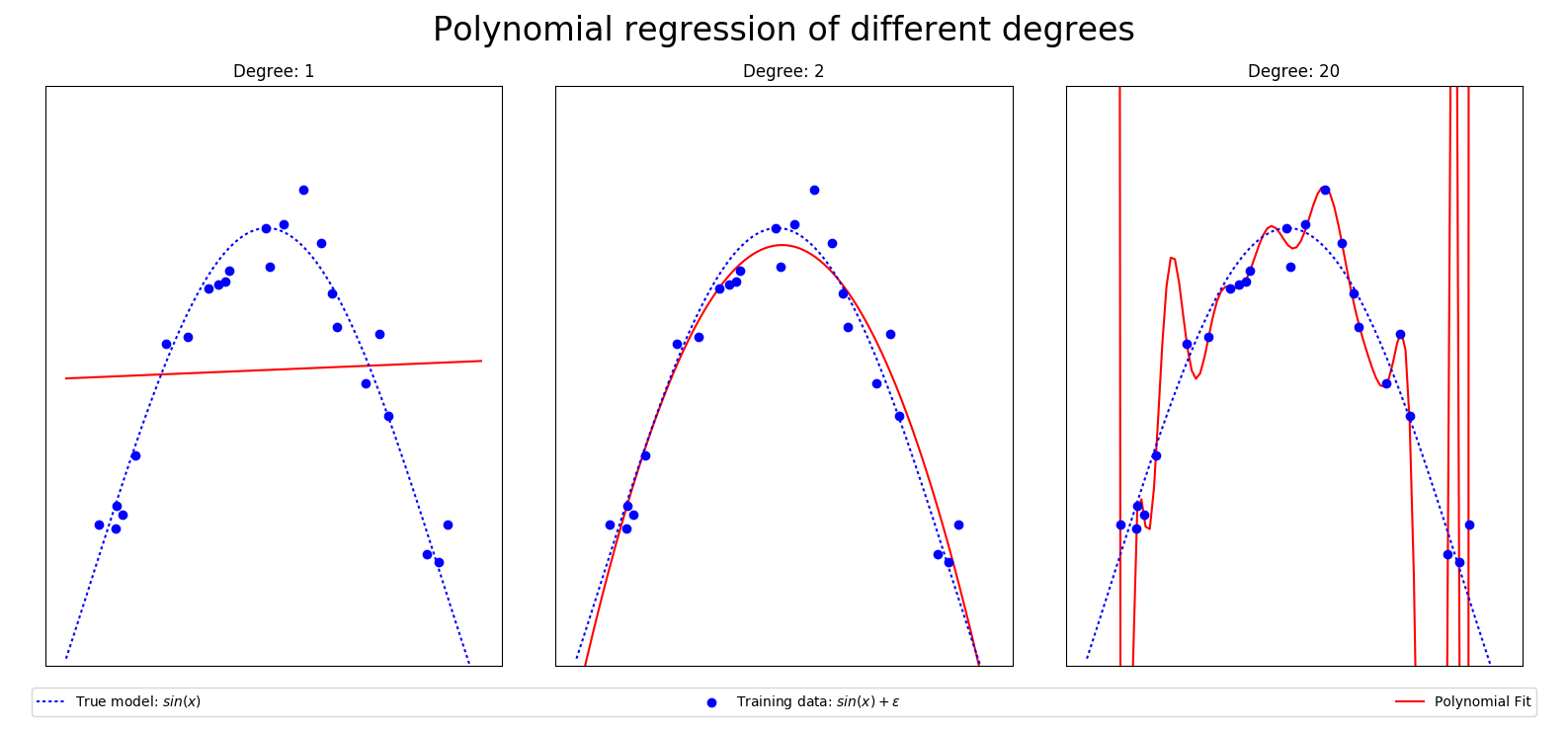
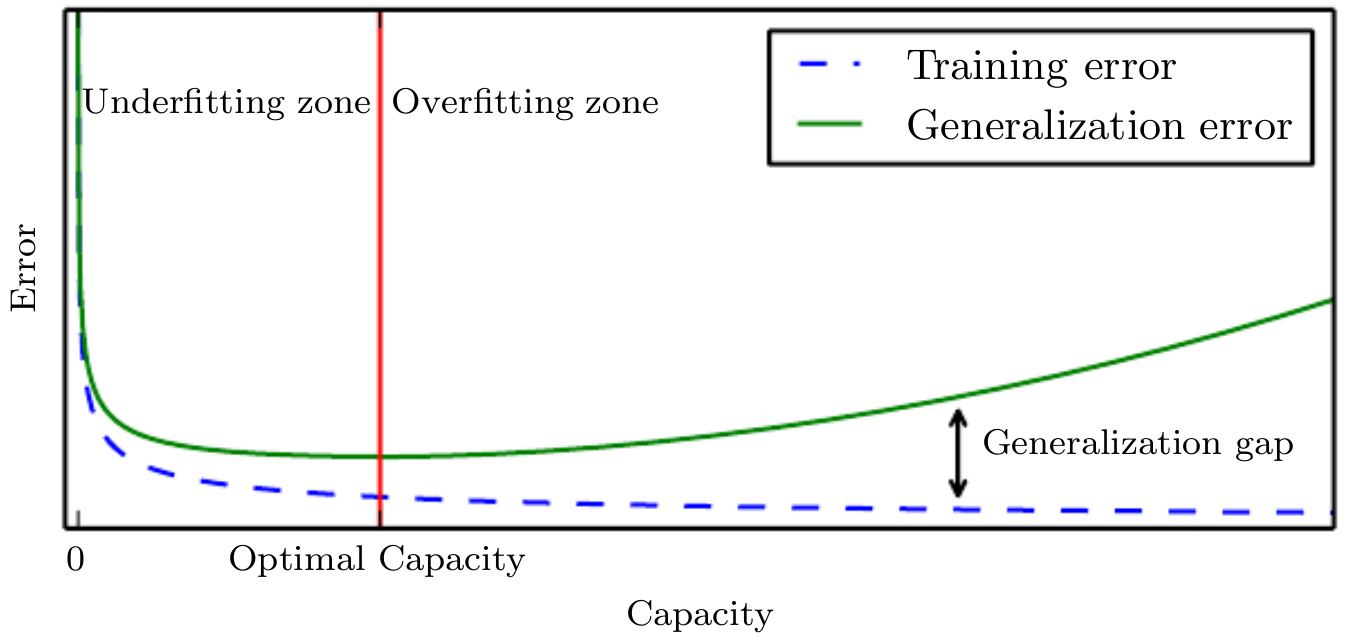
Underfitting
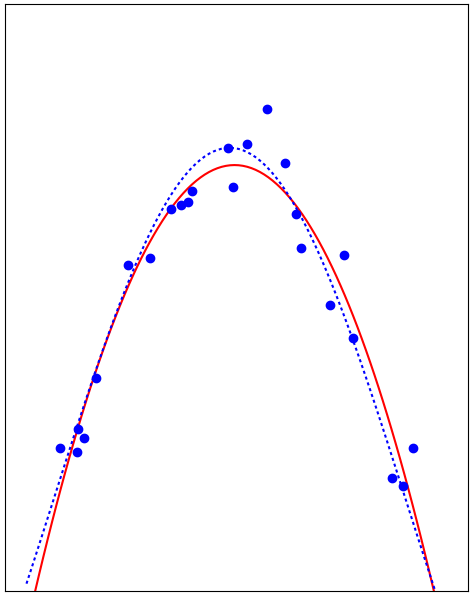
Just right
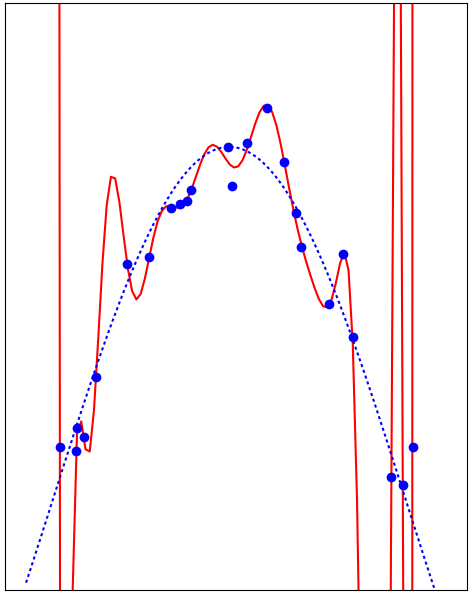
Overfitting
Underfitting
- The adjustable function is inflexible, its capacity is too low
- It misses the important variation in the data
- It performs as poorly on all data, training and other
- Both training and generalization error is high
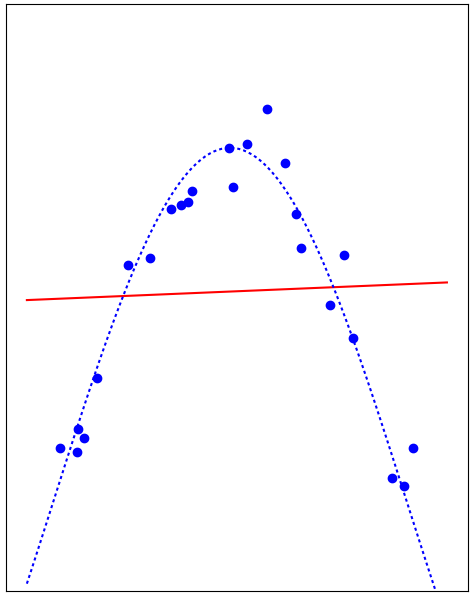
Overfitting
- The adjustable function is too flexible, its capacity is too high
- It adjusts to the unimportant variations in the data, like noise
- Outside of the training data it performs poorly
- Training error is low, generalization error is high
Just right
- The adjustable function is just flexible enough, it has enough capacity
- It adjusts to the variations in the data which are general
- It would give good predictions for new data
- Training error and generalization error follow each other
Hyperparameters
- Parameters which are determined before learning are called hyperparameters
- They often control model capacity or the speed of the learning (which is implicitly model capacity)
- The number of free parameters directly controls capacity, so is considered a hyperparameter

Few free parameters — low capacity

Lots of free parameters — high capacity
Tuning hyper parameters
- We can plot the dev-set error as a function of model capacity (e.g. by varying a capacity controlling hyper parameter)
- We look to the minimum on these error curves for good hyper parameter settings
Small datasets — high estimator variance
- If the amount of data is small, there’s a risk that the test or development sets becomes non-representative
- Similar to having too small sample sizes in traditional statistical studies
- They become poor estimates for the generalization error

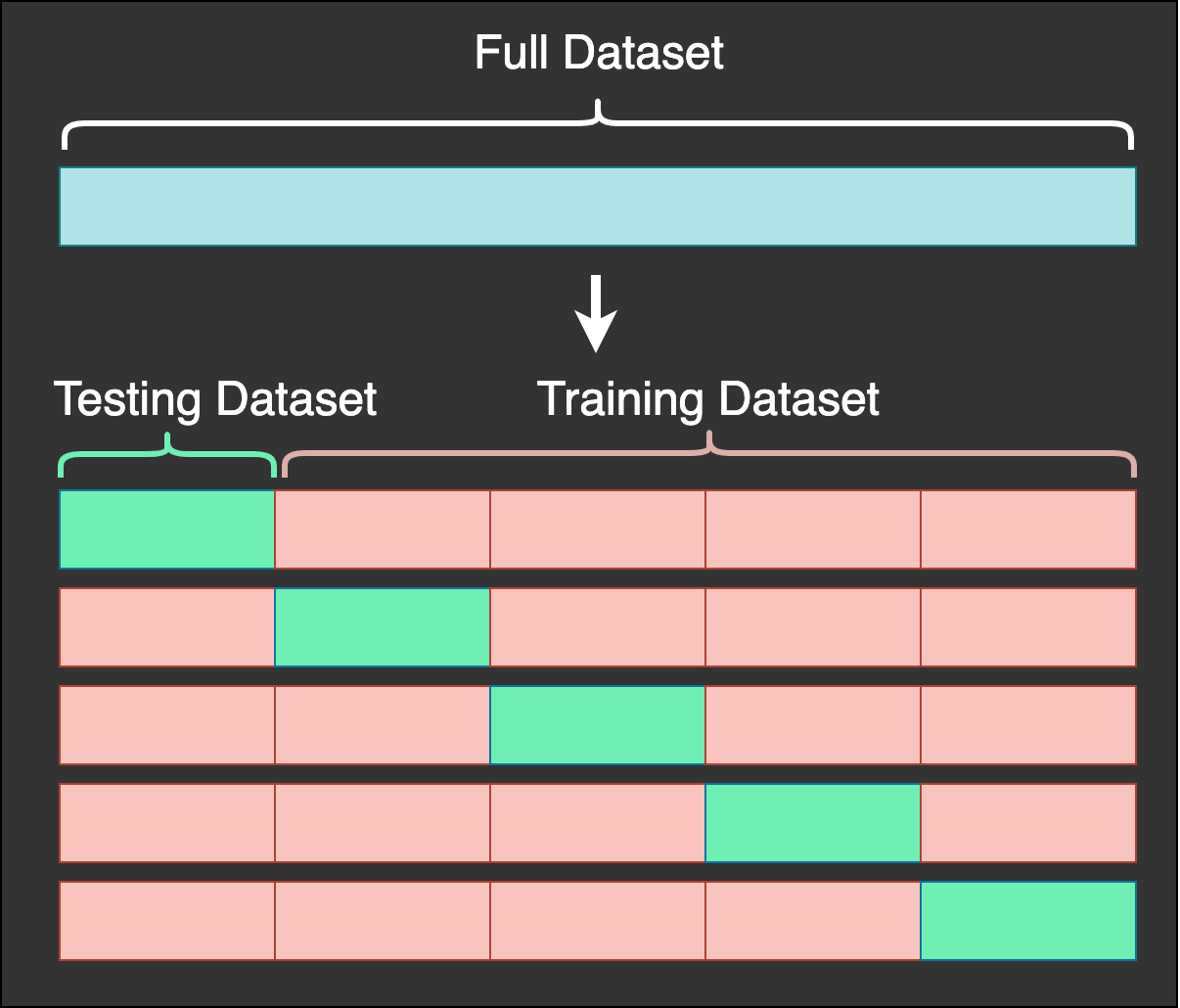
Cross validation
A useful algorithm is to run multiple trainings with different test sets, this is called cross-validation.
Source: https://mlfromscratch.com/nested-cross-validation
Cross validation
The average error over all splits is a better estimate of the generalization error than using a single split.
Source: https://mlfromscratch.com/nested-cross-validation
Nested cross validation
- For deep neural networks, it’s often a good idea to do nested cross validation for the cases you would need cross validation
- First use cross validation to select multiple test sets, for each of the training sets, do further cross-validation with different development sets
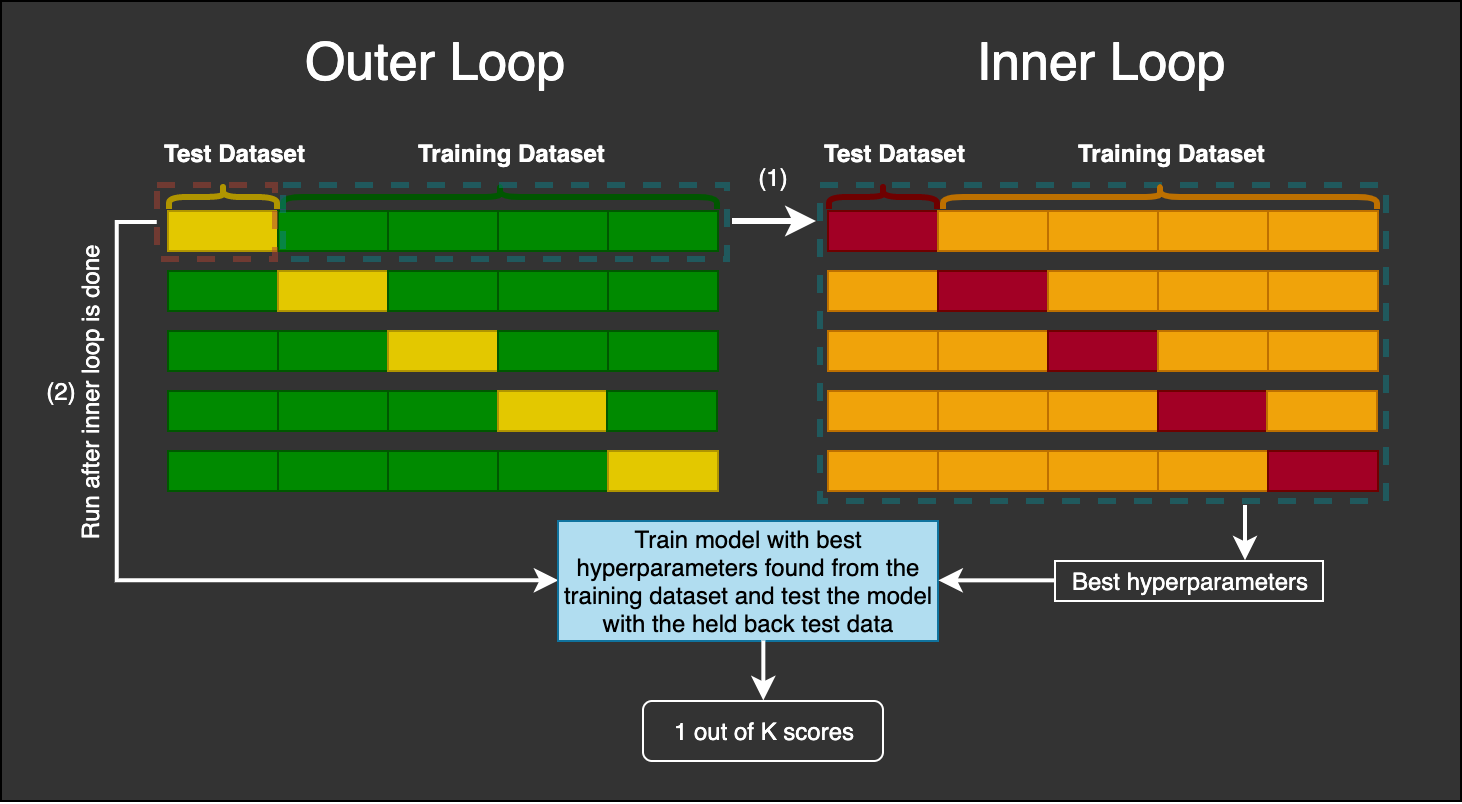
Source: https://mlfromscratch.com/nested-cross-validation-python-code
Overfitting in neural networks

Source: https://stanford.edu/~shervine/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks
How do you decide hyper parameters?

Grad Student Descent — someone manually tries out a bunch.
Hyperparameter tuning example
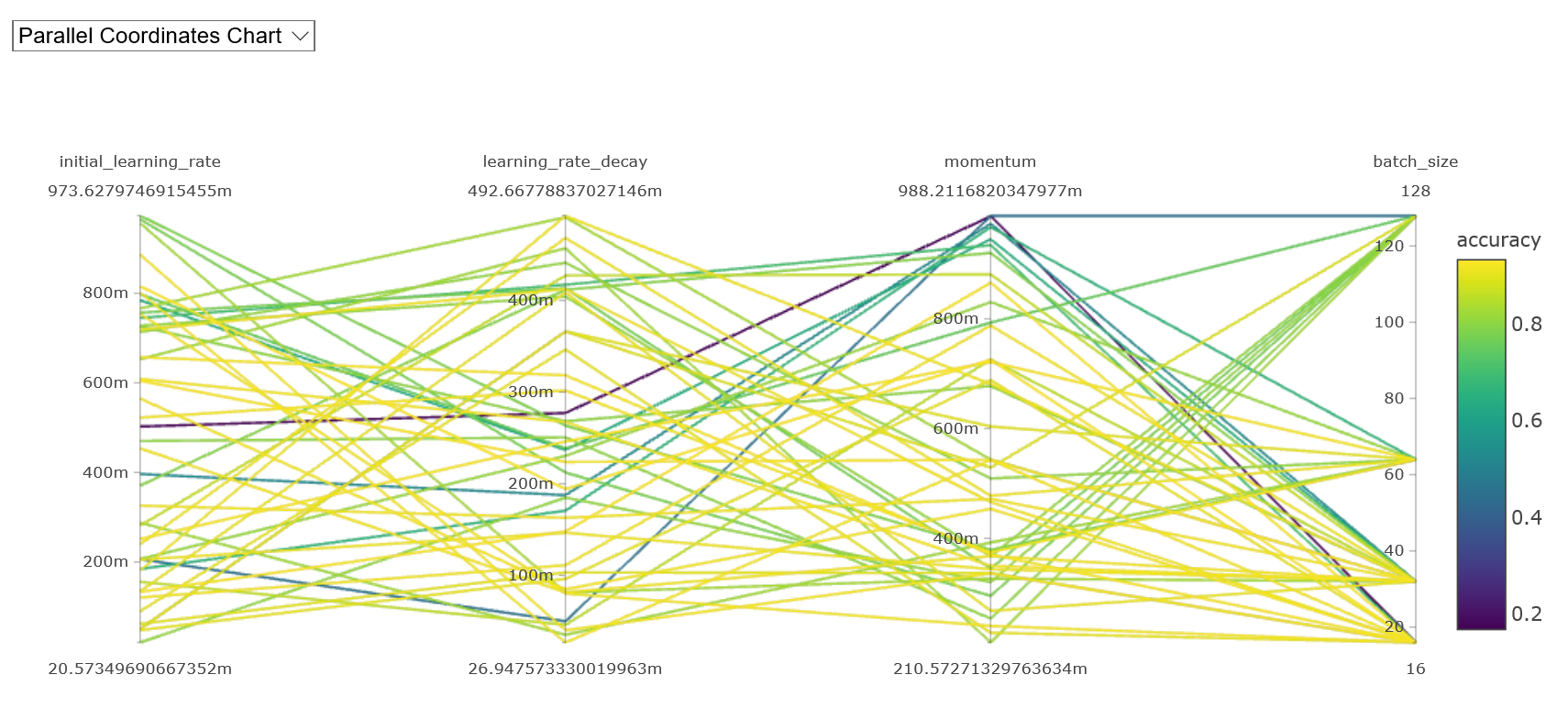
Parallel coordinates chart of hyperparameter sweeps over learning rate, decay, momentum, and batch size, coloured by accuracy
Source: https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-tune-hyperparameters
Start with random hyperparameter search
- Grid search tests all combinations of values in nested loops
- A lot of time might be spent testing different values for unimportant hyper parameters without getting new information for the important ones
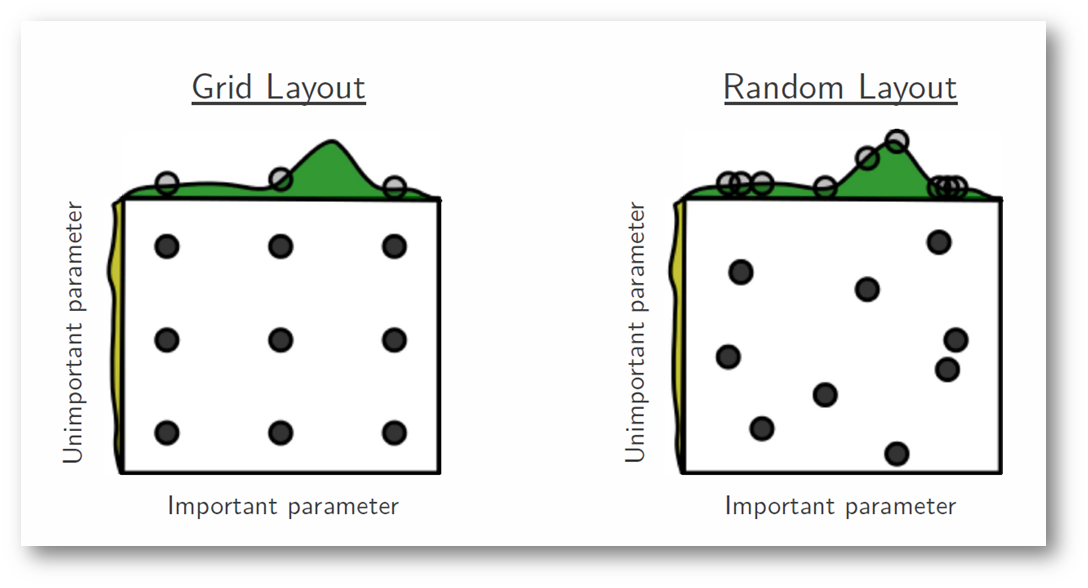
Bergstra, James, and Yoshua Bengio. “Random search for hyper-parameter optimization.” Journal of Machine Learning Research 13.Feb (2012): 281-305.
Smarter hyper parameter tuning
- We can try to fit another machine learning model to predict validation error given hyper parameter settings
- Think of response surface methodology in Design of Experiments
- Popular methods include Bayesian optimization using Parzen tree estimators
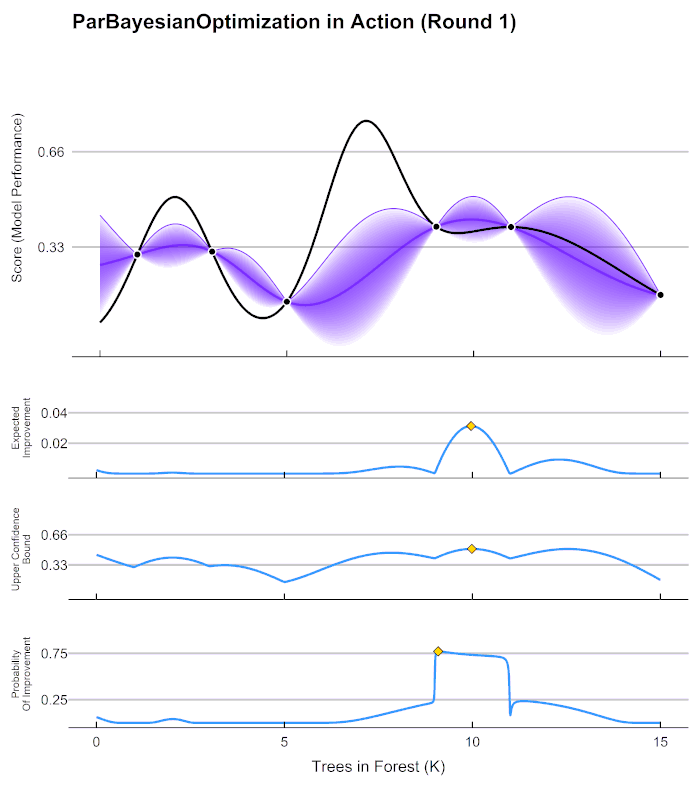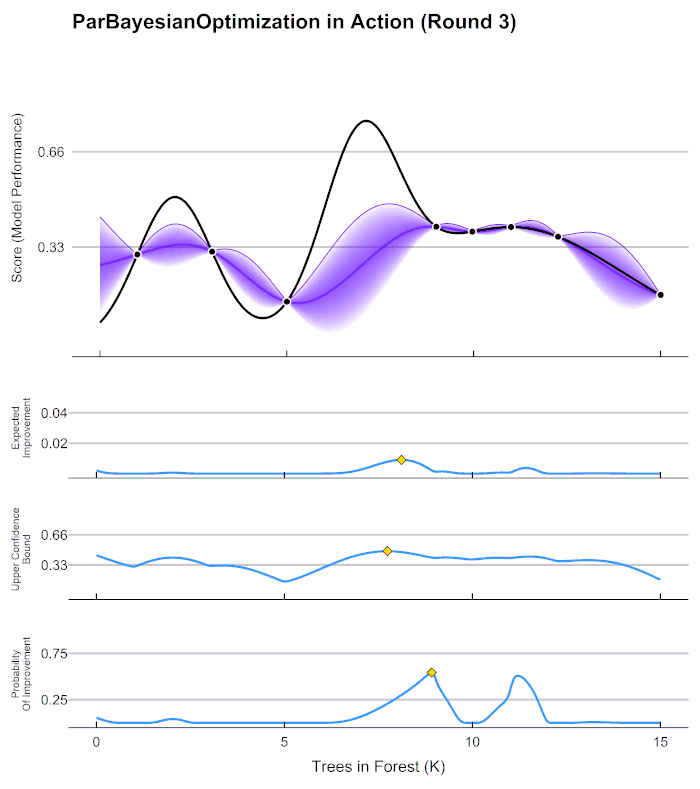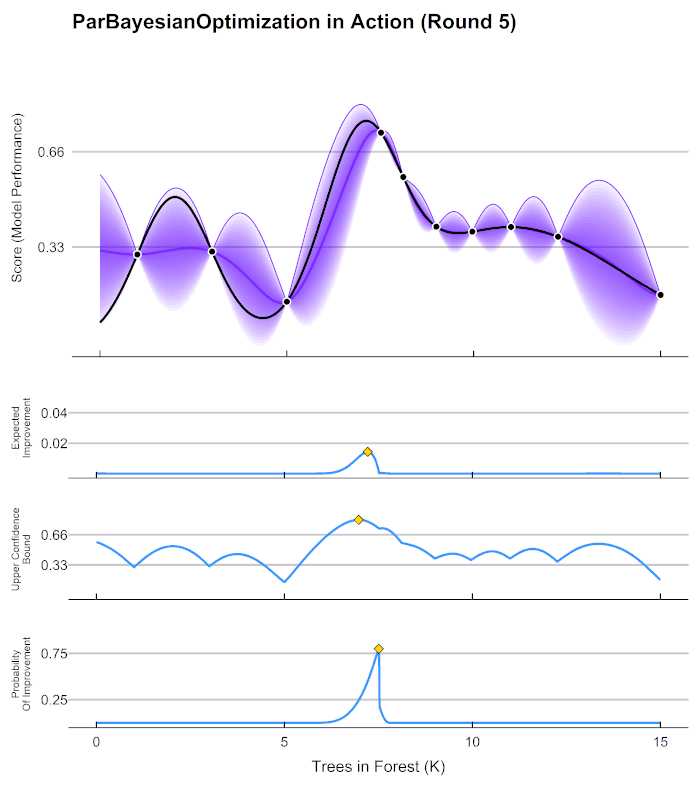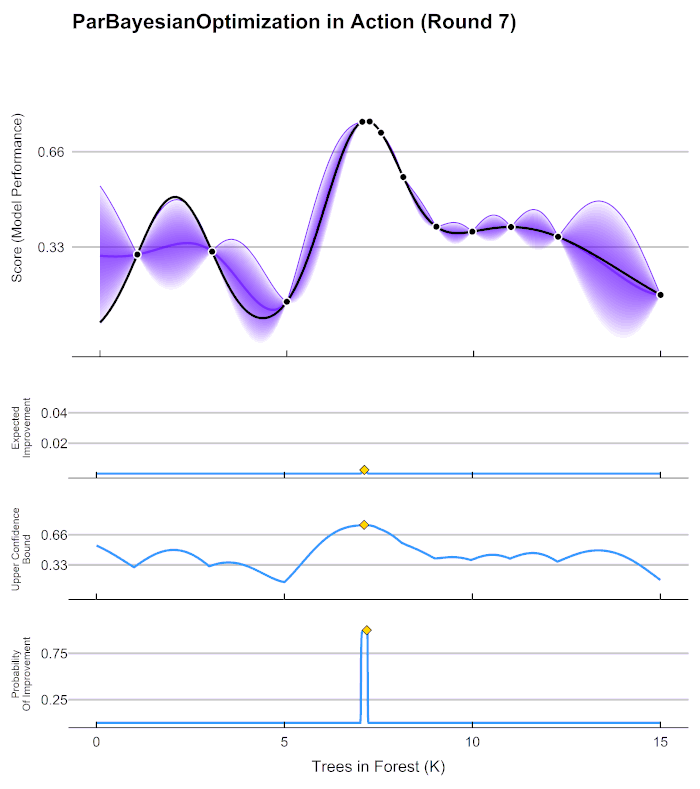
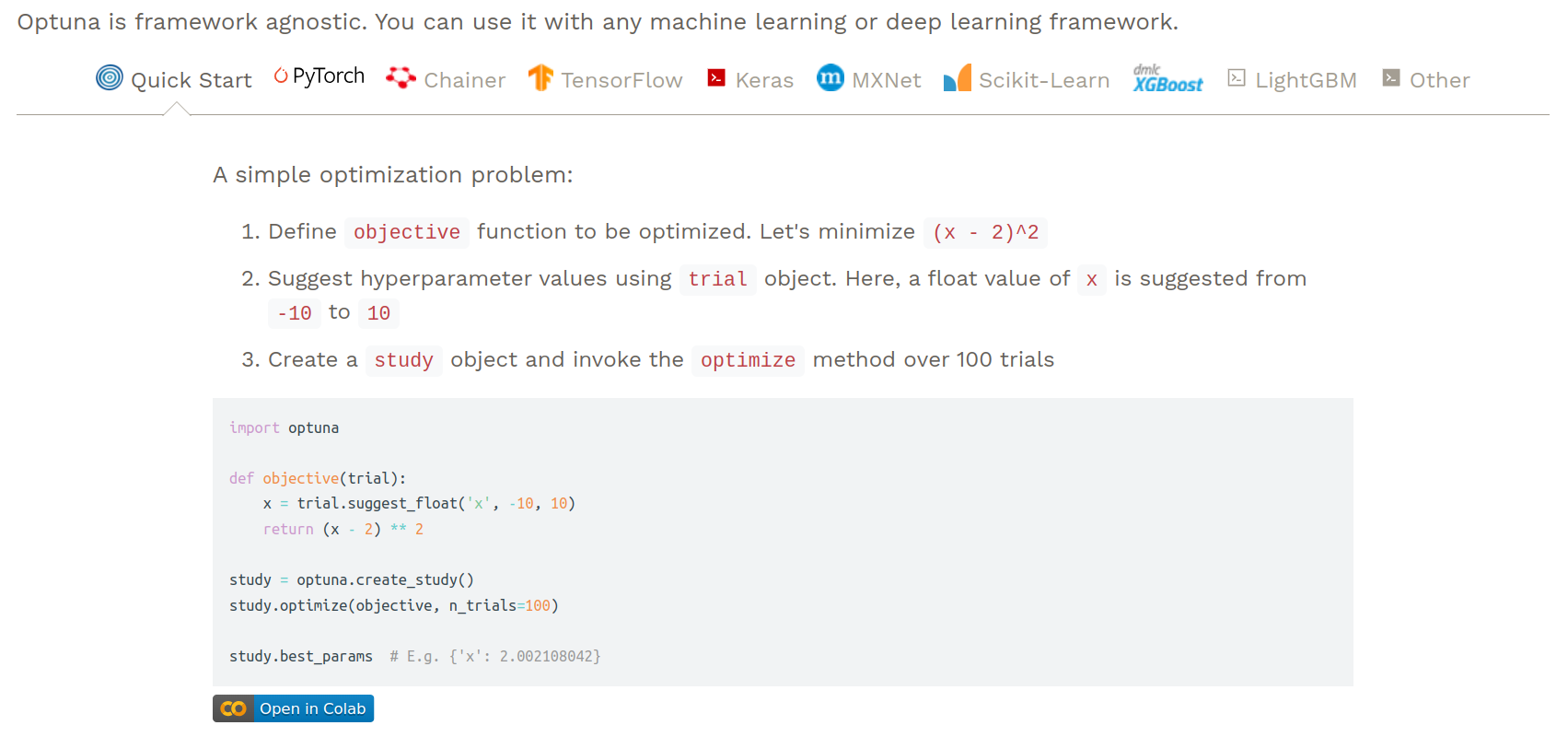
Optuna
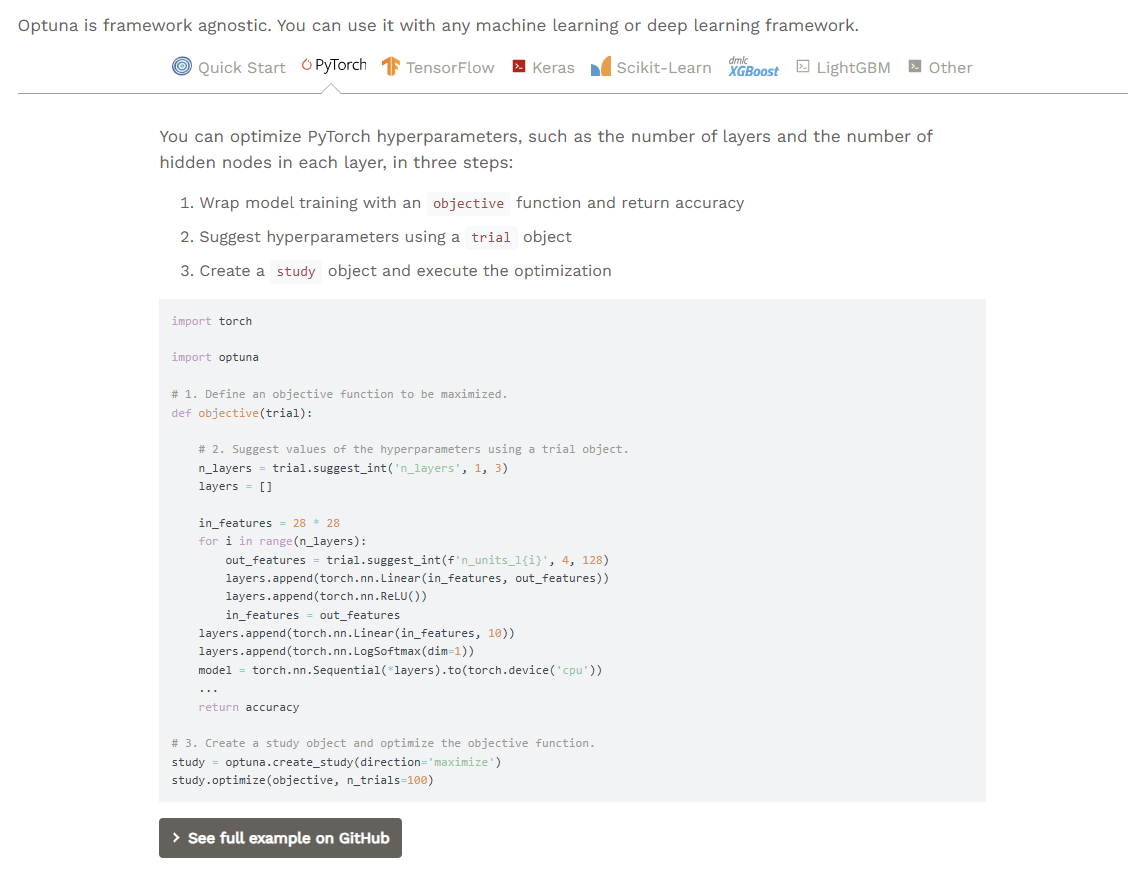
Optuna
Assumptions with linear outputs
- Linear outputs implicitly models P(Y|X) as a Gaussian
- In particular, it estimates the mean, E[Y|X]
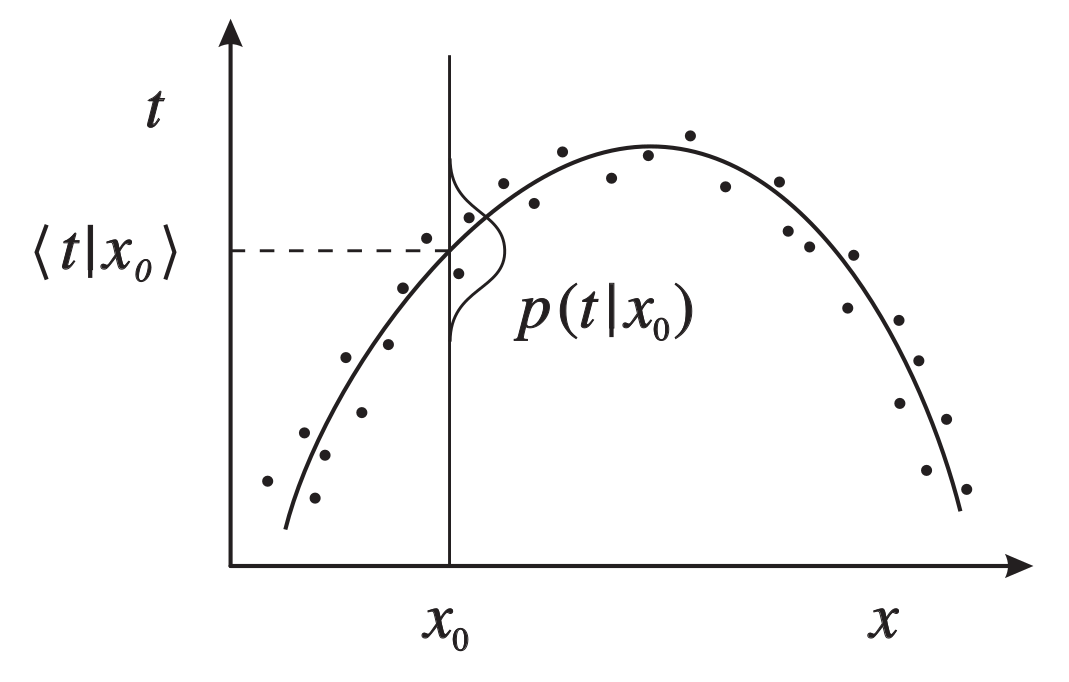
Bishop, Christopher M. “Mixture density networks.” (1994).
Mixture Density Networks

Gaussian Mixture Models (GMM) Explained, https://youtu.be/wT2yLNUfyoM?si=aYHnmxvH2wVhDjX6
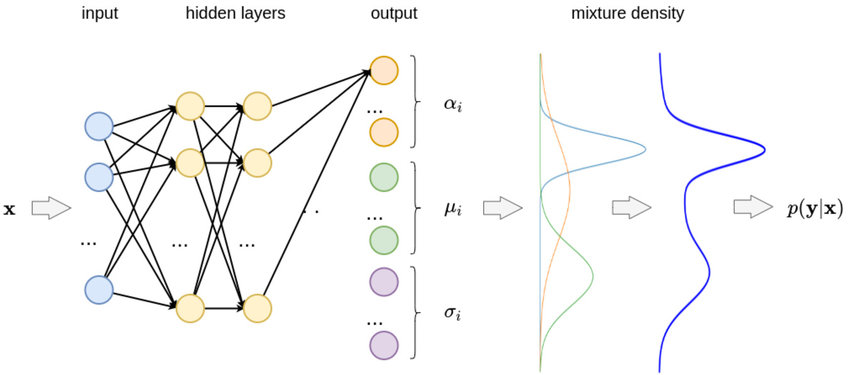
Petrov, Tatjana, and Denis Repin. “Automated deep abstractions for stochastic chemical reaction networks.” arXiv preprint arXiv:2002.01889 (2020).
Assumptions with linear outputs
- For many problems P(Y|X) is far from Gaussian
- The mean is often a poor prediction
- Fitting an MDN can be tricky because the distribution has weird spikes and skews
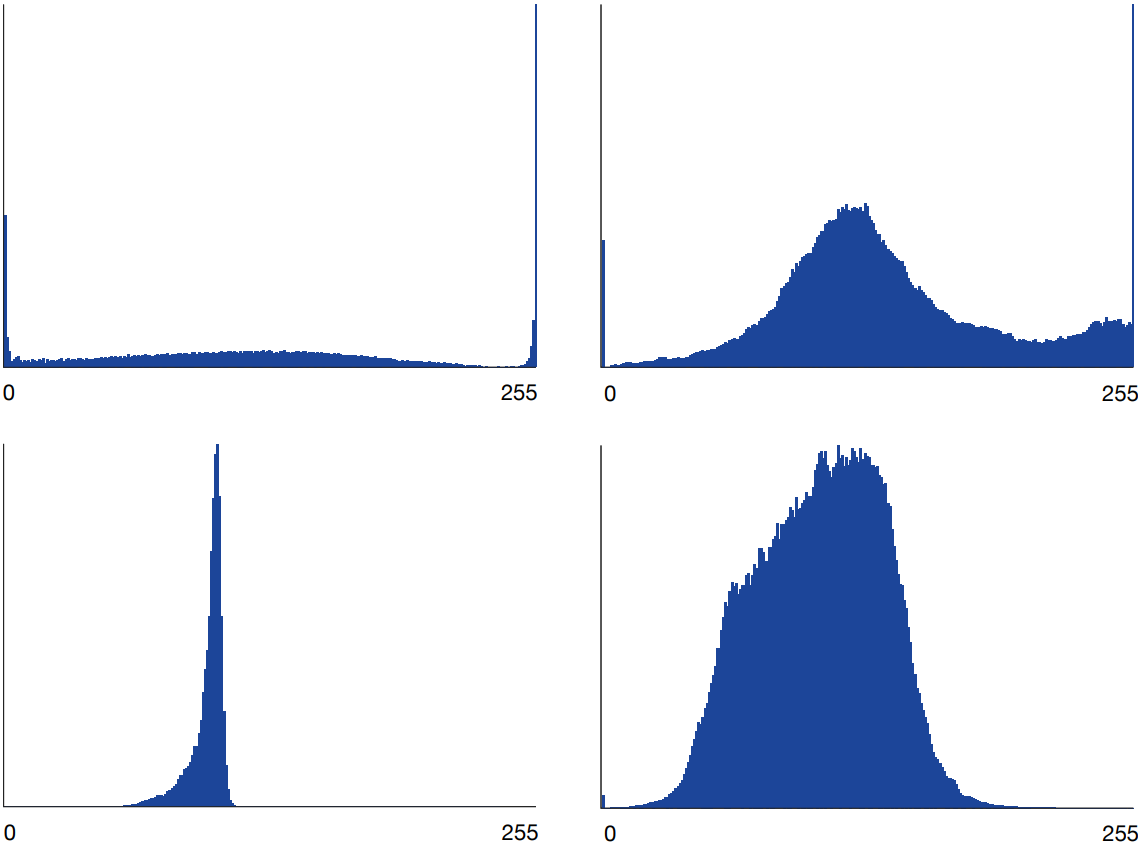
Oord, Aaron van den, Nal Kalchbrenner, and Koray Kavukcuoglu. “Pixel recurrent neural networks.” arXiv preprint arXiv:1601.06759 (2016).
Discretization hack
- We can discretize the continuous target into discrete values
- Turn the regression task into a classification task
- This is just like creating a histogram of the data
Discretization trick
- A common strategy is to decide on the number of bins, then select the bin edges as the quantiles of the empirical distribution
- Deciding number of bins is difficult. Look at histograms of your data.
Thank you!
erik.ylipaa@scilifelab.se