Good practices of NN/DL project design
08-May-2026
What to do and - more importantly perhaps - not to do

And even if I have enough data for a NN…
… is Deep Learning the right choice?
- The tasks were Deep Learning shine are those that require feature extraction:
- Imaging -> edge/object detection
- Audio/text -> sound/word/sentence detection
- Protein structure prediction -> mutation patterns/local structure/global structure
- Deep Learning makes feature extraction automatic and seem to work best when there is a hierarchy to these features
- Is your data made that way?
- Does it have an order (spatial/temporal)?
- Are smaller patterns going to form higher-order patterns?
- All these different types of layers need to be there for a reason
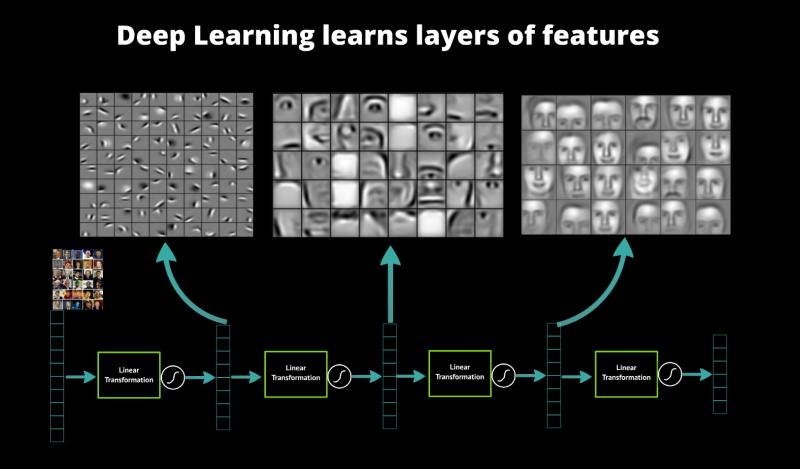
source: datarobot
(a.k.a. target leakage)
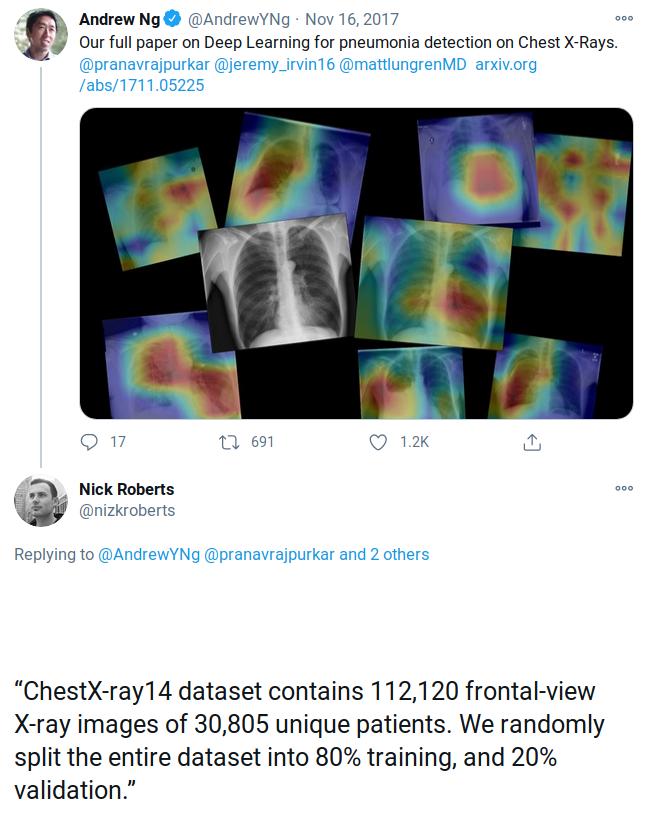
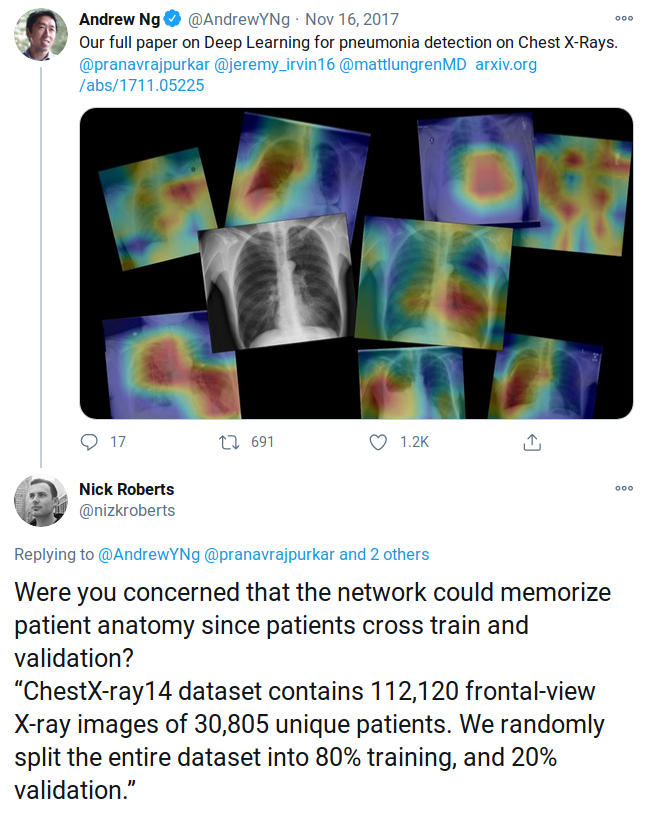
Example: detecting COVID-19 from chest scans
Inspecting dataset with image embeddings tells another story: can anyone tell what’s wrong?
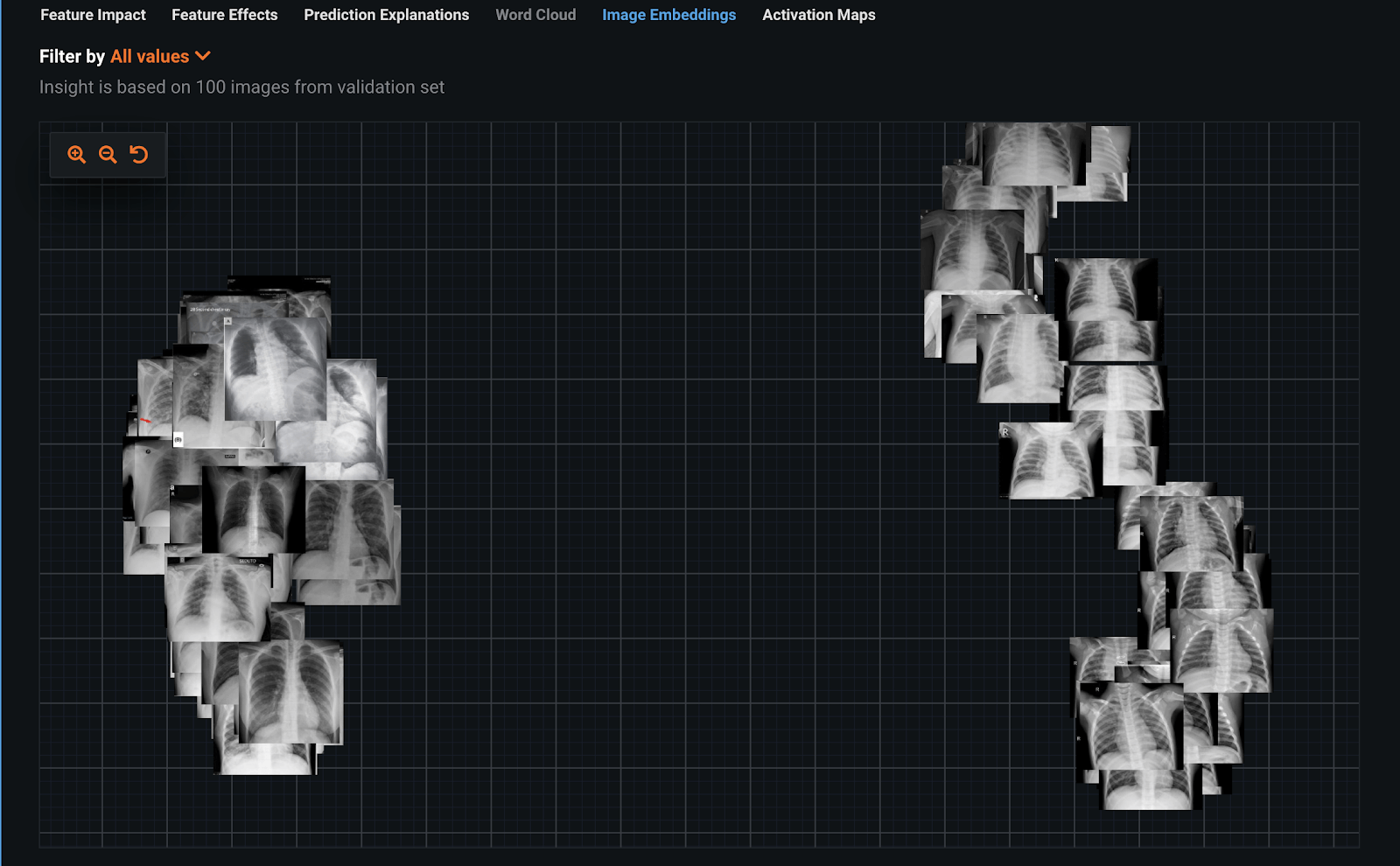
Example: detecting COVID-19 from chest scans
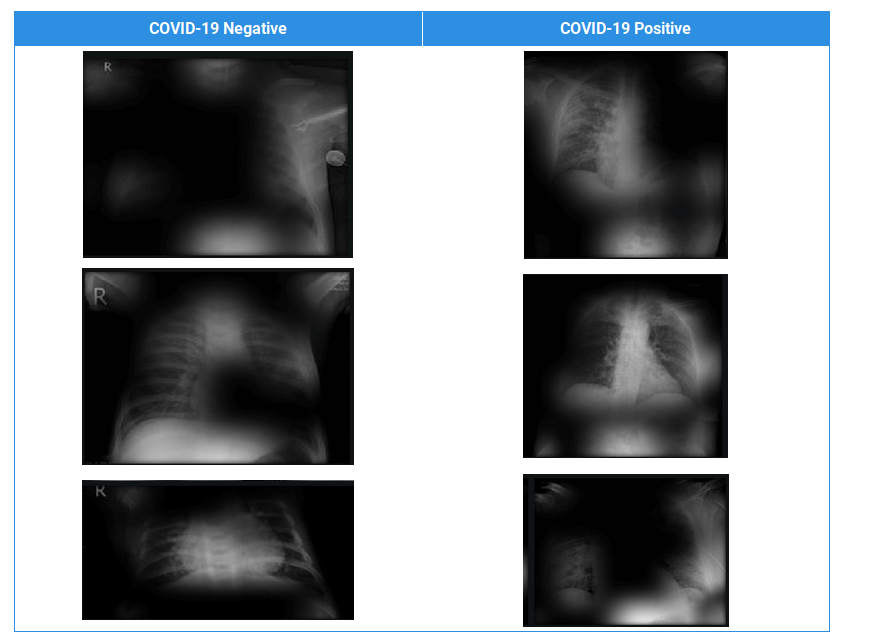
Let’s look at activations map and see more in detail
- Get final layer’s output after activation (ReLU) and plot back on input
Beware of similar samples across sets

 (2F08 “Fear of Flying”)
(2F08 “Fear of Flying”)
Another imaging example
Another imaging example
Another imaging example
Sad ending :(

Another example, protein structure prediction
- For some reason most researchers try to split train/development/test by sequence similarity
- If two proteins have <25% identical amino acids, they are deemed different enough
- But protein families/superfamilies contain many proteins that share no detectable sequence similarity
- Sequence similarity is not the right metric!

Your model is only as good as your data
Reasons why one of my networks wouldn’t work:
- Labels were wrong (label for amino acid n was assigned to amino acid n+1)
- The actual target sequence was missing from the multiple sequence alignment
- Inputs weren’t correctly scaled/normalized
- Script to convert 3-letter code amino acid to one letter (LYS -> K) didn’t work as expected
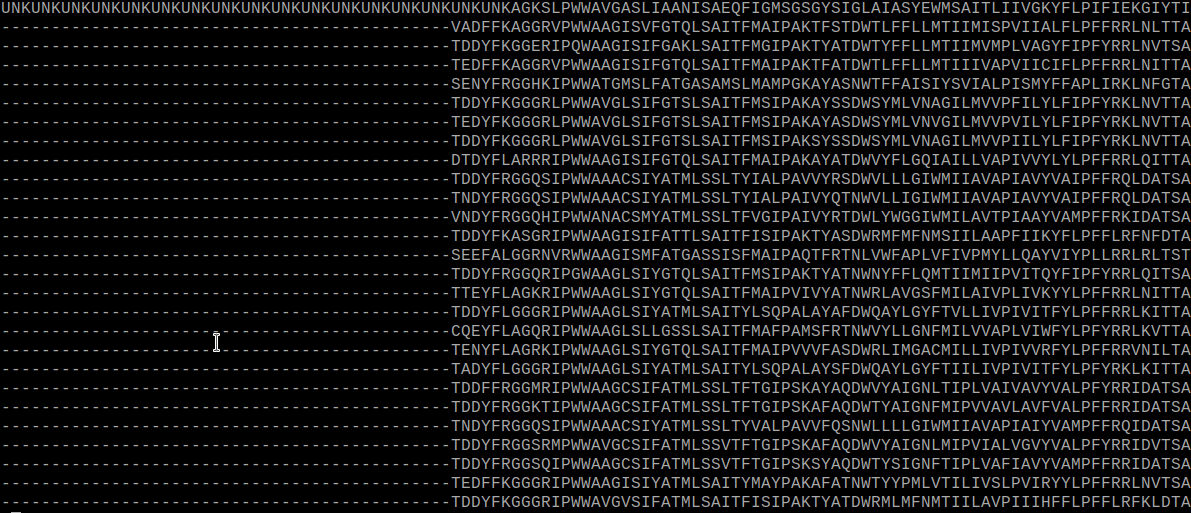
NNs are robust
They will “kind of” work even when some labels are incorrect, but it is going to be very tricky to understand if and what is wrong
- Before training:
- Plot data distributions
- Test all data preparation scripts
- Manually look at data files
- Check labels for mistakes, unbalancedness
- While training:
- Look at badly predicted samples
- Be paranoid when something doesn’t work well, even more when it works surpisingly well

Transfer learning
- Train a deep classifier on a large dataset
- The bottom (first) layers of the network learn to extract relevant features
- The top (last) layers learn to classify
- Keep the bottom layers, freeze them (so that the weight can’t change anymore)
- Re-initialize the top layers weights randomly
- Retrain the network on the small dataset so that only the top layers weights are now trained