Convolutional Neural Networks for Image Segmentation
Localisation, detection, and segmentation
08-May-2026
CNNs for computer vision

Some of the material from this lecture comes from online courses of Charles Ollion and Olivier Grisel - Master Datascience Paris Saclay. CC-By 4.0 license.
Beyond image classification
Classification answers “what is in this image?” — but real-world vision asks more:
- Where is the object? (localisation)
- How many objects, and which class is each one? (detection)
- Which pixels belong to which object? (segmentation)

From classification to dense prediction

- Same backbone (CNN/ViT) — but with task-specific heads
- The pretrained classifier is the starting point in (almost) every modern approach
Localisation

- Single object per image
- Predict coordinates of a bounding box
(x, y, w, h) - Evaluate via Intersection over Union (IoU)
Localisation as regression

Classification + Localisation

- Use a pre-trained CNN on ImageNet (e.g. ResNet)
- The “localisation head” is trained separately with regression
- At test time, use both heads
C classes, 4 output dimensions (1 box)
Predict exactly N objects: predict (N \times 4) coordinates and (N \times K) class scores
YOLO (You Only Look Once)
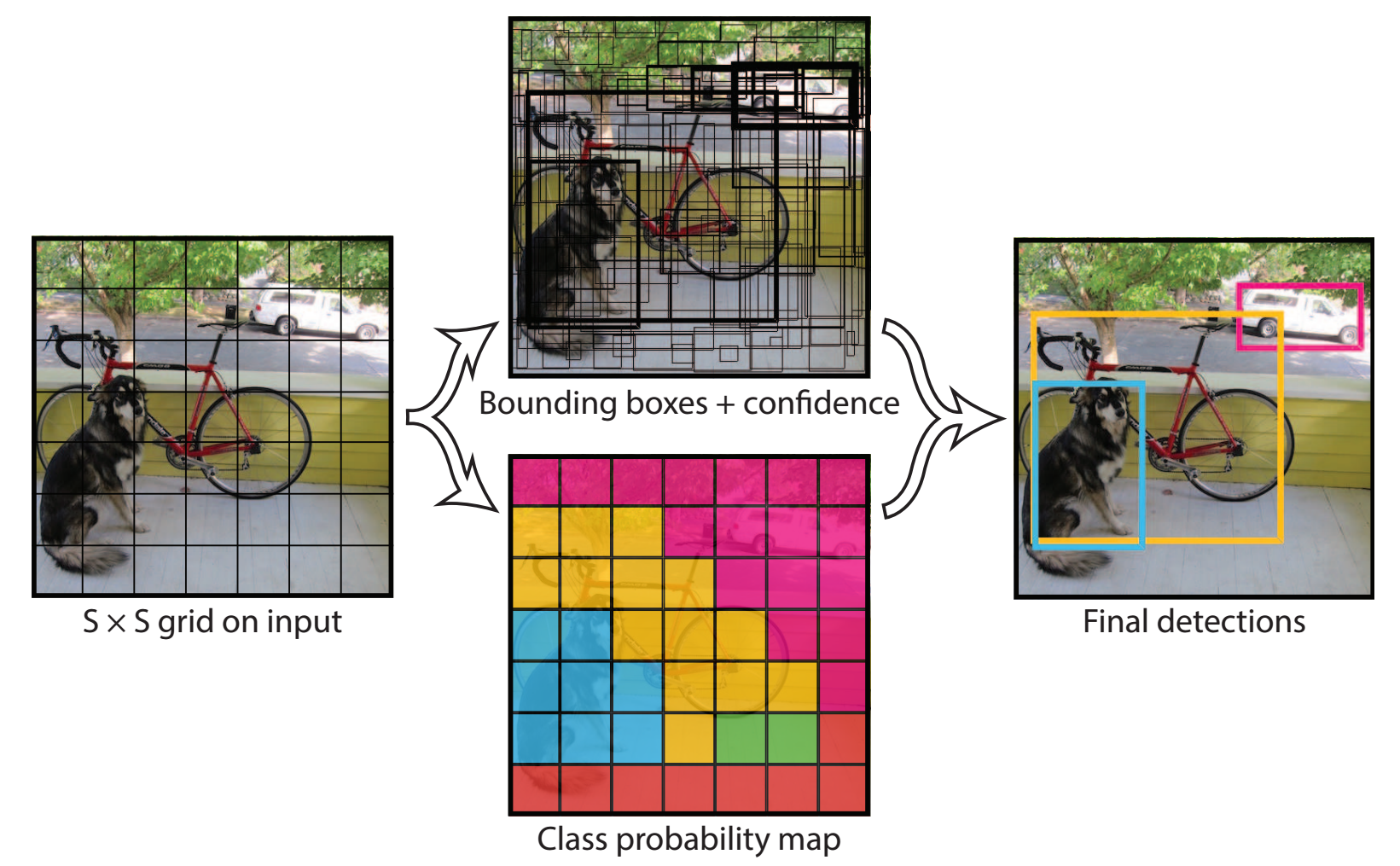
For each cell of the S \times S grid predict:
- B boxes and confidence scores C (5 \times B values) + classes c
- Final detections: C_j \cdot \mathrm{prob}(c) > \text{threshold}
- One CNN, one forward pass — real-time detection
- Globally processes the entire image at once
Redmon et al. “You only look once: Unified, real-time object detection.” CVPR 2016. The single-shot grid is still the conceptual core, even if modern YOLO versions add anchor-free heads, FPN, decoupled heads, etc.
RetinaNet
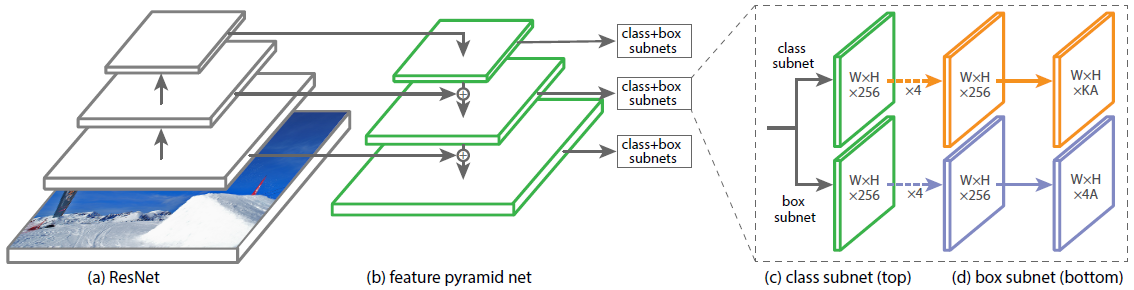
Single stage detector with:
- Multiple scales through a Feature Pyramid Network
- More than 100K boxes proposed
- Focal loss to manage imbalance between background and real objects
See this post for more information.
Lin, Tsung-Yi, et al. “Focal loss for dense object detection.” ICCV 2017.
Faster R-CNN
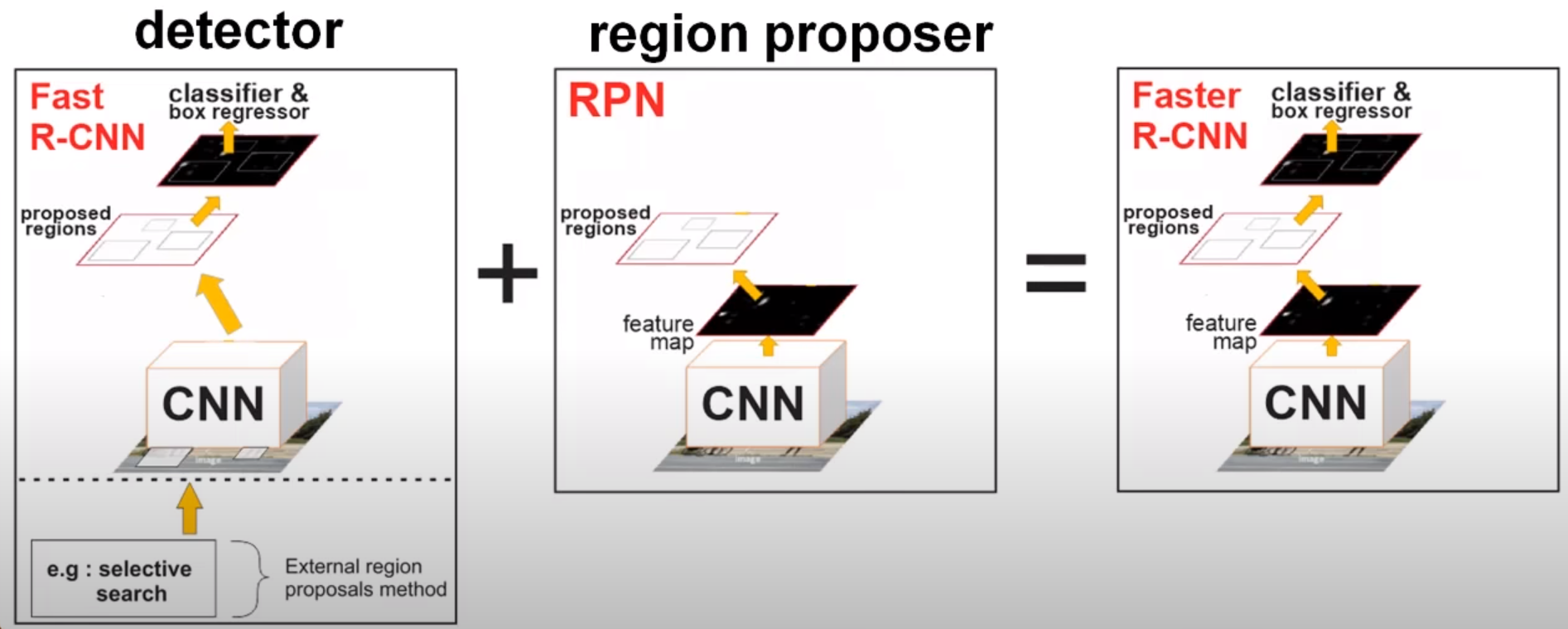
- Replace Selective Search with RPN, train jointly
- Region proposal is translation invariant, compared to YOLO
Ren, Shaoqing, et al. “Faster r-cnn: Towards real-time object detection with region proposal networks.” NIPS 2015
Segmentation
Output a class map for each pixel (here: dog vs background).

- Instance segmentation: specify each object instance as well (two dogs have different instances)
- This can be done through object detection + segmentation
Convolutionize
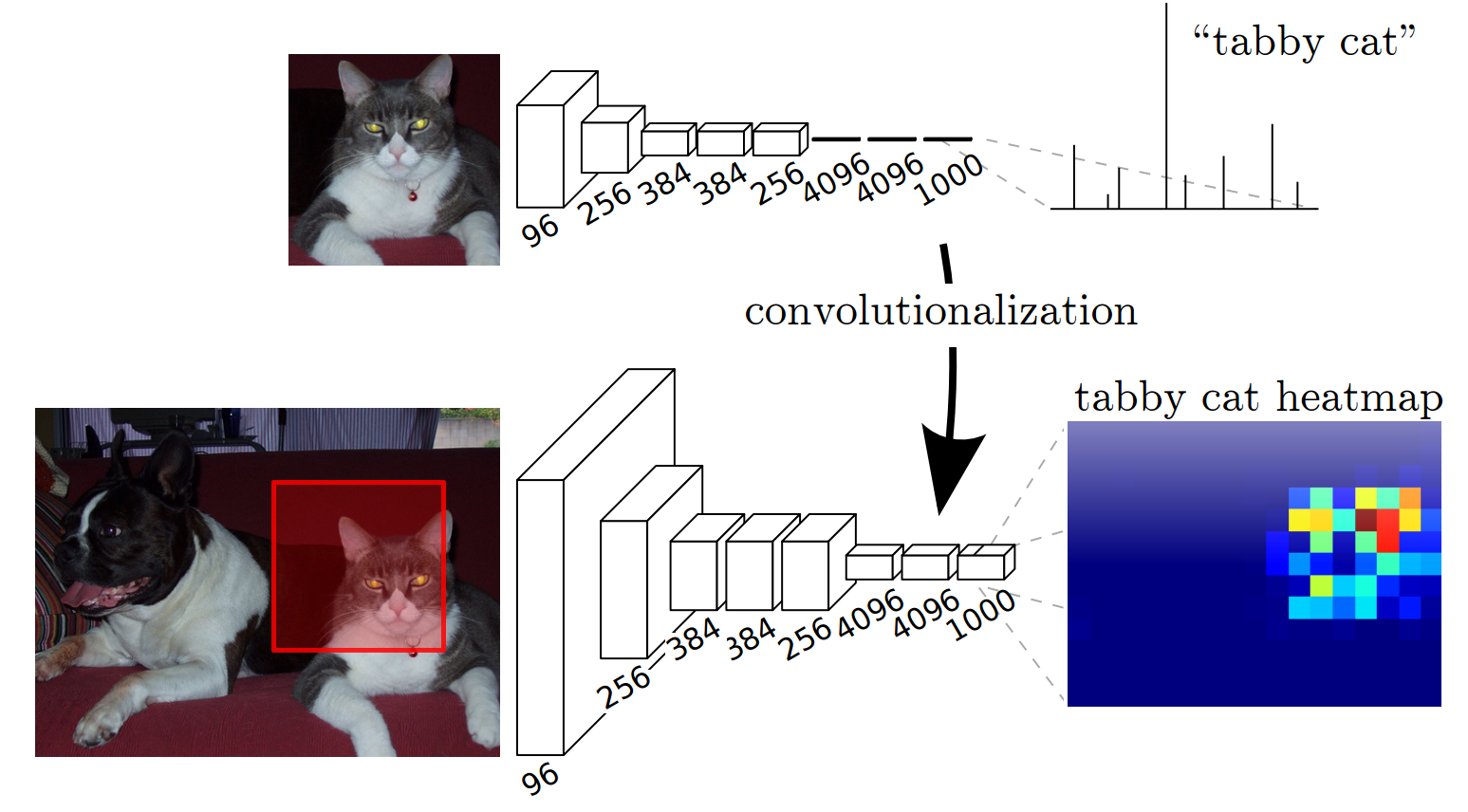
- Slide the network with an input of
(224, 224)over a larger image. Output of varying spatial size - Convolutionize: change Dense
(4096, 1000)to 1 \times 1 Convolution, with4096, 1000input and output channels - Gives a coarse segmentation (no extra supervision)
Long, Jonathan, et al. “Fully convolutional networks for semantic segmentation.” CVPR 2015
Fully Convolutional Network
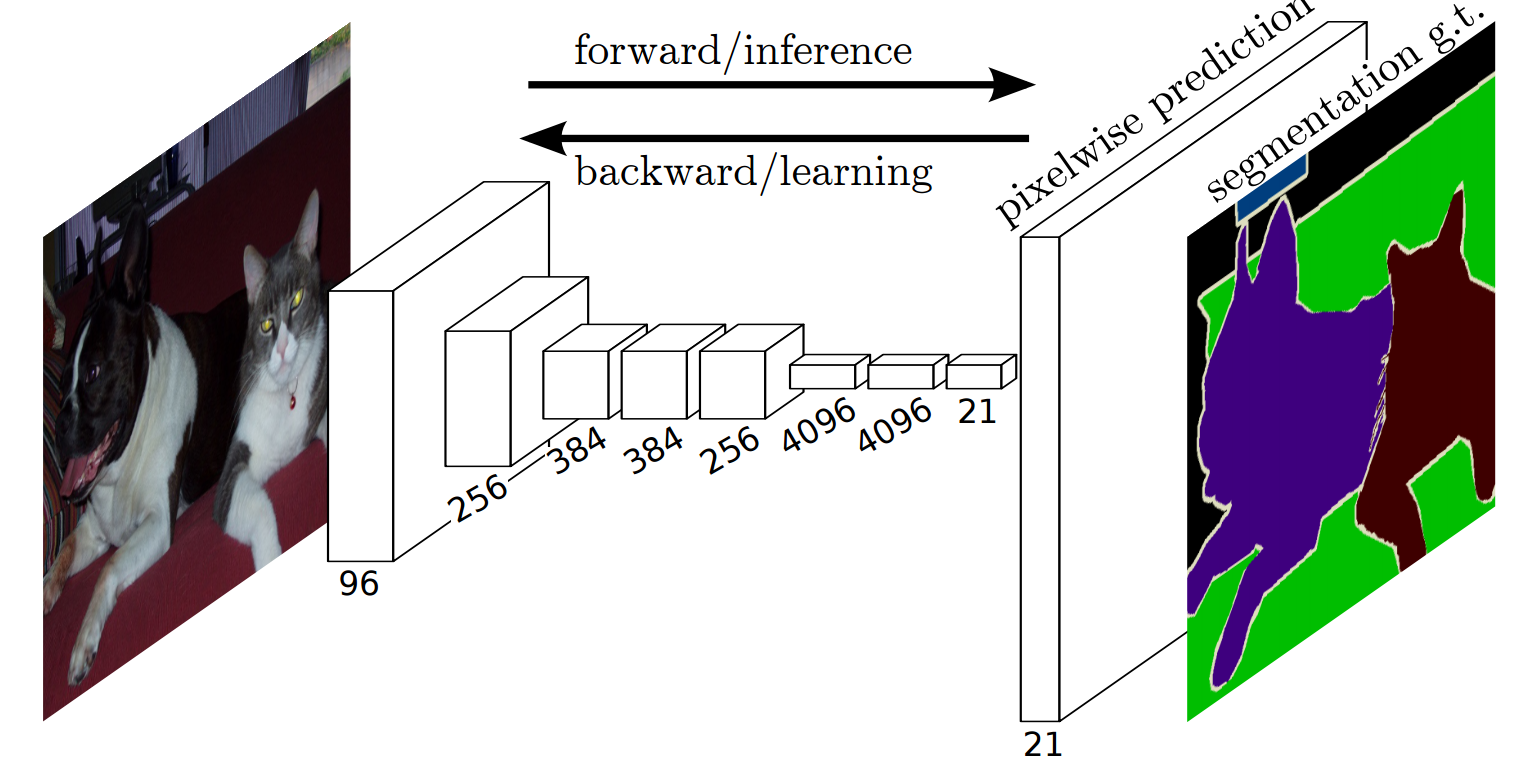
- Predict / backpropagate for every output pixel
- Aggregate maps from several convolutions at different scales for more robust results
Long, Jonathan, et al. “Fully convolutional networks for semantic segmentation.” CVPR 2015
Deconvolution
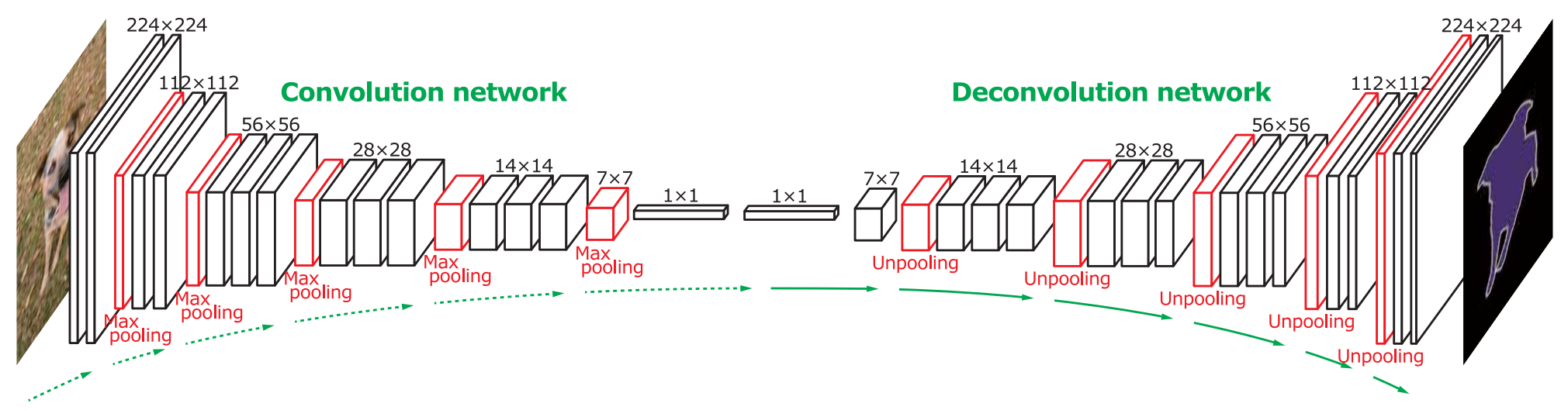
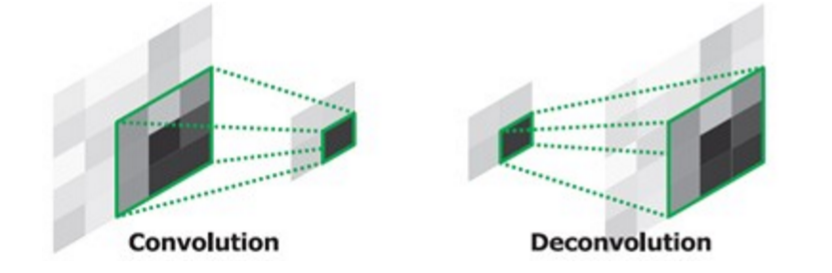
“Deconvolution”: transposed convolutions
Noh, Hyeonwoo, et al. “Learning deconvolution network for semantic segmentation.” ICCV 2015
U-Net

- Symmetric encoder–decoder with skip connections that concatenate features from the contracting path to the expanding path
- Trains well on small datasets with heavy augmentation
- Fully convolutional → arbitrary input sizes at inference
- The default architecture for biomedical and microscopy segmentation — directly relevant to the lab
Ronneberger, Fischer, Brox. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” MICCAI 2015. Skip connections concatenate (not add, as in ResNet) to preserve spatial detail through the bottleneck.
Mask R-CNN
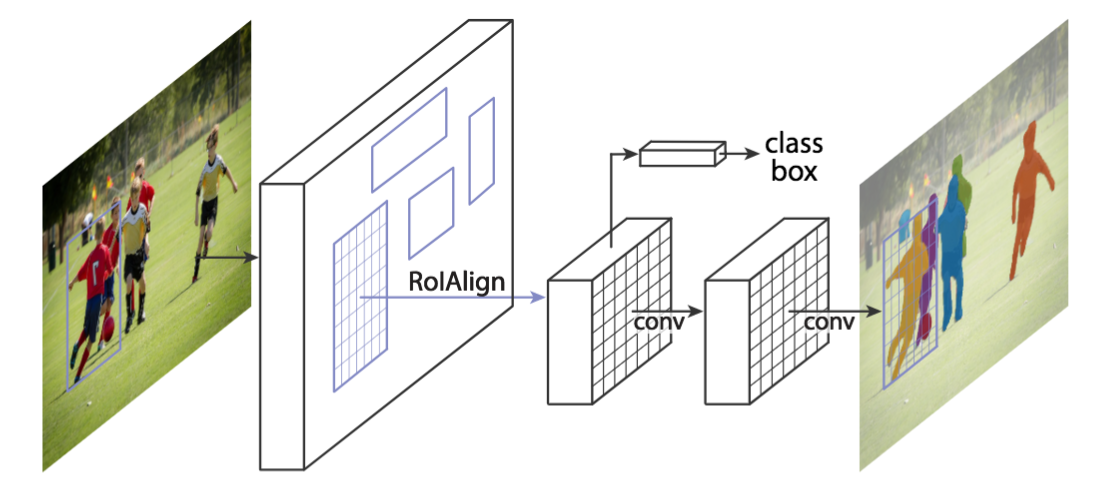
Faster R-CNN architecture with a third, binary mask head.
K. He et al. Mask Region-based Convolutional Network (Mask R-CNN) NIPS 2017
Mask R-CNN: Results

- Mask results are still coarse (low mask resolution)
- Excellent instance generalization
K. He et al. Mask R-CNN. NIPS 2017
Summary
- Localisation: regression heads on a CNN backbone for (x, y, w, h)
- Detection: single-stage (YOLO, RetinaNet) vs. two-stage (Faster R-CNN); modern YOLO is a one-line
pip install - Segmentation: encoder–decoder with skip connections, U-Net is the workhorse for biomedical imaging
- Train it right: pretrained encoder + BCE + Dice loss + augmentation
- Instance segmentation: Mask R-CNN, then DETR / Mask2Former
- Today: foundation models (SAM 2, Grounding DINO) often give zero-shot masks.
Next: hands-on segmentation lab on biological images, where U-Net + Dice loss is the natural baseline.