import torch.nn as nn
#Add your model here
model = ...
...
print(model)Lab session: your first Neural Networks
PyTorch intro exercises
PyTorch intro exercises
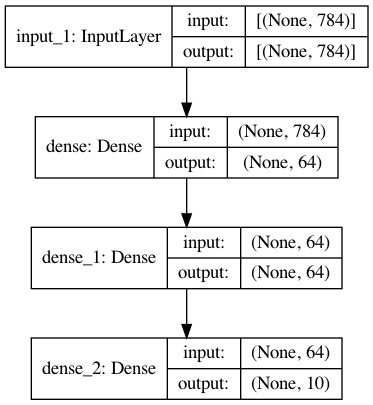
1. Build a simple sequential model
- A model to classify clinical variables into a number possible outcomes
- Can you build a sequential model to reproduce the graph shown in the figure?
- Choose whatever activations you want, wherever possible
- How many outcomes/classes are we predicting?
2. Build a better XOR classifier
Given the model seen at lecture, how do we make a better classifier (higher accuracy)?
- More layers? More neurons?
- Generate more data?
- More epochs?
- Different batch size?
- Different optimizer?
- It’s up to you! Let’s see who does best on validation
Only for Tuesday’s session:
- Different activations?
- Add Dropout? How large?
Plotting and training helper functions:
from typing import Optional
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
import torchmetrics
class LivePlot():
def __init__(self, left_label="Loss", right_label="Accuracy"):
self.fig = go.FigureWidget(
make_subplots(specs=[[{"secondary_y": True}]])
)
self.fig.update_yaxes(title_text=left_label, secondary_y=False)
self.fig.update_yaxes(title_text=right_label, secondary_y=True)
self.plot_indices = {}
self.trace_secondary = {}
display(self.fig)
self.limits = [0, 0]
self.current_x = 0
def report(self, name: str, value: float, secondary_y: bool = False):
try:
plot_index = self.plot_indices[name]
except KeyError:
plot_index = len(self.fig.data)
self.fig.add_scatter(
y=[], x=[], name=name,
secondary_y=secondary_y
)
self.plot_indices[name] = plot_index
self.trace_secondary[name] = secondary_y
self.fig.data[plot_index].y += (value,)
self.fig.data[plot_index].x += (self.current_x,)
def increment(self, n_ticks: int):
self.limits[1] += n_ticks
self.fig.update_layout(xaxis_range=self.limits)
def set_limit(self, n_ticks: int):
self.limits[1] = n_ticks
self.fig.update_layout(xaxis_range=self.limits)
def tick(self, n_ticks: Optional[int] = None):
if n_ticks is None:
n_ticks = 1
self.current_x += n_ticks
def train(*,
model: torch.nn.Module,
train_loader: DataLoader,
dev_loader: DataLoader,
optimizer: torch.optim.Optimizer,
criterion: torch.nn.Module,
max_epochs: int,
metric: Optional[torchmetrics.metric] = None,
device: Optional[torch.device] = None,
liveplot: Optional[LivePlot]=None):
if device is None:
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
for epoch in range(max_epochs):
training_loss_acc = 0
training_examples = 0
model.train()
for i, batch in enumerate(train_loader):
optimizer.zero_grad()
x_batch, y_batch = batch
x_batch = x_batch.to(device)
y_hat = model(x_batch)
loss = criterion(y_hat, y_batch.to(device))
loss.backward()
optimizer.step()
training_loss_acc += loss.item()
training_examples += x_batch.size(0)
model.eval()
with torch.no_grad():
dev_loss_acc = 0
dev_examples = 0
dev_accuracy = 0
for i, batch in enumerate(dev_loader):
x_batch, y_batch = batch
x_batch = x_batch.to(device)
y_hat = model(x_batch)
dev_loss_acc += criterion(y_hat, y_batch.to(device)).item()
dev_examples += x_batch.size(0)
if metric:
dev_accuracy += metric(torch.argmax(y_hat, -1), y_batch)
if liveplot is not None:
liveplot.tick() # Update the liveplot time
liveplot.report("Training loss", training_loss_acc / training_examples)
liveplot.report("Development loss", dev_loss_acc / dev_examples)
if metric:
liveplot.report("Development accuracy", dev_accuracy / (i+1), secondary_y=True)Data generation step:
import numpy as np
# Generate XOR data
data = np.random.random((10000, 3)) - 0.5
labels = np.zeros((10000))
labels[np.where(np.logical_xor(np.logical_xor(data[:,0] > 0, data[:,1] > 0), data[:,2] > 0))] = 1
#let's print some data and the corresponding label to check that they match the table above
for x in range(3):
print("{0: .2f} xor {1: .2f} xor {2: .2f} equals {3:}".format(data[x,0], data[x,1], data[x,2], labels[x]))The baseline network to improve:
class MLP(torch.nn.Module):
def __init__(self, input_dim, output_dim, hidden_dim):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, output_dim),
)
def forward(self, x):
y_hat = self.layers(x)
return y_hat
# model from MLP class
model = MLP(input_dim=3, output_dim=2, hidden_dim=3)
epochs = 20
# define optimizer and loss function
learning_rate = 1e-3
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
accuracy = torchmetrics.Accuracy(task='multiclass', num_classes=2, top_k=1)
# convert numpy arrays to torch tensors
tdata = torch.Tensor(data)
tlabels = torch.Tensor(labels).long()
dataset = TensorDataset(tdata, tlabels)
# split the data randomly
total_samples = data.shape[0]
train_samples = int(total_samples * 0.9)
train_set, dev_set = torch.utils.data.random_split(dataset, [train_samples, total_samples-train_samples])
# shuffle data at training time
train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
dev_loader = DataLoader(dev_set, batch_size=32)
# Setup plot
liveplot = LivePlot()
liveplot.increment(epochs)
train(model=model,
train_loader=train_loader,
dev_loader=dev_loader,
optimizer=optimizer,
criterion=criterion,
metric=accuracy,
max_epochs=epochs,
liveplot=liveplot,
device=torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu'))#Add your code here3. Build a regression model
- Take the Boston housing dataset (http://lib.stat.cmu.edu/datasets/boston)
- Records a set of variables for a set of houses in Boston, including among others:
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- Can we use these variables to predict the value of a house (in tens of thousands of dollars)?
Download the data:
!mkdir -p data
!wget -P ./data/ https://github.com/selva86/datasets/raw/refs/heads/master/BostonHousing.csv!ls data/Load the data with pandas:
import torch
import torch.nn as nn
from sklearn.preprocessing import StandardScaler # hint
data = pd.read_csv("data/BostonHousing.csv")
print(data.head())
data = np.array(data)
print(f"Data shape is: {data.shape}")
train_samples = int(data.shape[0] * 0.9)
train_x = data[:train_samples, :13]
train_y = data[:train_samples, 13:]
dev_x = data[train_samples:, :13]
dev_y = data[train_samples:, 13:]
train_set = TensorDataset(torch.Tensor(train_x), torch.Tensor(train_y))
dev_set = TensorDataset(torch.Tensor(dev_x), torch.Tensor(dev_y))
# shuffle data at training time
train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
dev_loader = DataLoader(dev_set, batch_size=32)class MLP(torch.nn.Module):
def __init__(self, input_dim, output_dim, hidden_dim):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, output_dim),
)
def forward(self, x):
y_hat = self.layers(x)
return y_hat
# model from MLP class
model = ...
epochs = ...
# define optimizer and loss function
optimizer = ...
# https://docs.pytorch.org/docs/stable/nn.html#loss-functions
criterion = ...
# Setup plot
liveplot = LivePlot()
liveplot.increment(epochs)
train(model=model,
train_loader=train_loader,
dev_loader=dev_loader,
optimizer=optimizer,
criterion=criterion,
max_epochs=epochs,
liveplot=liveplot,
device=torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu'))4. The IMDB movie review sentiment dataset
This dataset contains 50k reviews for movies in IMDB, split into a train and test set of equal size. You want to predict whether the review is positive or negative.
Download the raw data and read it into a data structure:
!mkdir -p data
!wget -P ./data https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -C ./data -zxf ./data/aclImdb_v1.tar.gzLoad the dataset:
import os
import glob
def imdb_dataset(directory='data/',
train=False,
test=False,
train_directory='train',
test_directory='test',
extracted_name='aclImdb',
check_files=['aclImdb/README'],
sentiments=['pos', 'neg']):
"""
Returns:
:class:`tuple` of :class:`iterable` or :class:`iterable`:
Returns between one and all dataset splits (train, dev and test) depending on if their
respective boolean argument is ``True``.
Example:
[{
'text': 'For a movie that gets no respect there sure are a lot of memorable quotes...',
'sentiment': 'pos'
}, {
'text': 'Bizarre horror movie filled with famous faces but stolen by Cristina Raines...',
'sentiment': 'pos'
}]
"""
ret = []
splits = [
dir_ for (requested, dir_) in [(train, train_directory), (test, test_directory)]
if requested
]
for split_directory in splits:
full_path = os.path.join(directory, extracted_name, split_directory)
examples = []
for sentiment in sentiments:
for filename in glob.iglob(os.path.join(full_path, sentiment, '*.txt')):
with open(filename, 'r', encoding="utf-8") as f:
text = f.readline()
examples.append({
'text': text,
'sentiment': sentiment,
})
ret.append(examples)
if len(ret) == 1:
return ret[0]
else:
return tuple(ret)
train_data = imdb_dataset(train=True)len(train_data[0]['text'])How do we build a predictor for this task?
...