import numpy as np
import pandas as pd
import scanpy as sc
import matplotlib.pyplot as plt
import warnings
import os
import subprocess
warnings.simplefilter(action="ignore", category=Warning)
# verbosity: errors (0), warnings (1), info (2), hints (3)
sc.settings.verbosity = 3
# sc.logging.print_versions()
sc.settings.set_figure_params(dpi=80)
Note
Code chunks run Python commands unless it starts with %%bash, in which case, those chunks run shell commands.
1 Data preparation
First, let’s load all necessary libraries and the QC-filtered dataset from the previous step.
# download pre-computed data if missing or long compute
fetch_data = True
# url for source and intermediate data
path_data = "https://nextcloud.dc.scilifelab.se/public.php/webdav"
curl_upass = "zbC5fr2LbEZ9rSE:scRNAseq2025"
path_results = "data/covid/results"
if not os.path.exists(path_results):
os.makedirs(path_results, exist_ok=True)
path_file = "data/covid/results/scanpy_covid_qc.h5ad"
# if fetch_data is false and path_file doesn't exist
if fetch_data and not os.path.exists(path_file):
file_url = os.path.join(path_data, "covid/results_scanpy/scanpy_covid_qc.h5ad")
subprocess.call(["curl", "-u", curl_upass, "-o", path_file, file_url ])
adata = sc.read_h5ad(path_file)
adataAnnData object with n_obs × n_vars = 7332 × 19468
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'umap'
obsm: 'X_pca', 'X_umap'
obsp: 'connectivities', 'distances'Before variable gene selection we need to normalize and log transform the data. Then store the full matrix in the raw slot before doing variable gene selection.
# normalize to depth 10 000
sc.pp.normalize_total(adata, target_sum=1e4)
# log transform
sc.pp.log1p(adata)
# store normalized counts in the raw slot,
# we will subset adata.X for variable genes, but want to keep all genes matrix as well.
adata.raw = adata
adatanormalizing counts per cell
finished (0:00:00)
WARNING: adata.X seems to be already log-transformed.AnnData object with n_obs × n_vars = 7332 × 19468
obs: 'type', 'sample', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'pct_counts_hb', 'percent_mt2', 'n_counts', 'n_genes', 'percent_chrY', 'XIST-counts', 'S_score', 'G2M_score', 'phase', 'doublet_scores', 'predicted_doublets', 'doublet_info'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'n_cells'
uns: 'doublet_info_colors', 'hvg', 'log1p', 'neighbors', 'pca', 'phase_colors', 'sample_colors', 'umap'
obsm: 'X_pca', 'X_umap'
obsp: 'connectivities', 'distances'2 Feature selection
We first need to define which features/genes are important in our dataset to distinguish cell types. For this purpose, we need to find genes that are highly variable across cells, which in turn will also provide a good separation of the cell clusters.
# compute variable genes
sc.pp.highly_variable_genes(adata, min_mean=0.0125, max_mean=3, min_disp=0.5)
print("Highly variable genes: %d"%sum(adata.var.highly_variable))
#plot variable genes
sc.pl.highly_variable_genes(adata)
# subset for variable genes in the dataset
adata = adata[:, adata.var['highly_variable']]extracting highly variable genes
finished (0:00:02)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
Highly variable genes: 2656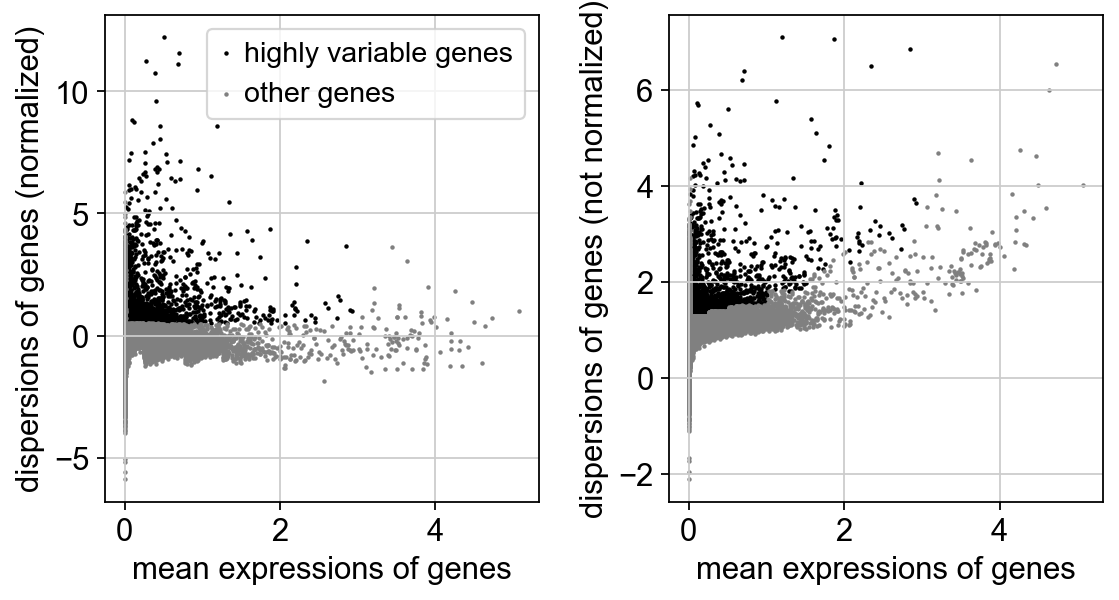
3 Z-score transformation
Now that the genes have been selected, we now proceed with PCA. Since each gene has a different expression level, it means that genes with higher expression values will naturally have higher variation that will be captured by PCA. This means that we need to somehow give each gene a similar weight when performing PCA (see below). The common practice is to center and scale each gene before performing PCA. This exact scaling called Z-score normalization is very useful for PCA, clustering and plotting heatmaps. Additionally, we can use regression to remove any unwanted sources of variation from the dataset, such as cell cycle, sequencing depth, percent mitochondria etc. This is achieved by doing a generalized linear regression using these parameters as co-variates in the model. Then the residuals of the model are taken as the regressed data. Although perhaps not in the best way, batch effect regression can also be done here. By default, variables are scaled in the PCA step and is not done separately. But it could be achieved by running the commands below:
#run this line if you get the "AttributeError: swapaxes not found"
# adata = adata.copy()
# regress out unwanted variables
sc.pp.regress_out(adata, ['total_counts', 'pct_counts_mt'])
# scale data, clip values exceeding standard deviation 10.
sc.pp.scale(adata, max_value=10)regressing out ['total_counts', 'pct_counts_mt']
sparse input is densified and may lead to high memory use
finished (0:00:29)4 PCA
Performing PCA has many useful applications and interpretations, which much depends on the data used. In the case of single-cell data, we want to segregate samples based on gene expression patterns in the data.
To run PCA, you can use the function pca().
sc.tl.pca(adata, svd_solver='arpack')computing PCA
with n_comps=50
finished (0:00:02)We then plot the first principal components.
# plot more PCS
sc.pl.pca(adata, color='sample', components = ['1,2','3,4','5,6','7,8'], ncols=2)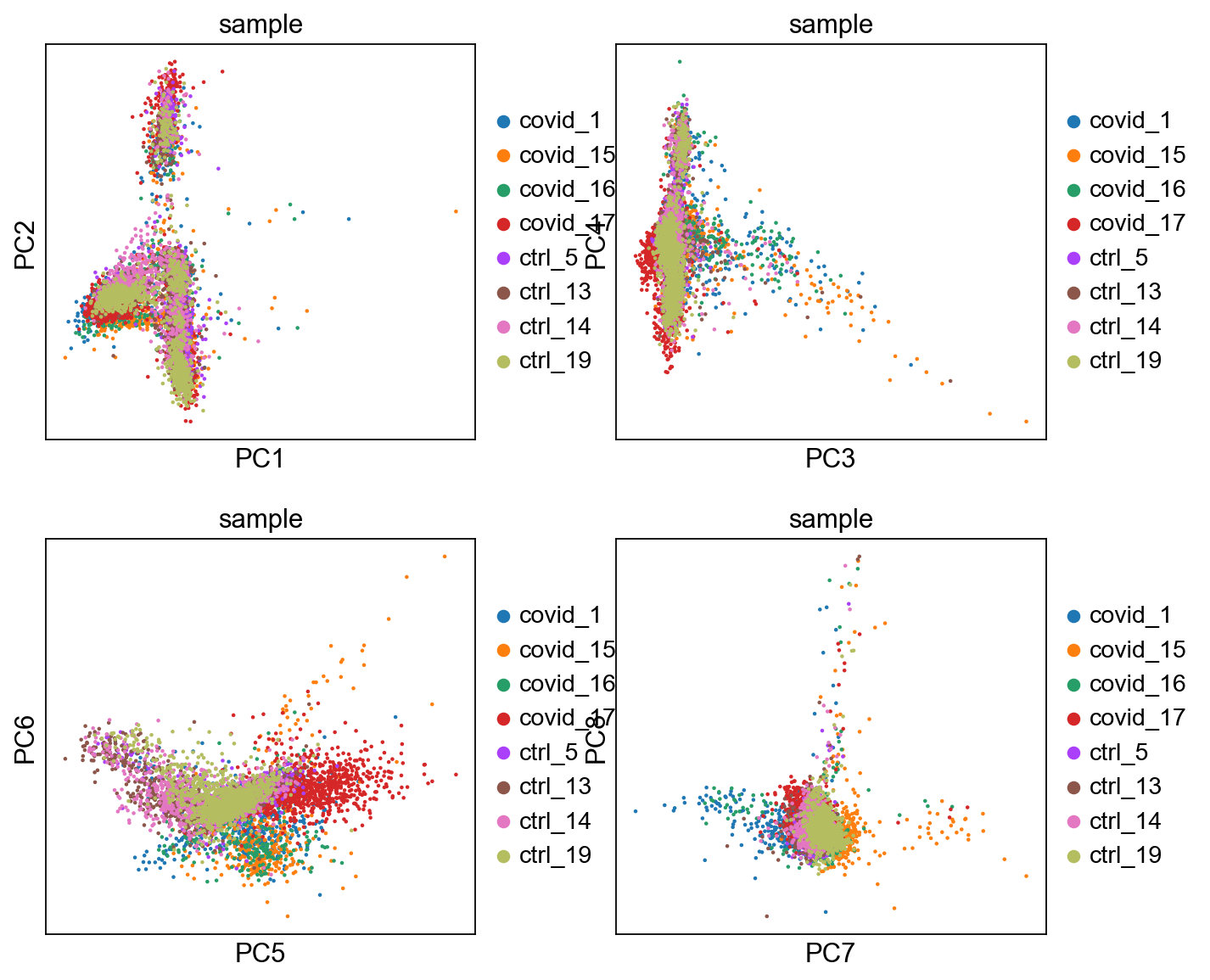
To identify genes that contribute most to each PC, one can retrieve the loading matrix information.
#Plot loadings
sc.pl.pca_loadings(adata, components=[1,2,3,4,5,6,7,8])
# OBS! only plots the positive axes genes from each PC!!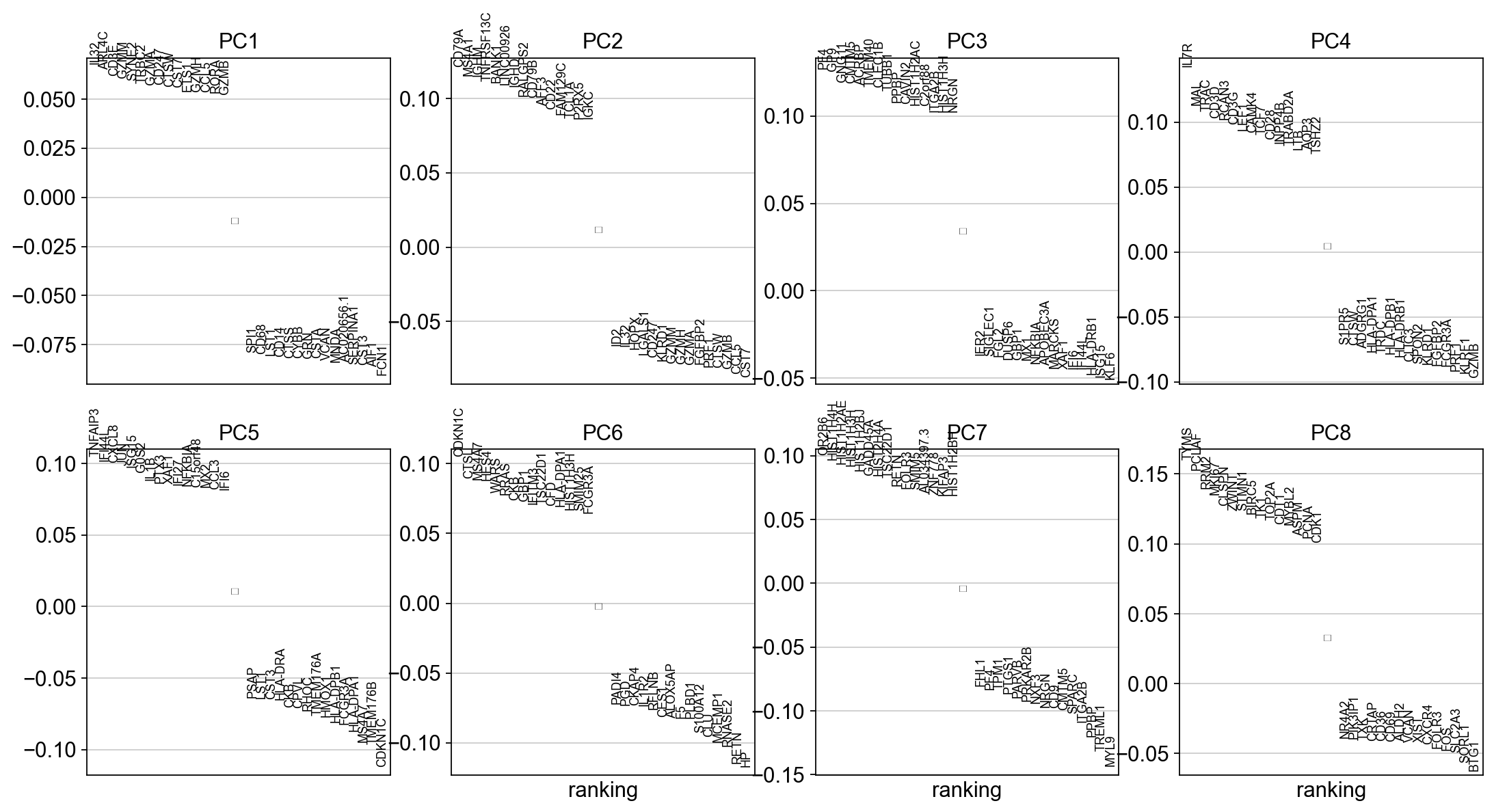
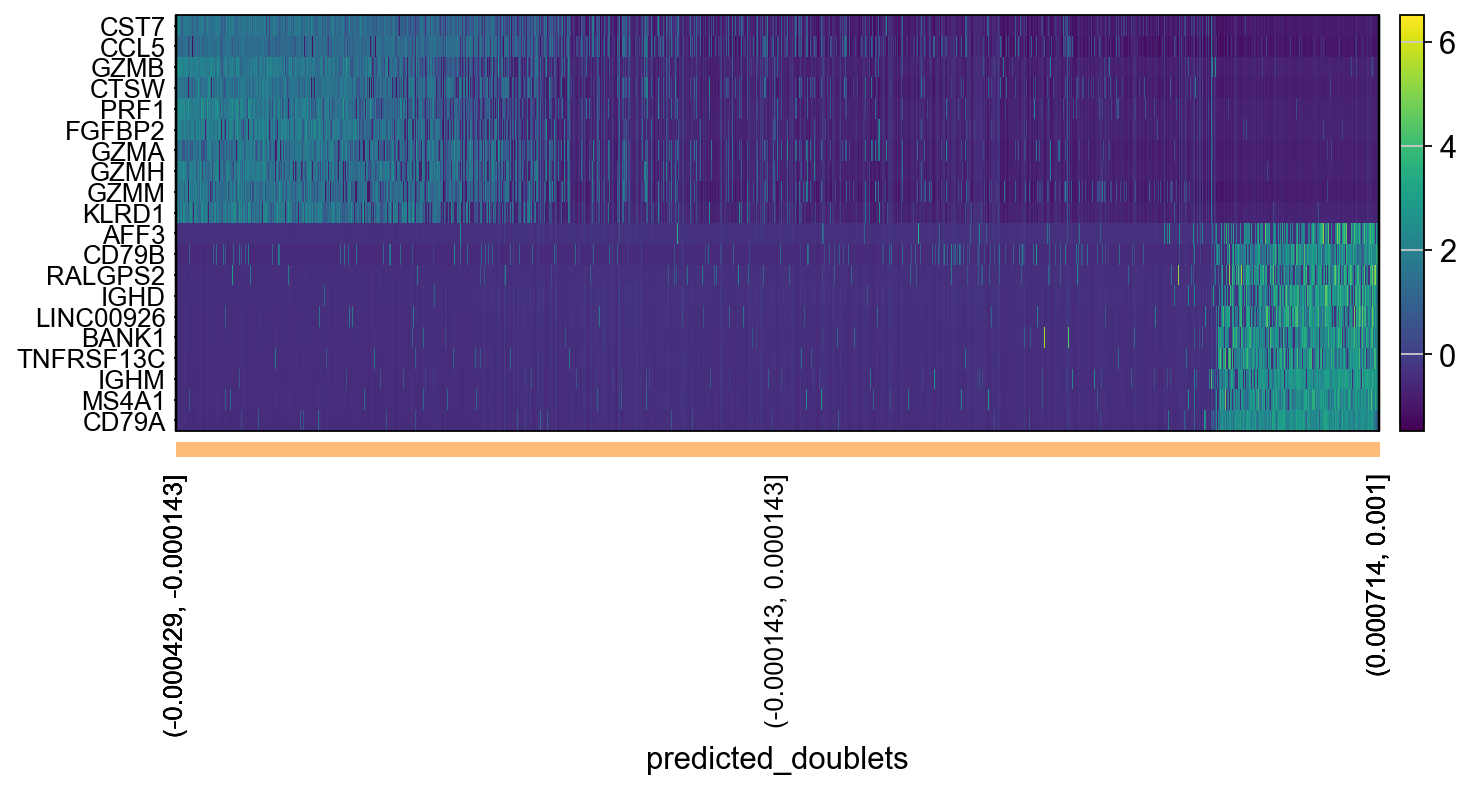
The function to plot loading genes only plots genes on the positive axes. Instead plot as a heatmaps, with genes on both positive and negative side, one per pc, and plot their expression amongst cells ordered by their position along the pc.
# adata.obsm["X_pca"] is the embeddings
# adata.uns["pca"] is pc variance
# adata.varm['PCs'] is the loadings
genes = adata.var['gene_ids']
for pc in [1,2,3,4]:
g = adata.varm['PCs'][:,pc-1]
o = np.argsort(g)
sel = np.concatenate((o[:10],o[-10:])).tolist()
emb = adata.obsm['X_pca'][:,pc-1]
# order by position on that pc
tempdata = adata[np.argsort(emb),]
sc.pl.heatmap(tempdata, var_names = genes[sel].index.tolist(), groupby='predicted_doublets', swap_axes = True, use_raw=False)
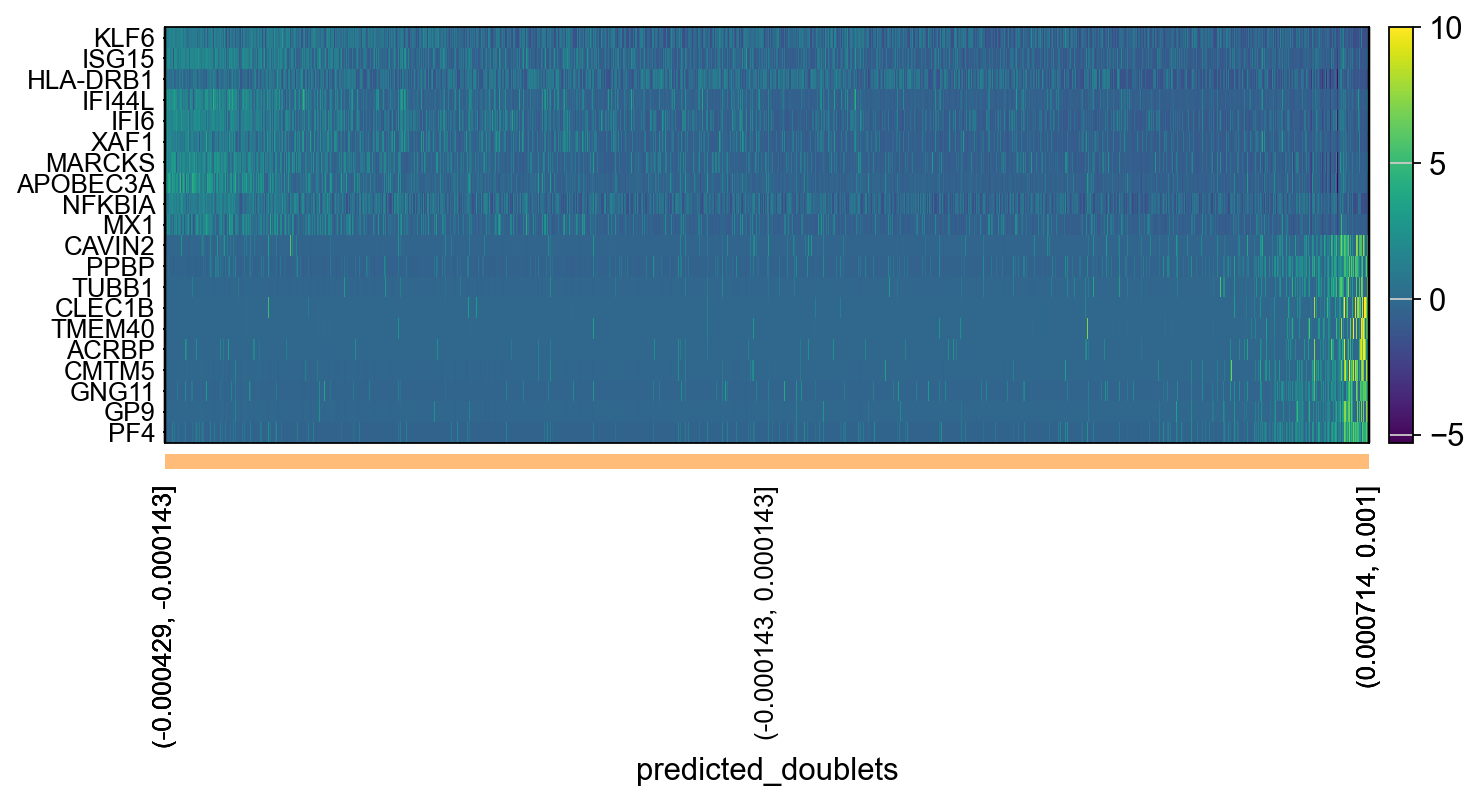
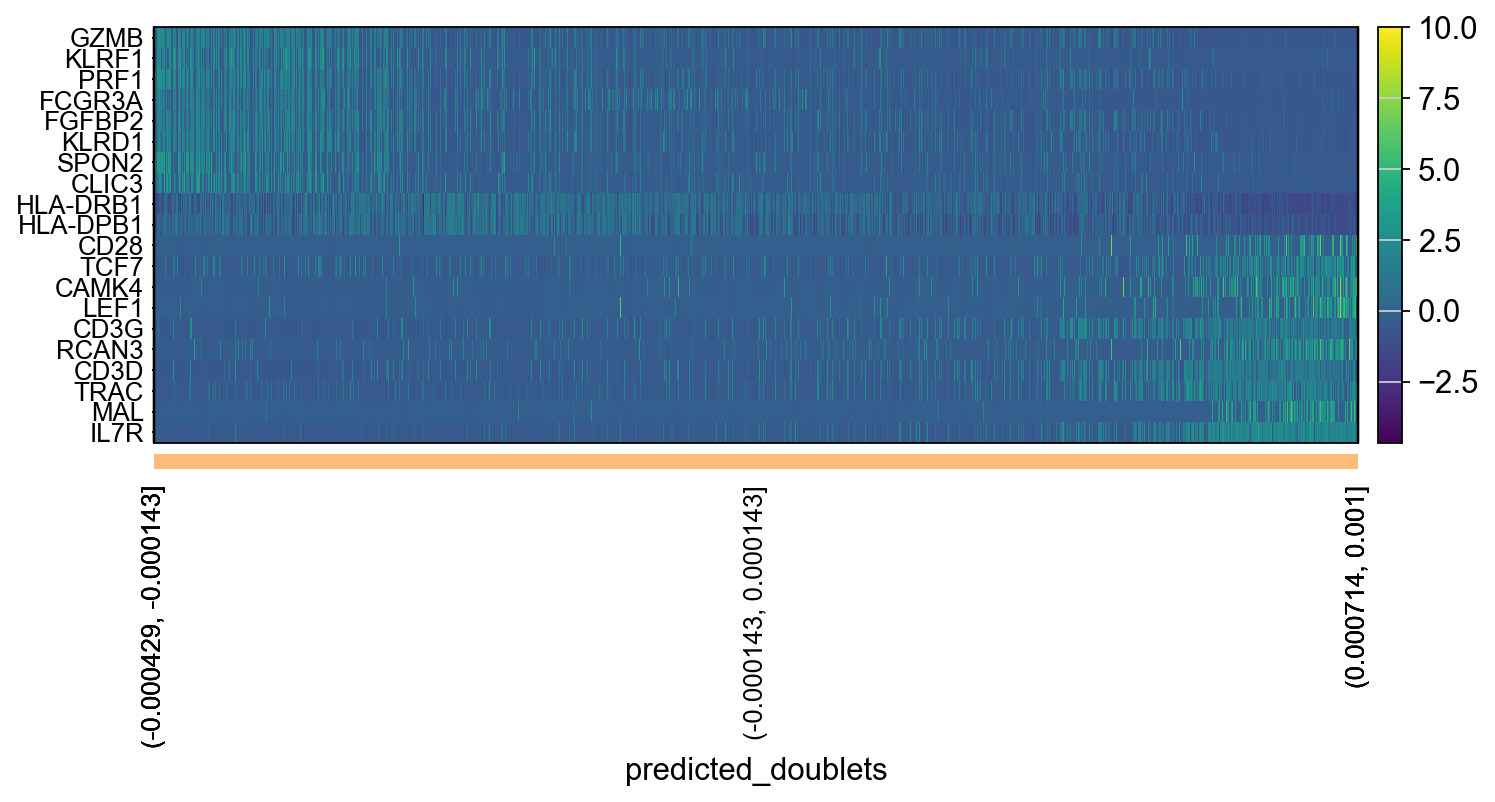
We can also plot the amount of variance explained by each PC.
sc.pl.pca_variance_ratio(adata, log=True, n_pcs = 50)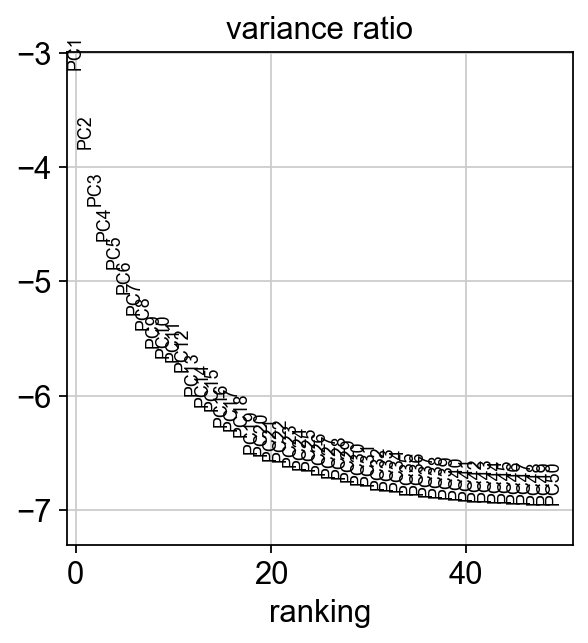
Based on this plot, we can see that the top 8 PCs retain a lot of information, while other PCs contain progressively less. However, it is still advisable to use more PCs since they might contain information about rare cell types (such as platelets and DCs in this dataset)
5 tSNE
We will now run BH-tSNE.
sc.tl.tsne(adata, n_pcs = 30)computing tSNE
using 'X_pca' with n_pcs = 30
using sklearn.manifold.TSNE
finished: added
'X_tsne', tSNE coordinates (adata.obsm)
'tsne', tSNE parameters (adata.uns) (0:00:48)We plot the tSNE scatterplot colored by dataset. We can clearly see the effect of batches present in the dataset.
sc.pl.tsne(adata, color='sample')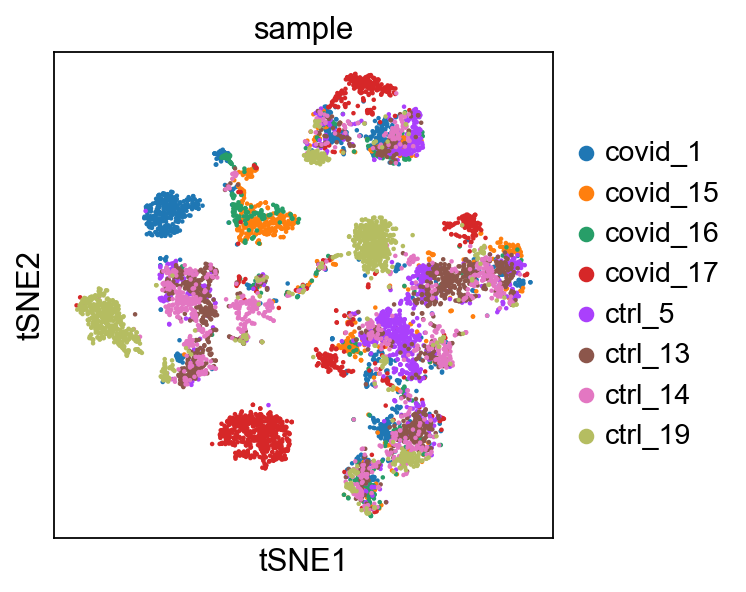
6 UMAP
The UMAP implementation in SCANPY uses a neighborhood graph as the distance matrix, so we need to first calculate the graph.
sc.pp.neighbors(adata, n_pcs = 30, n_neighbors = 20)computing neighbors
using 'X_pca' with n_pcs = 30
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:10)We can now run UMAP for cell embeddings.
sc.tl.umap(adata)
sc.pl.umap(adata, color='sample')computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm)
'umap', UMAP parameters (adata.uns) (0:00:12)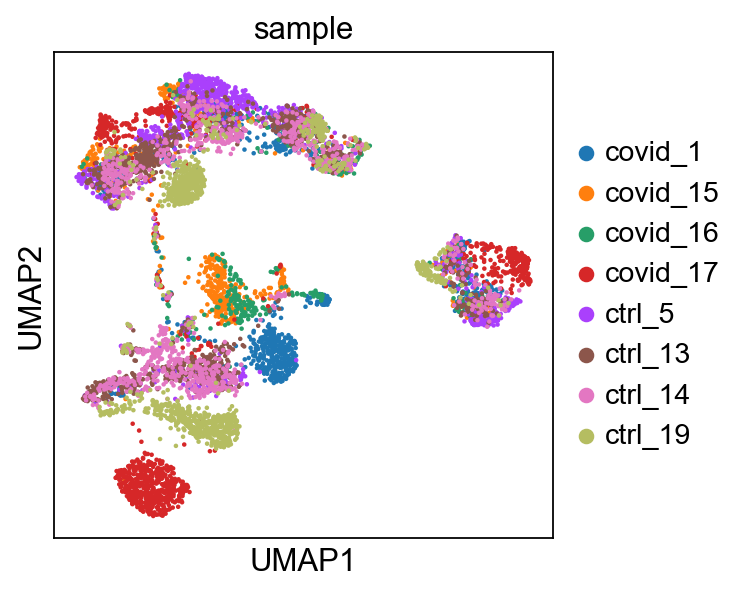
UMAP is plotted colored per dataset. Although less distinct as in the tSNE, we still see quite an effect of the different batches in the data.
# run with 10 components, save to a new object so that the umap with 2D is not overwritten.
umap10 = sc.tl.umap(adata, n_components=10, copy=True)
fig, axs = plt.subplots(1, 3, figsize=(10, 4), constrained_layout=True)
sc.pl.umap(adata, color='sample', title="UMAP",
show=False, ax=axs[0], legend_loc=None)
sc.pl.umap(umap10, color='sample', title="UMAP10", show=False,
ax=axs[1], components=['1,2'], legend_loc=None)
sc.pl.umap(umap10, color='sample', title="UMAP10",
show=False, ax=axs[2], components=['3,4'], legend_loc=None)
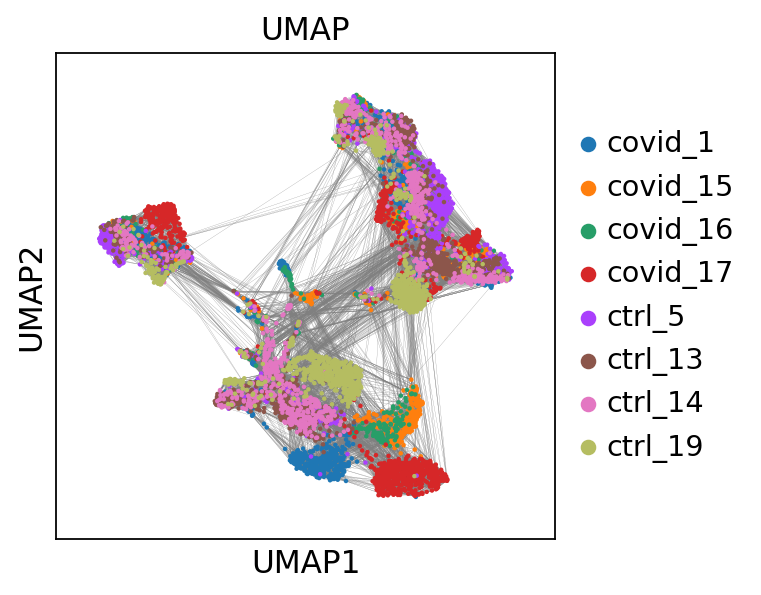
# we can also plot the umap with neighbor edges
sc.pl.umap(adata, color='sample', title="UMAP", edges=True)computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm)
'umap', UMAP parameters (adata.uns) (0:00:13)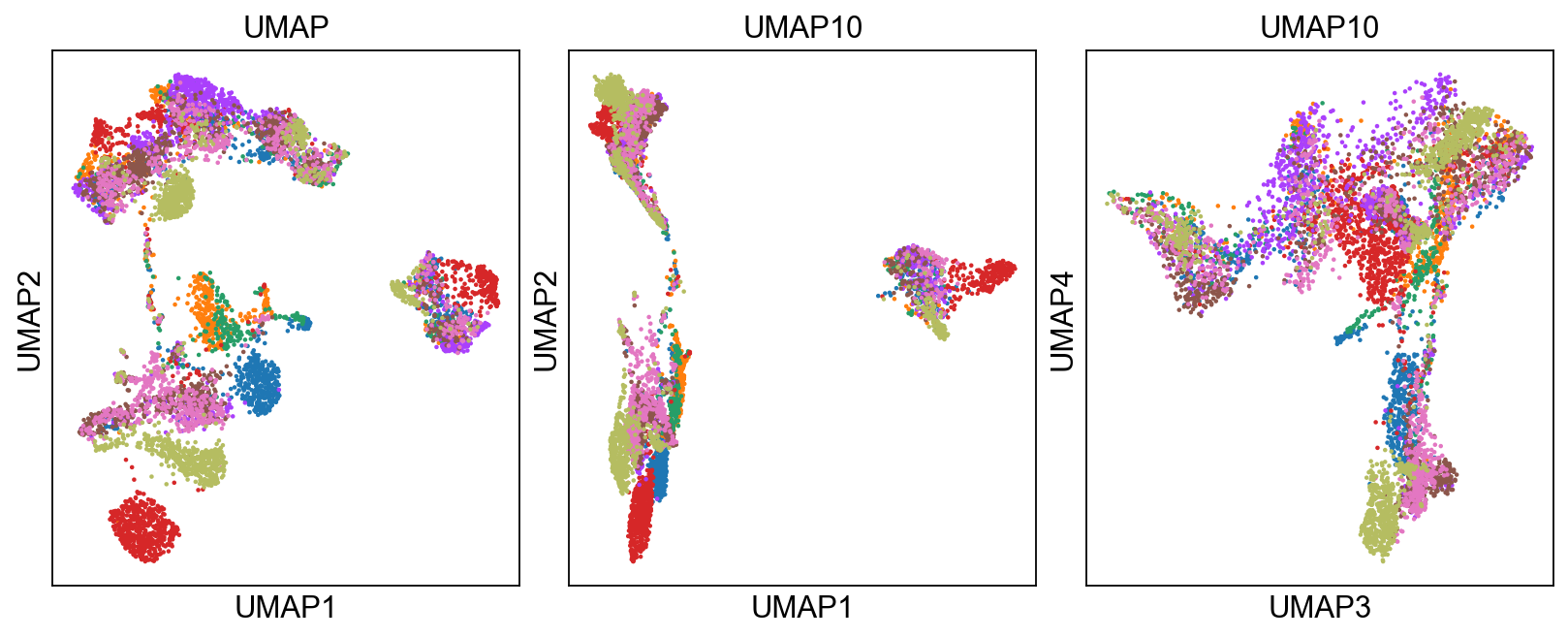
We can now plot PCA, UMAP and tSNE side by side for comparison. Have a look at the UMAP and tSNE. What similarities/differences do you see? Can you explain the differences based on what you learned during the lecture? Also, we can conclude from the dimensionality reductions that our dataset contains a batch effect that needs to be corrected before proceeding to clustering and differential gene expression analysis.
fig, axs = plt.subplots(2, 2, figsize=(10, 8), constrained_layout=True)
sc.pl.pca(adata, color='sample', components=['1,2'], ax=axs[0, 0], show=False)
sc.pl.tsne(adata, color='sample', components=['1,2'], ax=axs[0, 1], show=False)
sc.pl.umap(adata, color='sample', components=['1,2'], ax=axs[1, 0], show=False)<Axes: title={'center': 'sample'}, xlabel='UMAP1', ylabel='UMAP2'>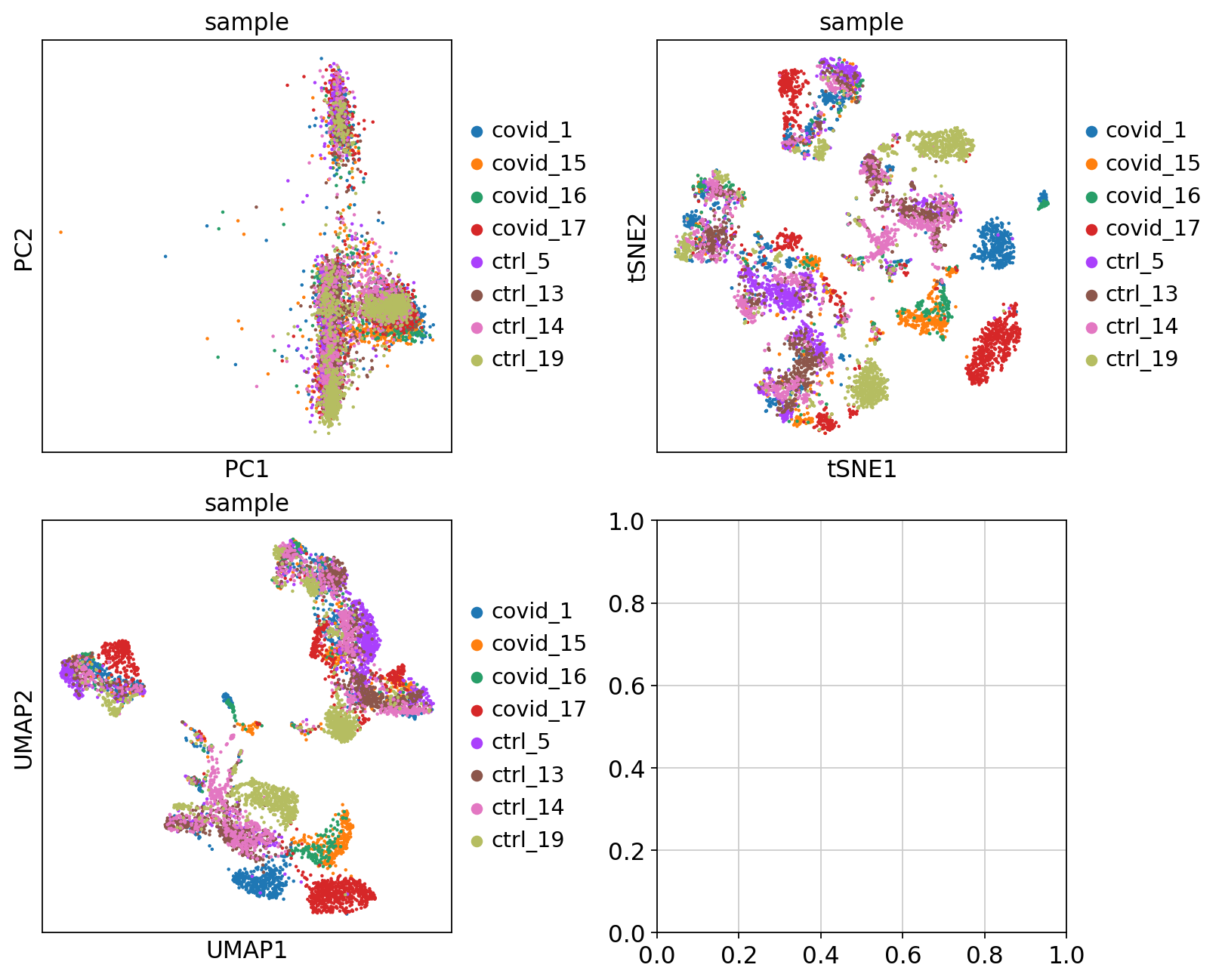
Finally, we can compare the PCA, tSNE and UMAP.
Discuss
We have now done Variable gene selection, PCA and UMAP with the settings we selected for you. Test a few different ways of selecting variable genes, number of PCs for UMAP and check how it influences your embedding.
7 Genes of interest
Let’s plot some marker genes for different cell types onto the embedding.
| Markers | Cell Type |
|---|---|
| CD3E | T cells |
| CD3E CD4 | CD4+ T cells |
| CD3E CD8A | CD8+ T cells |
| GNLY, NKG7 | NK cells |
| MS4A1 | B cells |
| CD14, LYZ, CST3, MS4A7 | CD14+ Monocytes |
| FCGR3A, LYZ, CST3, MS4A7 | FCGR3A+ Monocytes |
| FCER1A, CST3 | DCs |
sc.pl.umap(adata, color=["CD3E", "CD4", "CD8A", "GNLY","NKG7", "MS4A1","CD14","LYZ","CST3","MS4A7","FCGR3A"])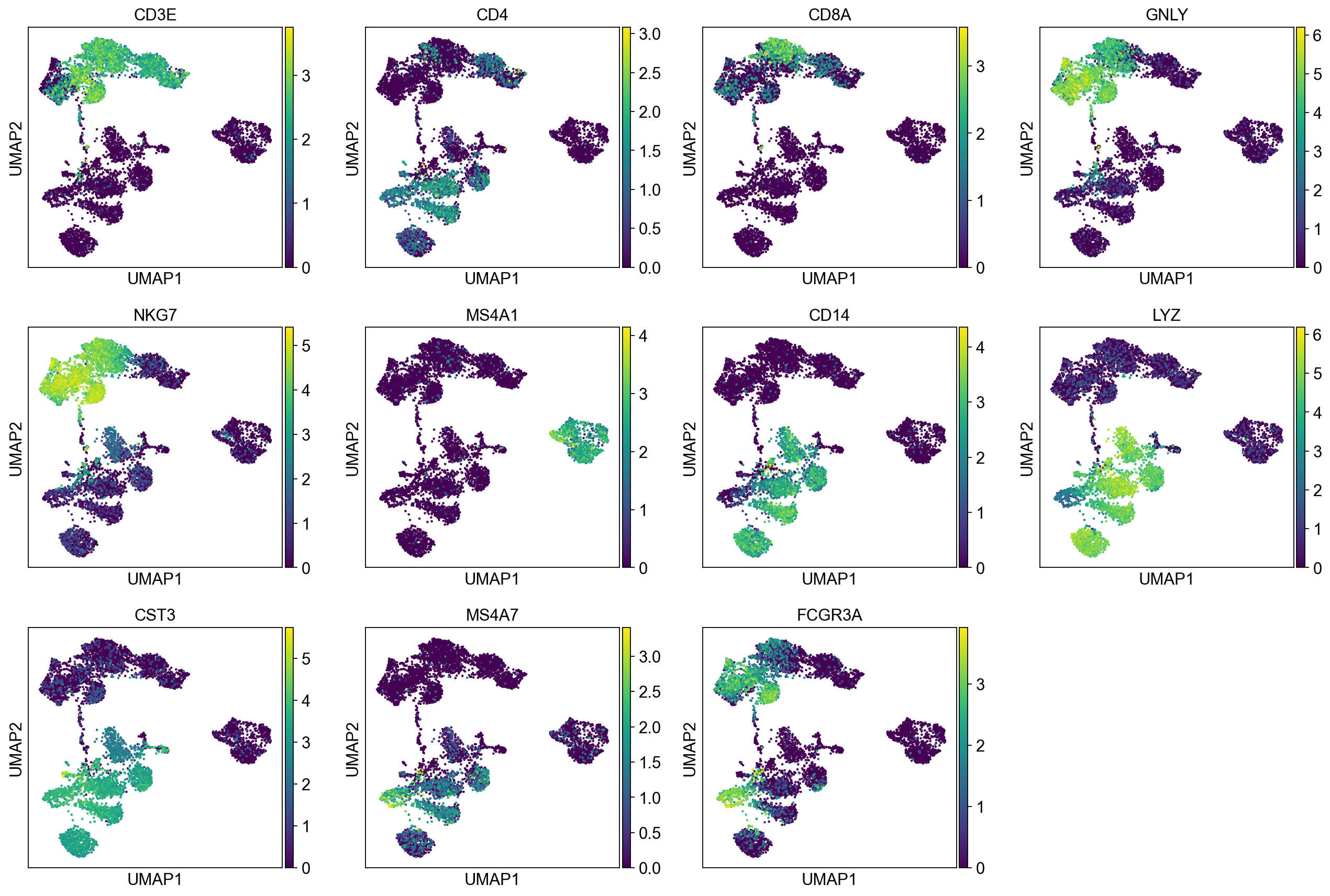
The default is to plot gene expression in the normalized and log-transformed data. You can also plot it on the scaled and corrected data by using use_raw=False. However, not all of these genes are included in the variable gene set, and hence are not included in the scaled adata.X, so we first need to filter them.
genes = ["CD3E", "CD4", "CD8A", "GNLY","NKG7", "MS4A1","CD14","LYZ","CST3","MS4A7","FCGR3A"]
var_genes = adata.var.highly_variable
var_genes.index[var_genes]
varg = [x for x in genes if x in var_genes.index[var_genes]]
sc.pl.umap(adata, color=varg, use_raw=False)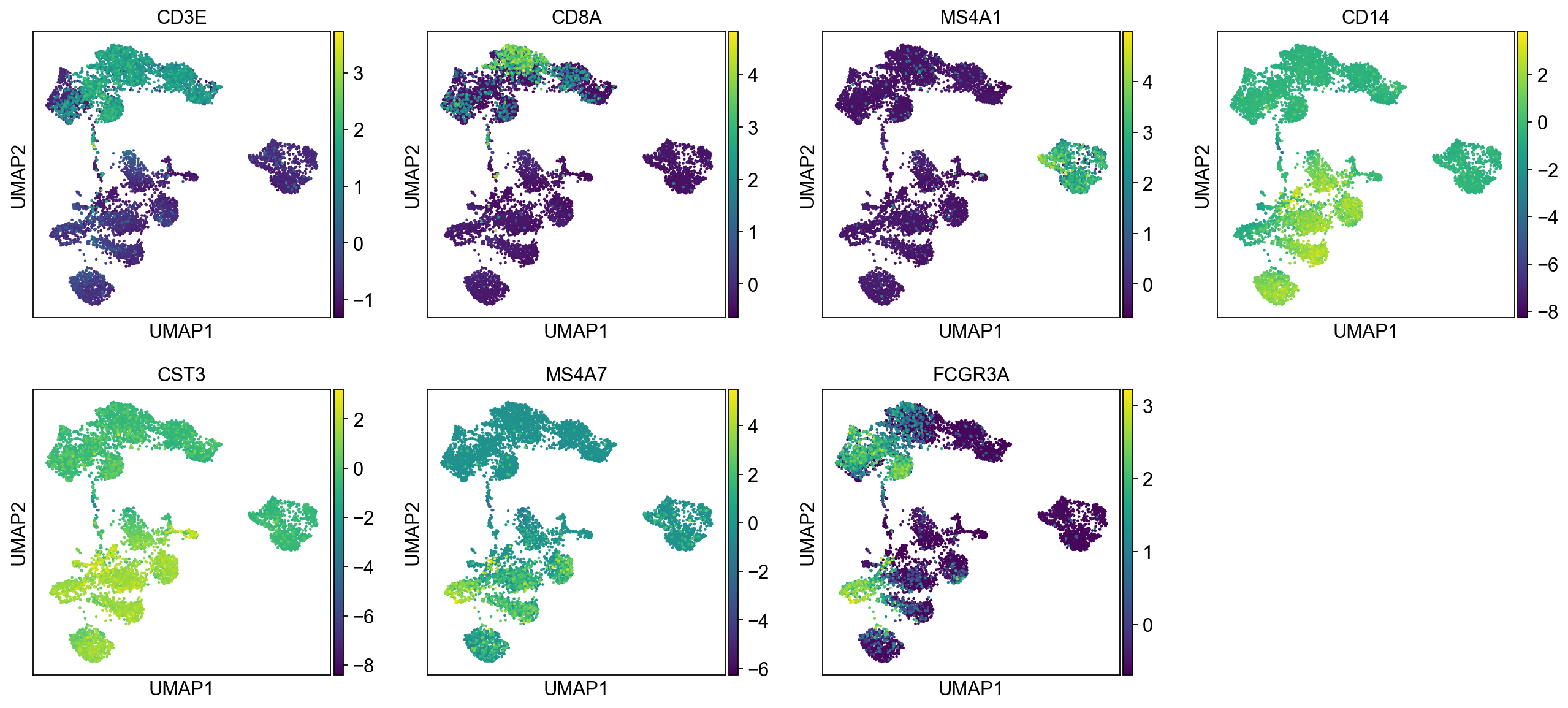
Discuss
Select some of your dimensionality reductions and plot some of the QC stats that were calculated in the previous lab. Can you see if some of the separation in your data is driven by quality of the cells?
sc.pl.umap(adata, color=['n_genes_by_counts', 'total_counts', 'pct_counts_mt','pct_counts_ribo', 'pct_counts_hb'], ncols=3,use_raw=False)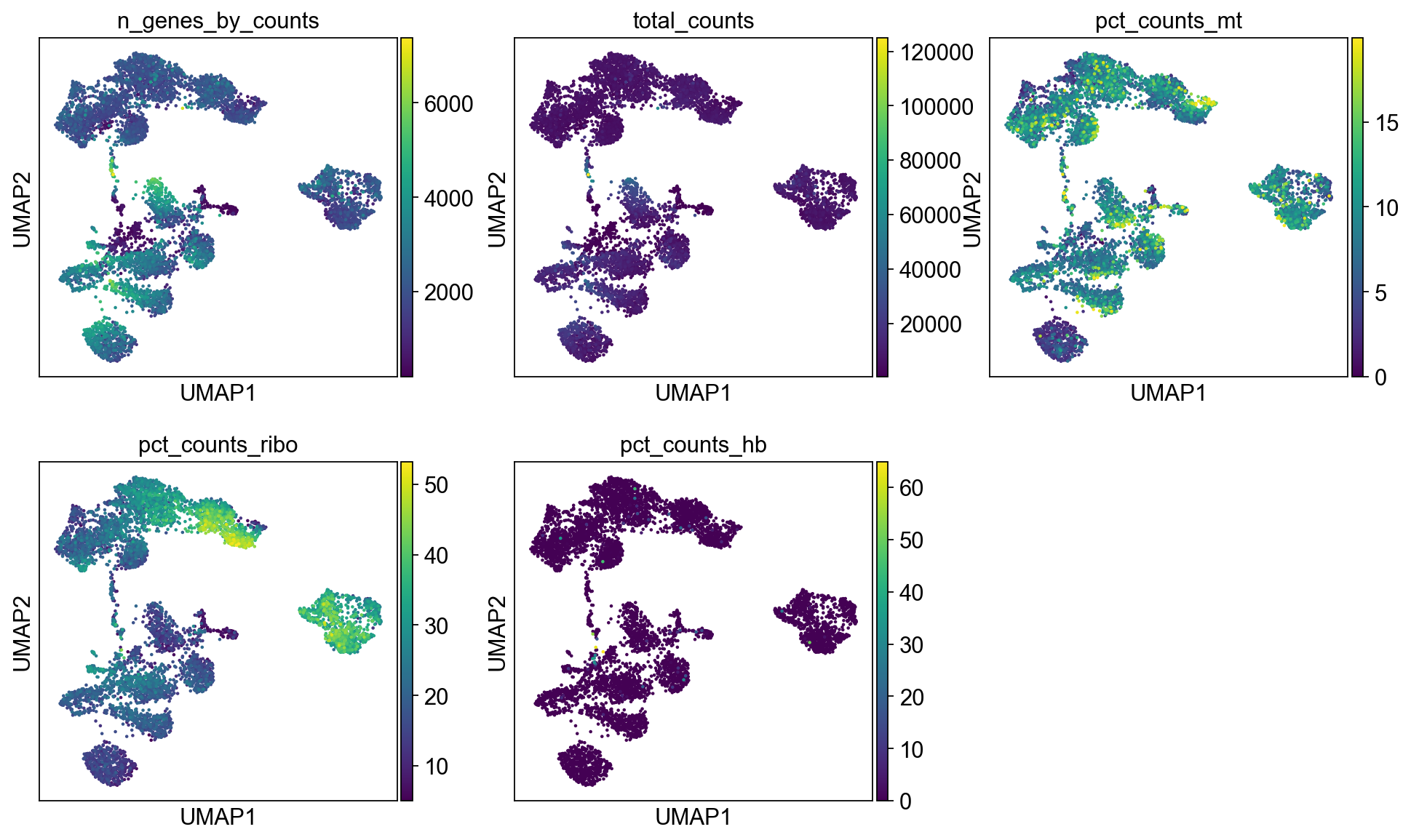
8 Save data
We can finally save the object for use in future steps.
adata.write_h5ad('data/covid/results/scanpy_covid_qc_dr.h5ad')9 Note
Just as a reminder, you need to keep in mind what you have in the X matrix. After these operations you have an X matrix with only variable genes, that are normalized, logtransformed and scaled.
We stored the expression of all genes in raw.X after doing lognormalization so that matrix is a sparse matrix with logtransformed values.
print(adata.X.shape)
print(adata.raw.X.shape)
print(adata.X[:3,:3])
print(adata.raw.X[:10,:10])(7332, 2656)
(7332, 19468)
[[-0.04097649 -0.04808595 -0.06951175]
[-0.05810044 -0.11063513 -0.34450077]
[-0.07079222 -0.13746446 -0.48150336]]
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 2 stored elements and shape (10, 10)>
Coords Values
(1, 4) 1.479703103222477
(8, 7) 1.639740823784253210 Session info
Click here
sc.logging.print_versions()-----
anndata 0.10.8
scanpy 1.10.3
-----
PIL 11.1.0
asttokens NA
cffi 1.17.1
colorama 0.4.6
comm 0.2.2
cycler 0.12.1
cython_runtime NA
dateutil 2.9.0.post0
debugpy 1.8.12
decorator 5.1.1
exceptiongroup 1.2.2
executing 2.1.0
h5py 3.12.1
igraph 0.11.6
ipykernel 6.29.5
jedi 0.19.2
joblib 1.4.2
kiwisolver 1.4.7
legacy_api_wrap NA
leidenalg 0.10.2
llvmlite 0.43.0
matplotlib 3.9.2
matplotlib_inline 0.1.7
mpl_toolkits NA
natsort 8.4.0
networkx 3.4
numba 0.60.0
numpy 1.26.4
packaging 24.2
pandas 1.5.3
parso 0.8.4
patsy 1.0.1
pickleshare 0.7.5
platformdirs 4.3.6
prompt_toolkit 3.0.50
psutil 6.1.1
pure_eval 0.2.3
pycparser 2.22
pydev_ipython NA
pydevconsole NA
pydevd 3.2.3
pydevd_file_utils NA
pydevd_plugins NA
pydevd_tracing NA
pygments 2.19.1
pynndescent 0.5.13
pyparsing 3.2.1
pytz 2024.2
scipy 1.14.1
session_info 1.0.0
six 1.17.0
sklearn 1.6.1
sparse 0.15.5
stack_data 0.6.3
statsmodels 0.14.4
texttable 1.7.0
threadpoolctl 3.5.0
torch 2.5.1.post207
torchgen NA
tornado 6.4.2
tqdm 4.67.1
traitlets 5.14.3
typing_extensions NA
umap 0.5.7
wcwidth 0.2.13
yaml 6.0.2
zmq 26.2.0
zoneinfo NA
-----
IPython 8.31.0
jupyter_client 8.6.3
jupyter_core 5.7.2
-----
Python 3.10.16 | packaged by conda-forge | (main, Dec 5 2024, 14:16:10) [GCC 13.3.0]
Linux-6.10.14-linuxkit-x86_64-with-glibc2.35
-----
Session information updated at 2025-02-27 15:10