Review¶
- Dictionaries
- Create a dictionary containing the keys
aandb. Both should have the value 1. - Change the value of
bto 5.
- Create a dictionary containing the keys
- Lists
- Create a list containing the elements
'a','b','c'. - Reverse it
- Create a list containing the elements
Set the variable
titleto"A movie"andratingto10.Use formatting to produce the following string:
"The movie the movie got rating 10!"
# Create a dictionary containing the keys a and b. Both should have the value 1
# Change the value of b to 5
# Create a list containing the elements `'a'`, `'b'`, `'c'`
# Reverse it
# Set the variable `title` to `"A movie"` and `rating` to 10.
# Use formatting to produce: "The movie the movie got rating 10!"
TODAY¶
- review
- regex
- sumup


Keyword arguments¶
open(filename, encoding="utf-8")
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Documentition and getting help¶
help(sys)
- write comments
# why do I do this? - write documentation
"""what is this? how do you use it?"""
Writing readable code¶
def f(a, b):
for c in open(a):
if c.startswith(b):
print(c)
==>
def print_lines(filename, start):
"""Print all lines in the file that starts with the given string."""
for line in open(filename):
if line.startswith(start):
print(line)
Pandas¶
Read tables
dataframe = pandas.read_table('mydata.txt', sep='|', index_col=0) dataframe = pandas.read_csv('mydata.csv')
Select rows and colums
dataframe.columname dataframe.loc[index] dataframe.loc[dataframe.age == 20 ]
Plot it
datafram.plot(kind='line', x='column1', y='column2')
TODAY¶
- Regular expressions
- Sum up of the course
Regular Expressions¶
- A formal language for defining search patterns
- Let's you search not only for exact strings but controlled variations of that string.
- Why?
- Examples:
- Find variations in a protein or DNA sequence
"MVR???A""ATG???TAG
- American/British spelling, endings and other variants:
- salpeter, salpetre, saltpeter, nitre, niter or KNO3
- hemaglobin, heamoglobin, hemaglobins, heamoglobin's
- catalyze, catalyse, catalyzed...
- A pattern in a vcf file
- a digit appearing after a tab
- Find variations in a protein or DNA sequence
Regular Expressions¶
- When?
- To find information
- in your
vcforfastafiles - in your code
- in your next essay
- in a database
- online
- in a bunch of articles
- ...
- in your
- Search/replace
- becuase → because
- color → colour
\t(tab) →" "(four spaces)
- Supported by most programming languages, text editors, search engines...
Defining a search pattern¶
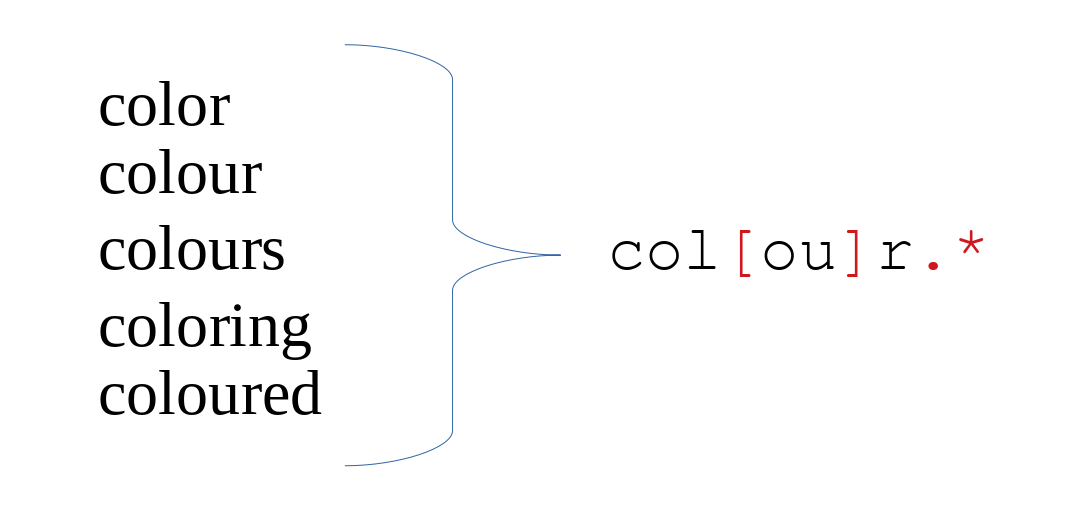
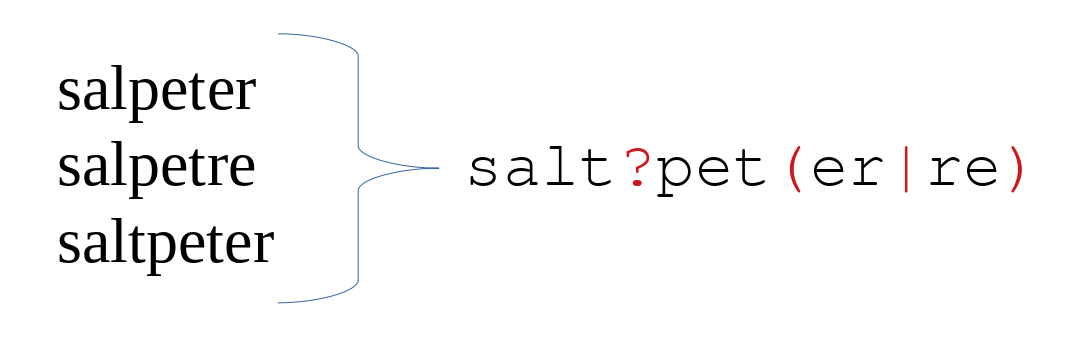
Common operations¶
.matches any character (once)?repeat previous pattern 0 or 1 times*repeat previous pattern 0 or more times+repeat previous pattern 1 or more times
colour.*
salt?peter
.* matches everything (including the empty string)!
"salt?pet.."More common operations - classes of characters¶
\wmatches any letter or number, and the underscore\dmatches any digit\Dmatches any non-digit\smatches any whitespace (spaces, tabs, ...)\Smatches any non-whitespace
More common operations - classes of characters¶
\wmatches any letter or number, and the underscore\dmatches any digit\Dmatches any non-digit\smatches any whitespace (spaces, tabs, ...)\Smatches any non-whitespace
\w+

More common operations - classes of characters¶
\wmatches any letter or number, and the underscore\dmatches any digit\Dmatches any non-digit\smatches any whitespace (spaces, tabs, ...)\Smatches any non-whitespace
\d+

More common operations - classes of characters¶
\wmatches any letter or number, and the underscore\dmatches any digit\Dmatches any non-digit\smatches any whitespace (spaces, tabs, ...)\Smatches any non-whitespace
\s+

More common operations - classes of characters¶
\wmatches any letter or number, and the underscore\dmatches any digit\Dmatches any non-digit\smatches any whitespace (spaces, tabs, ...)\Smatches any non-whitespace[abc]matches a single character defined in this set {a, b, c}[^abc]matches a single character that is not a, b or c
salt?pet[er]+
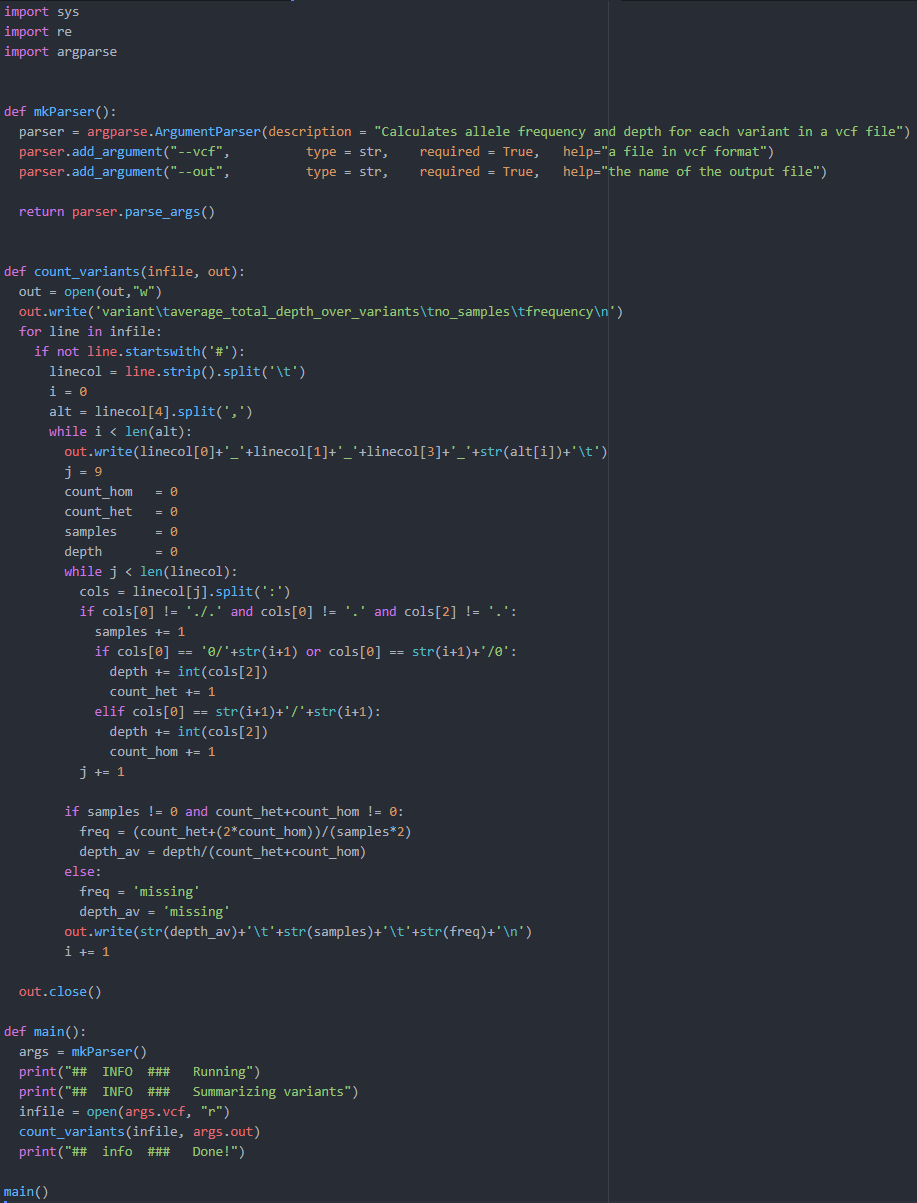
Example - finding patterns in vcf
1 920760 rs80259304 T C . PASS AA=T;AC=18;AN=120;DP=190;GP=1:930897;BN=131 GT:DP:CB 0/1:1:SM 0/0:4/SM...
- Find a sample:
0/0 0/1 1/1 ...
"[01]/[01]" (or "\d/\d")
\s[01]/[01]:
Example - finding patterns in vcf
1 920760 rs80259304 T C . PASS AA=T;AC=18;AN=120;DP=190;GP=1:930897;BN=131 GT:DP:CB 0/1:1:SM 0/0:4/SM...
- Find all lines containing more than one homozygous sample.
... 1/1:... ... 1/1:... ...
.*1/1.*1/1.*
.*\s1/1:.*\s1/1:.*
Exercise 1¶
.matches any character (once)?repeat previous pattern 0 or 1 times*repeat previous pattern 0 or more times+repeat previous pattern 1 or more times\wmatches any letter or number, and the underscore\dmatches any digit\Dmatches any non-digit\smatches any whitespace (spaces, tabs, ...)\Smatches any non-whitespace[abc]matches a single character defined in this set {a, b, c}[^abc]matches a single character that is not a, b or c[a-z]matches any (lowercased) letter from the english alphabet.*matches anything
→ Notebook Day_5_Exercise_1 (~30 minutes)
Regular expressions in Python¶
import re
p = re.compile('ab*')
p
Searching¶
p = re.compile('ab*')
p.search('abc')
print(p.search('cb'))
p = re.compile('HELLO')
m = p.search('gsdfgsdfgs HELLO __!@£§≈[|ÅÄÖ‚…’fi]')
print(m)
Case insensitiveness¶
p = re.compile('[a-z]+')
result = p.search('ATGAAA')
print(result)
p = re.compile('[a-z]+', re.IGNORECASE)
result = p.search('ATGAAA')
result
The match object¶
result = p.search('123 ATGAAA 456')
result
result.group(): Return the string matched by the expression
result.start(): Return the starting position of the match
result.end(): Return the ending position of the match
result.span(): Return both (start, end)
result.group()
result.start()
result.end()
result.span()
Zero or more...?¶
p = re.compile('.*HELLO.*')
m = p.search('lots of text HELLO more text and characters!!! ^^')
m.group()
The * is greedy.
Finding all the matching patterns¶
p = re.compile('HELLO')
objects = p.finditer('lots of text HELLO more text HELLO ... and characters!!! ^^')
print(objects)
for m in objects:
print(f'Found {m.group()} at position {m.start()}')
objects = p.finditer('lots of text HELLO more text HELLO ... and characters!!! ^^')
for m in objects:
print('Found {} at position {}'.format(m.group(), m.start()))
How to find a full stop?¶
txt = "The first full stop is here: ."
p = re.compile('.')
m = p.search(txt)
print('"{}" at position {}'.format(m.group(), m.start()))
p = re.compile('\.')
m = p.search(txt)
print('"{}" at position {}'.format(m.group(), m.start()))
More operations¶
\escaping a character^beginning of the string$end of string|booleanor
^hello$
salt?pet(er|re) | nit(er|re) | KNO3
Substitution¶
Finally, we can fix our spelling mistakes!¶
txt = "Do it becuase I say so, not becuase you want!"
import re
p = re.compile('becuase')
txt = p.sub('because', txt)
print(txt)
p = re.compile('\s+')
p.sub(' ', txt)
Overview¶
Construct regular expressions
p = re.compile()
Searching
p.search(text)
Substitution
p.sub(replacement, text)
Typical code structure:
p = re.compile( ... )
m = p.search('string goes here')
if m:
print('Match found: ', m.group())
else:
print('No match')
Exercise 2¶
.matches any character (once)?repeat previous pattern 0 or 1 times*repeat previous pattern 0 or more times+repeat previous pattern 1 or more times\wmatches any letter or number, and the underscore\dmatches any digit\Dmatches any non-digit\smatches any whitespace (spaces, tabs, ...)\Smatches any non-whitespace[abc]matches a single character defined in this set {a, b, c}[^abc]matches a single character that is not a, b or c[a-z]matches any (lowercased) letter from the english alphabet.*matches anything\escaping a character^beginning of the string$end of string|booleanor
Read more: full documentation https://docs.python.org/3.6/library/re.html
→ Notebook Day_5_Exercise_2 (~30 minutes)
Sum up!
Processing files - looping through the lines¶
for line in open('myfile.txt', 'r'):
do_stuff(line)
Store values¶
iterations = 0
information = []
for line in open('myfile.txt', 'r'):
iterations += 1
information += do_stuff(line)
Values¶
Base types:
str "hello"
int 5
float 5.2
bool True
Collections:
list ["a", "b", "c"]
dict {"a": "alligator", "b": "bear", "c": "cat"}
tuple ("this", "that")
set {"drama", "sci-fi"}
Assign values
iterations = 0
score = 5.2
Modify values and compare¶
+, -, *,... # mathematical
and, or, not # logical
==, != # comparisons
<, >, <=, >= # comparisons
in # membership
value = 4
nextvalue = 1
nextvalue += value
print('nextvalue: ', nextvalue, 'value: ', value)
x = 5
y = 7
z = 2
x > 6 and y == 7 or z > 1
(x > 6 and y == 7) or z > 1
Strings¶
Raw text
Common manipulations:
s.strip() # remove unwanted spacing
s.split() # split line into columns
s.upper(), s.lower() # change the case
Regular expressions help you find and replace strings.
p = re.compile('A.A.A') p.search(dnastring)
p = re.compile('T') p.sub('U', dnastring)
import re
p = re.compile('p.*\sp') # the greedy star!
p.search('a python programmer writes python code').group()
Collections¶
Can contain strings, integer, booleans...
Mutable: you can add, remove, change values
Lists:
mylist.append('value')
Dicts:
mydict['key'] = 'value'
Sets:
myset.add('value')
Collections¶
Test for membership:
value in myobj
Check size:
len(myobj)
Lists¶
- Ordered!
todolist = ["work", "sleep", "eat", "work"]
todolist.sort()
todolist.reverse()
todolist[2]
todolist[-1]
todolist[2:6]
todolist = ["work", "sleep", "eat", "work"]
todolist.sort()
print(todolist)
todolist.reverse()
print(todolist)
todolist[2]
todolist[-1]
todolist[2:]
Dictionaries¶
- Keys have values
mydict = {"a": "alligator", "b": "bear", "c": "cat"}
counter = {"cats": 55, "dogs": 8}
mydict["a"]
mydict.keys()
mydict.values()
counter = {'cats': 0, 'others': 0}
for animal in ['zebra', 'cat', 'dog', 'cat']:
if animal == 'cat':
counter['cats'] += 1
else:
counter['others'] += 1
counter
Sets¶
Bag of values
No order
No duplicates
Fast membership checks
Logical set operations (union, difference, intersection...)
myset = {"drama", "sci-fi"}
|
myset.add("comedy")
myset.remove("drama")
todolist = ["work", "sleep", "eat", "work"]
todo_items = set(todolist)
todo_items
todo_items.add("study")
todo_items
todo_items.add("eat")
todo_items
Strings¶
Works like a list of characters
s += "more words" # add content
s[4] # get character at index 4
'e' in s # check for membership
len(s) # check size
But are immutable
> s[2] = 'i'
Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Tuples¶
A group (usually two) of values that belong together
tup = (max_lenght, sequence)
An ordered sequence (like lists)
length = tup[0] # get content at index 0
- Immutable
tup = (2, 'xy')
tup[0]
tup[0] = 2
def find_longest_seq(file):
# some code here...
return length, sequence
answer = find_longest_seq(filepath)
print('lenght', answer[0])
print('sequence', answer[1])
answer = find_longest_seq(filepath)
length, sequence = find_longest_seq(filepath)
Deciding what to do¶
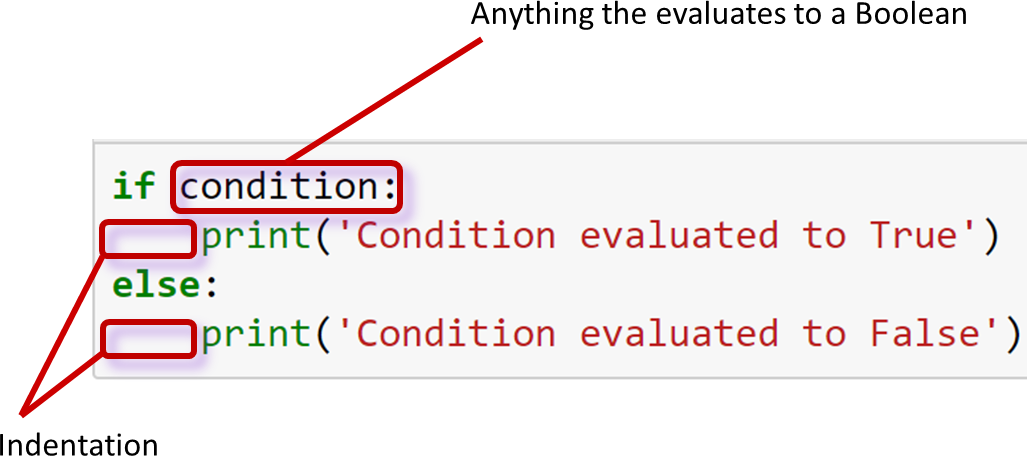
if count > 10:
print('big')
elif count > 5:
print('medium')
else:
print('small')
shopping_list = ['bread', 'egg', ' butter', 'milk']
tired = True
if len(shopping_list) > 4:
print('Really need to go shopping!')
elif not tired:
print('Not tired? Then go shopping!')
else:
print('Better to stay at home')
Deciding what to do - if statement¶
Program flow - for loops¶
information = []
for line in open('myfile.txt', 'r'):
if is_comment(line):
use_comment(line)
else:
information = read_data(line)

Program flow - while loops¶
keep_going = True
information = []
index = 0
while keep_going:
current_line = lines[index]
information += read_line(current_line)
index += 1
if check_something(current_line):
keep_going = False

Different types of loops¶
For loop
is a control flow statement that performs operations over a known amount of steps.
While loop
is a control flow statement that allows code to be executed repeatedly based on a given Boolean condition.
Which one to use?
For loops - standard for iterations over lists and other iterable objects
While loops - more flexible and can iterate an unspecified number of times
user_input = "thank god it's friday"
for c in user_input:
print(c.upper())
i = 0
while i < len(user_input):
c = user_input[i]
print(c.upper())
i += 1
Controlling loops¶
break- stop the loopcontinue- go on to the next iteration
user_input = "thank god it's friday"
for c in user_input:
print(c.upper())
if c == 'd':
break
Watch out!
i = 0
while i > 10:
print(user_input[i])
While loops may be infinite!
Input/Output¶
In:
Read files:
fh = open(filename, 'r')for line in fh:fh.read()fh.readlines()
- Read information from command line:
sys.argv[1:]
Out:
- Write files:
fh = open(filename, 'w')fh.write(text)
- Printing:
print('my_information')
- Write files:
Input/Output¶
- Open files should be closed:
fh.close()
Code structure¶
- Functions
- Modules
Functions¶
- A named piece of code that performs a certain task.
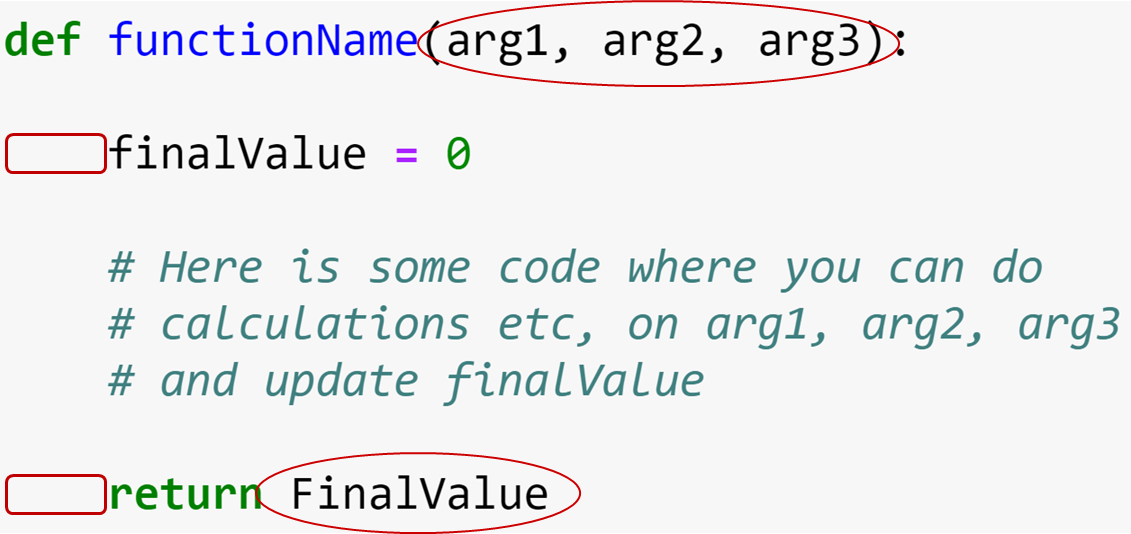
- Is given a number of input arguments
- to be used (are in scope) within the function body
- Returns a result (maybe
None)
Functions - keyword arguments¶
def prettyprinter(name, value, delim=":", end=None):
out = "The " + name + " is " + delim + " " + value
if end:
out += end
return out
- used to set default values (often
None) - can be skipped in function calls
- improve readability
Using your code¶
Any longer pieces of code that have been used and will be re-used should be saved
Save it as a file
.pyTo run it:
python3 mycode.pyImport it:
import mycode
Documentation and comments¶
""" This is a doc-string explaining what the purpose of this function/module is."""# This is a comment that helps understanding the code
- Comments will help you
- Undocumented code rarely gets used
- Try to keep your code readable: use informative variable and function names
Why programming?¶
Endless possibilities!
- reverse complement DNA
- custom filtering of VCF files
- plotting of results
- all excel stuff!
Why programming?¶
- Computers are fast
- Computers don't get bored
- Computers don't get sloppy
- Create reproducable results
- Extract large amount of information
Final advice¶
- Stop to think before you start coding
- use pseudocode
- use top-down programming
- use paper and pen
- take breaks
- You know the basics - don't be afraid to try
- You will get faster
Final advice¶
- Getting help
- ask colleauges
- talk about your problem (get a rubber duck)
- search the web
- take breaks!
- NBIS drop-ins