flowchart TD A(Machine learning) --> B(unsupervised learning) A --> C(supervised learning)
Supervised learning
What is supervised learning?
- In supervised learning we are using sample labels to train (build) a model.
- We then use the trained model for interpretation and prediction.
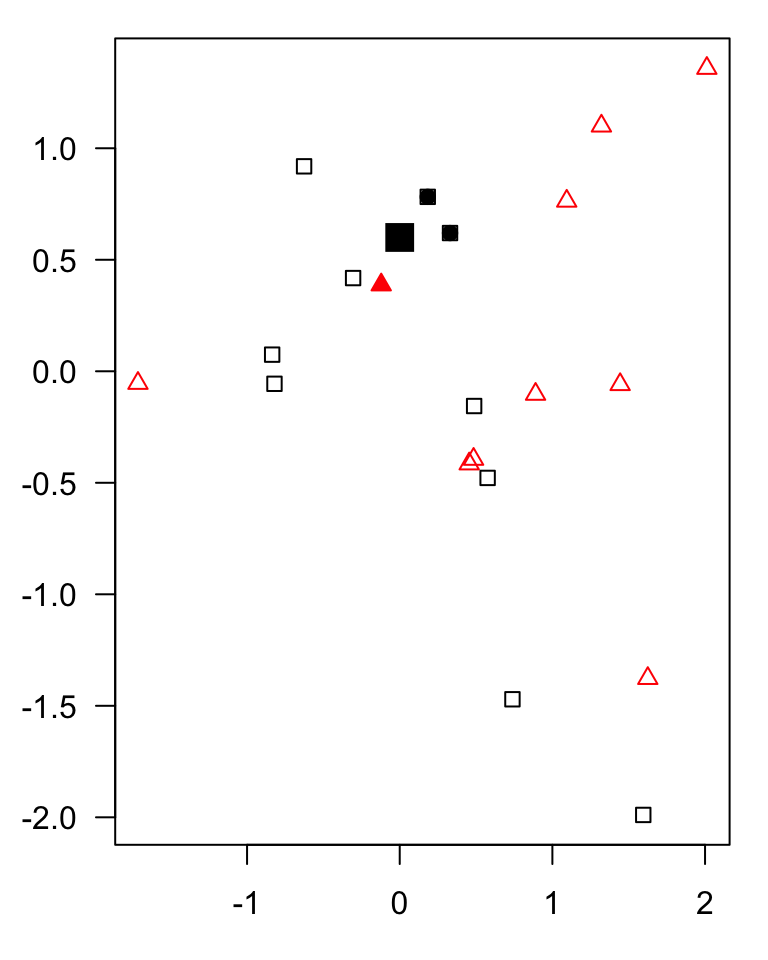
KNN
example of a classification algorithm
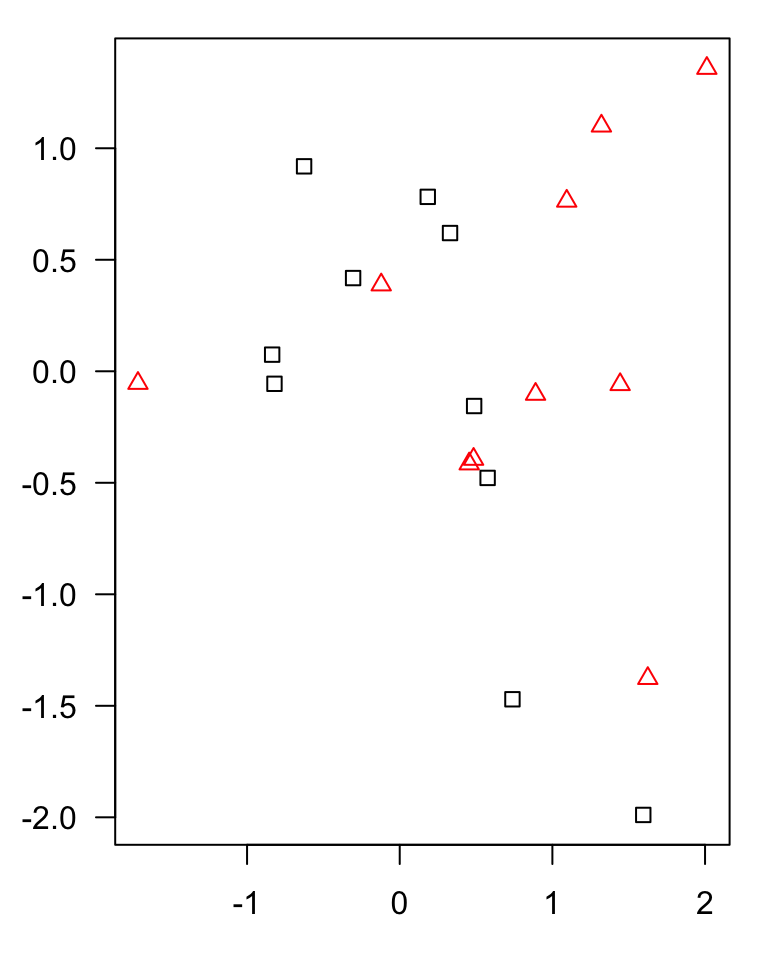
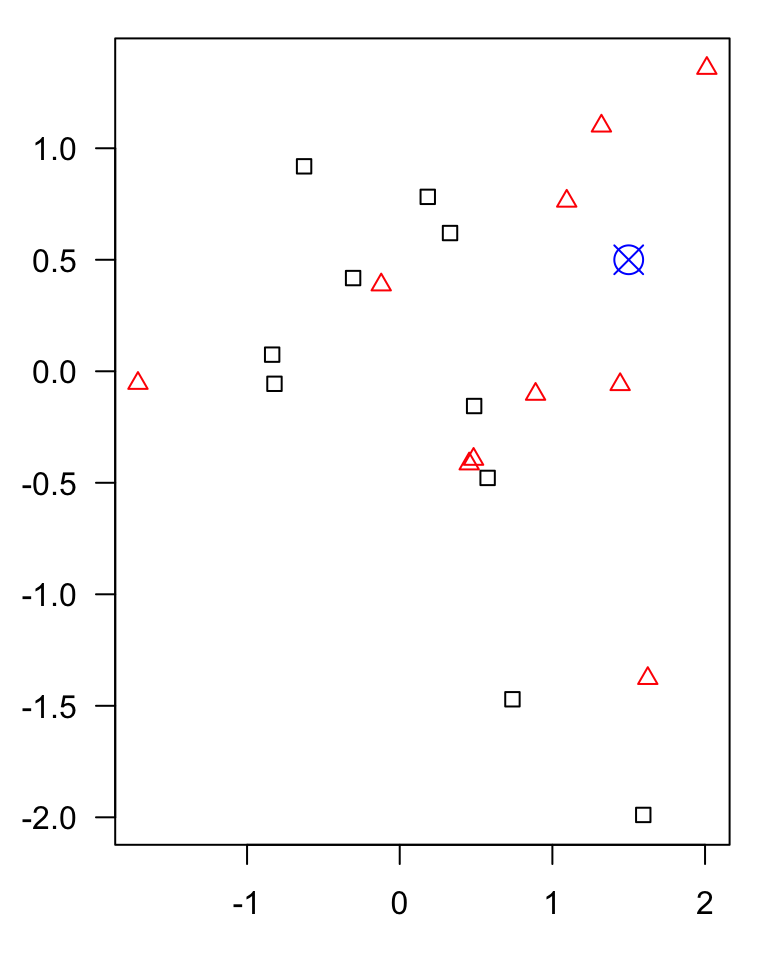
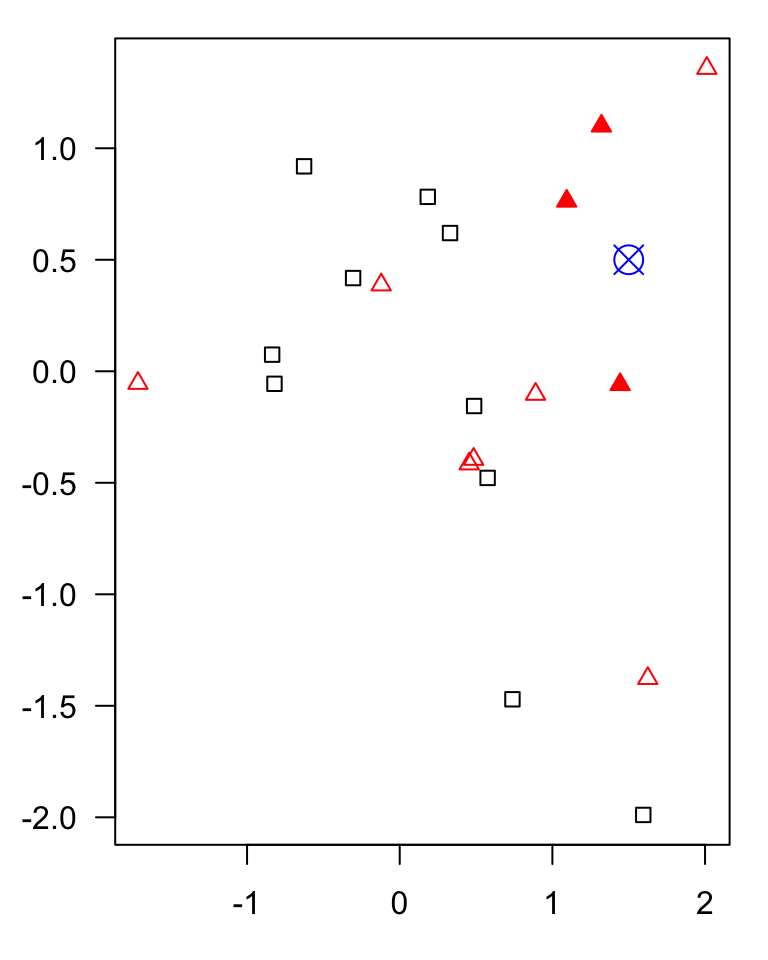
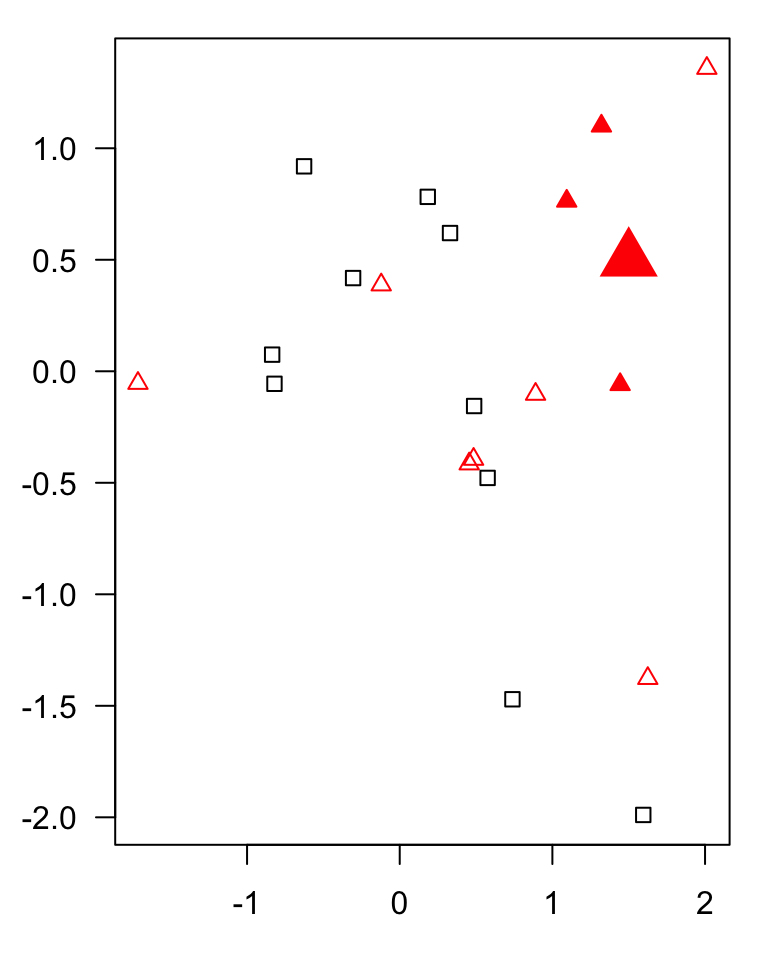
KNN
example of a classification algorithm
Data splitting
train, validation & test sets
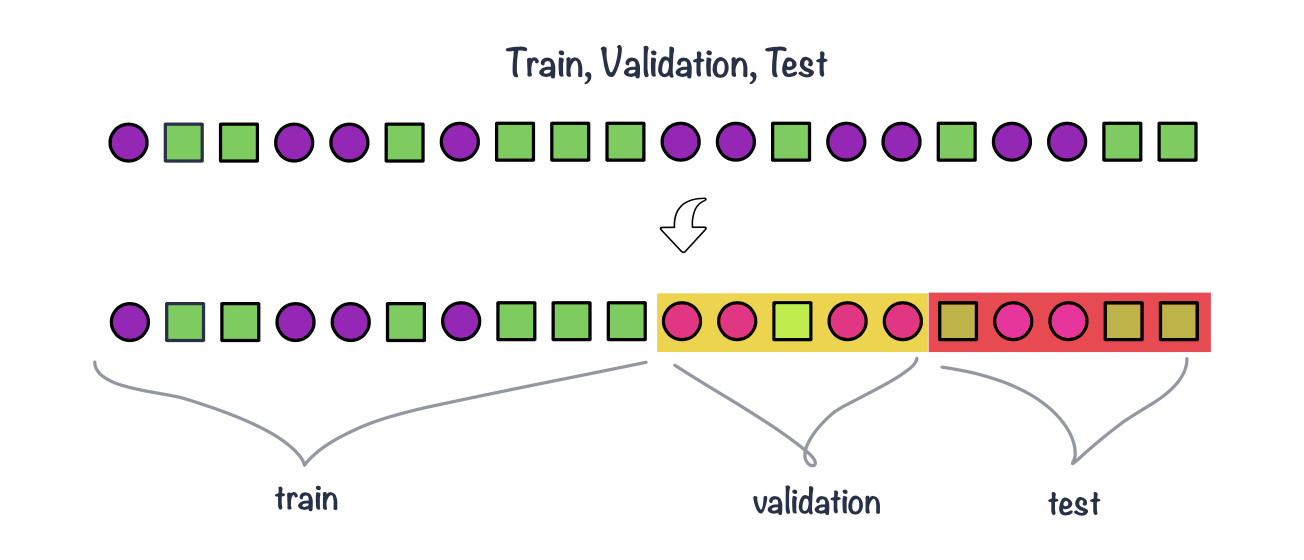
- Training data: this is data used to fit (train) the classification or regression model, i.e. derive the classification rule.
- Validation data: this is data used to select which parameters or types of model perform best, i.e. to validate the performance of model parameters.
- Test data: this data is used to give an estimate of future prediction performance for the model and parameters chosen.
- Common split strategies include 50%/25%/25% and 33%/33%/33% splits for training/validation/test respectively
Data splitting
cross validation & repeated cross validation
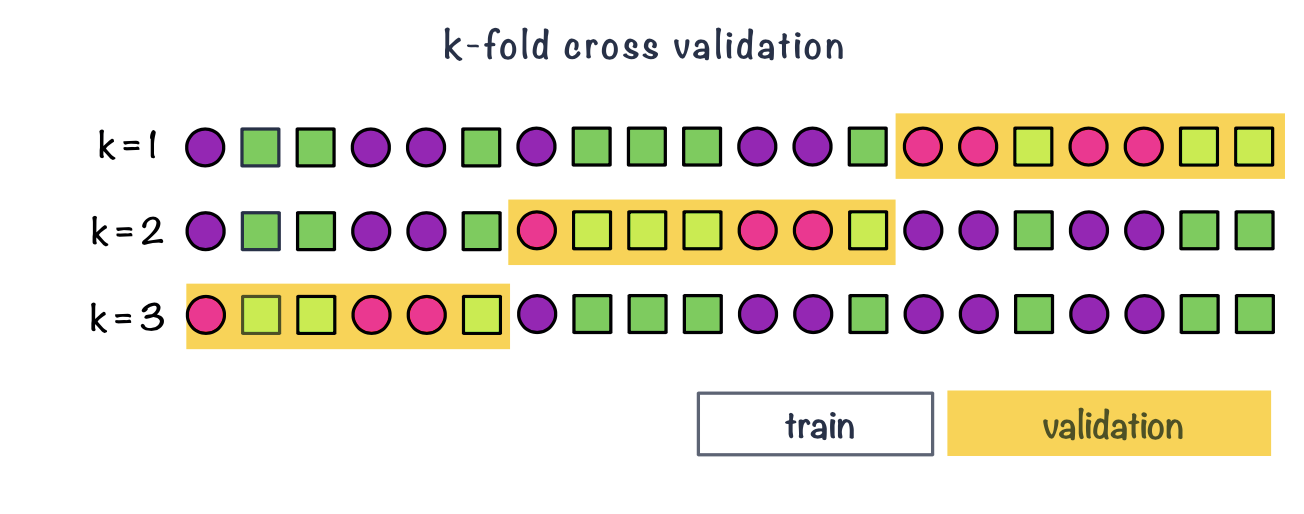
- In k-fold cross-validation we split data into \(k\) roughly equal-sized parts.
- We start by setting the validation data to be the first set of data and the training data to be all other sets.
- We estimate the validation error rate / correct classification rate for the split.
- We then repeat the process \(k-1\) times, each time with a different part of the data set to be the validation data and the remainder being the training data.
- We finish with \(k\) different error or correct classification rates.
- In this way, every data point has its class membership predicted once.
- The final reported error rate is usually the average of \(k\) error rates.
Data splitting
Leave-one-out cross-validation
- Leave-one-out cross-validation is a special case of cross-validation where the number of folds equals the number of instances in the data set.

Figure 1: Example of LOOCV, leave-one-out cross validation