Table of Contents
Scanpy: Data integration¶
In this tutorial we will look at different ways of integrating multiple single cell RNA-seq datasets. We will explore two different methods to correct for batch effects across datasets. We will also look at a quantitative measure to assess the quality of the integrated data. Seurat uses the data integration method presented in Comprehensive Integration of Single Cell Data, while Scran and Scanpy use a mutual Nearest neighbour method (MNN). Below you can find a list of the most recent methods for single data integration:
| Markdown | Language | Library | Ref |
|---|---|---|---|
| CCA | R | Seurat | Cell |
| MNN | R/Python | Scater/Scanpy | Nat. Biotech. |
| Conos | R | conos | Nat. Methods |
| Scanorama | Python | scanorama | Nat. Biotech. |
import numpy as np
import pandas as pd
import scanpy as sc
import matplotlib.pyplot as plt
sc.settings.verbosity = 3 # verbosity: errors (0), warnings (1), info (2), hints (3)
#sc.logging.print_versions()
sc.settings.set_figure_params(dpi=80)
%matplotlib inline
First need to load the QC filtered dataset and create individual adata objects per batch.
# Load the stored data object
save_file = './data/results/scanpy_dr_covid.h5ad'
adata = sc.read_h5ad(save_file)
print(adata.X.shape)
As the stored AnnData object contains scaled data based on variable genes, we need to make a new object with the logtransformed normalized counts. The new variable gene selection should not be performed on the scaled data matrix.
adata2 = adata.raw.to_adata()
adata2.uns['log1p']['base']=None
# check that the matrix looks like noramlized counts
print(adata2.X[1:10,1:10])
Detect variable genes¶
Variable genes can be detected across the full dataset, but then we run the risk of getting many batch-specific genes that will drive a lot of the variation. Or we can select variable genes from each batch separately to get only celltype variation. In the dimensionality reduction exercise, we already selected variable genes, so they are already stored in adata.var.highly_variable
var_genes_all = adata.var.highly_variable
print("Highly variable genes: %d"%sum(var_genes_all))
Detect variable genes in each dataset separately using the batch_key parameter.
sc.pp.highly_variable_genes(adata2, min_mean=0.0125, max_mean=3, min_disp=0.5, batch_key = 'sample')
print("Highly variable genes intersection: %d"%sum(adata2.var.highly_variable_intersection))
print("Number of batches where gene is variable:")
print(adata2.var.highly_variable_nbatches.value_counts())
var_genes_batch = adata2.var.highly_variable_nbatches > 0
Compare overlap of the variable genes.
print("Any batch var genes: %d"%sum(var_genes_batch))
print("All data var genes: %d"%sum(var_genes_all))
print("Overlap: %d"%sum(var_genes_batch & var_genes_all))
print("Variable genes in all batches: %d"%sum(adata2.var.highly_variable_nbatches == 6))
print("Overlap batch instersection and all: %d"%sum(var_genes_all & adata2.var.highly_variable_intersection))
Select all genes that are variable in at least 2 datasets and use for remaining analysis.
var_select = adata2.var.highly_variable_nbatches > 2
var_genes = var_select.index[var_select]
len(var_genes)
sc.external.pp.bbknn(adata2, batch_key='sample', n_pcs=30) # running bbknn 1.3.6
# then run umap on the integrated space
sc.tl.umap(adata2)
sc.tl.tsne(adata2)
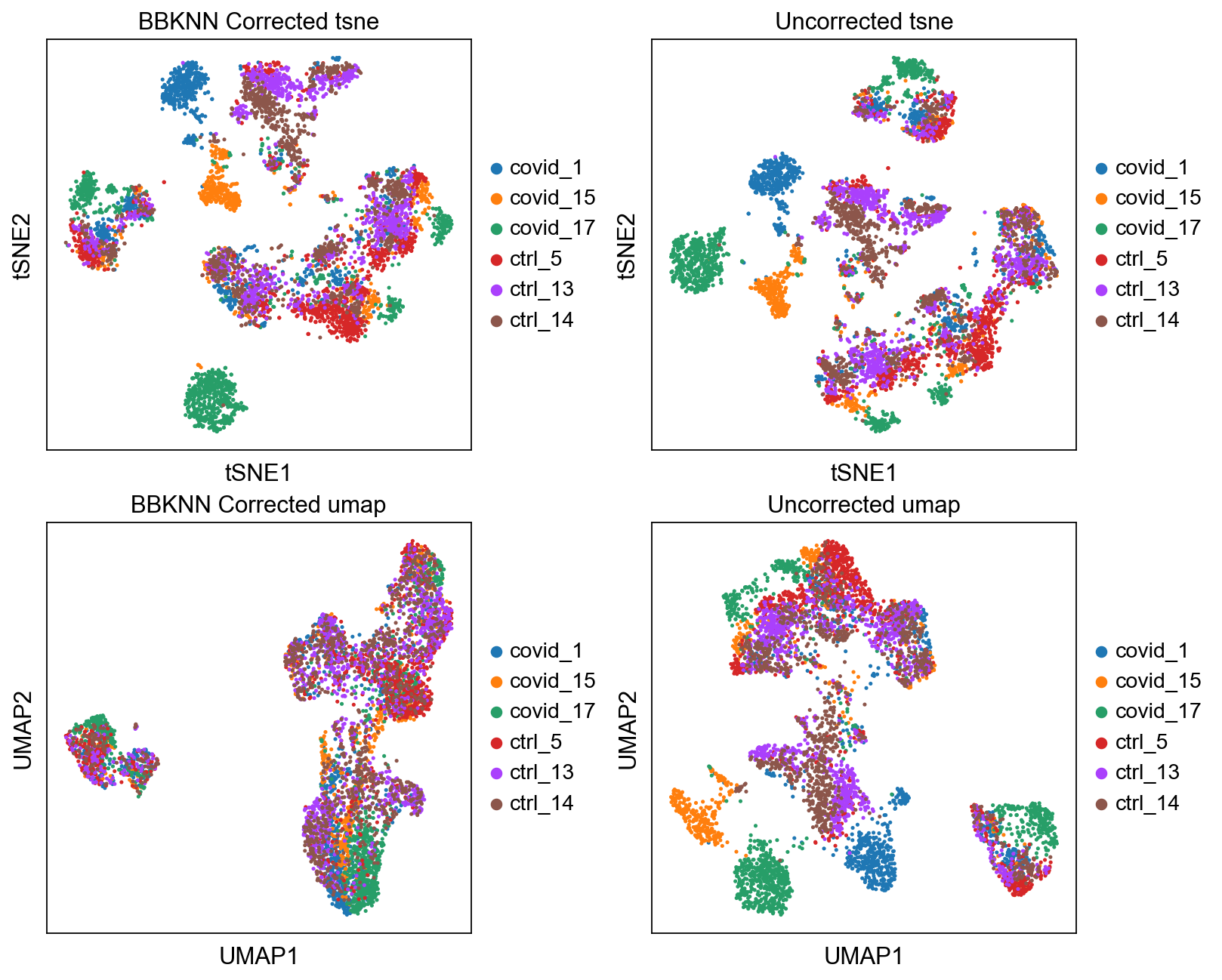
We can now plot the un-integrated and the integrated space reduced dimensions.
fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.tsne(adata2, color="sample", title="BBKNN Corrected tsne", ax=axs[0,0], show=False)
sc.pl.tsne(adata, color="sample", title="Uncorrected tsne", ax=axs[0,1], show=False)
sc.pl.umap(adata2, color="sample", title="BBKNN Corrected umap", ax=axs[1,0], show=False)
sc.pl.umap(adata, color="sample", title="Uncorrected umap", ax=axs[1,1], show=False)
Finally, lets save the integrated data for further analysis.
save_file = './data/results/scanpy_bbknn_corrected_covid.h5ad'
adata2.write_h5ad(save_file)
Combat¶
Batch correction can also be performed with combat.
Note that ComBat batch correction requires a dense matrix format as input (which is already the case in this example).
# create a new object with lognormalized counts
adata_combat = sc.AnnData(X=adata.raw.X, var=adata.raw.var, obs = adata.obs)
# first store the raw data
adata_combat.raw = adata_combat
# run combat
sc.pp.combat(adata_combat, key='sample')
Then we run the regular steps of dimensionality reduction on the combat corrected data
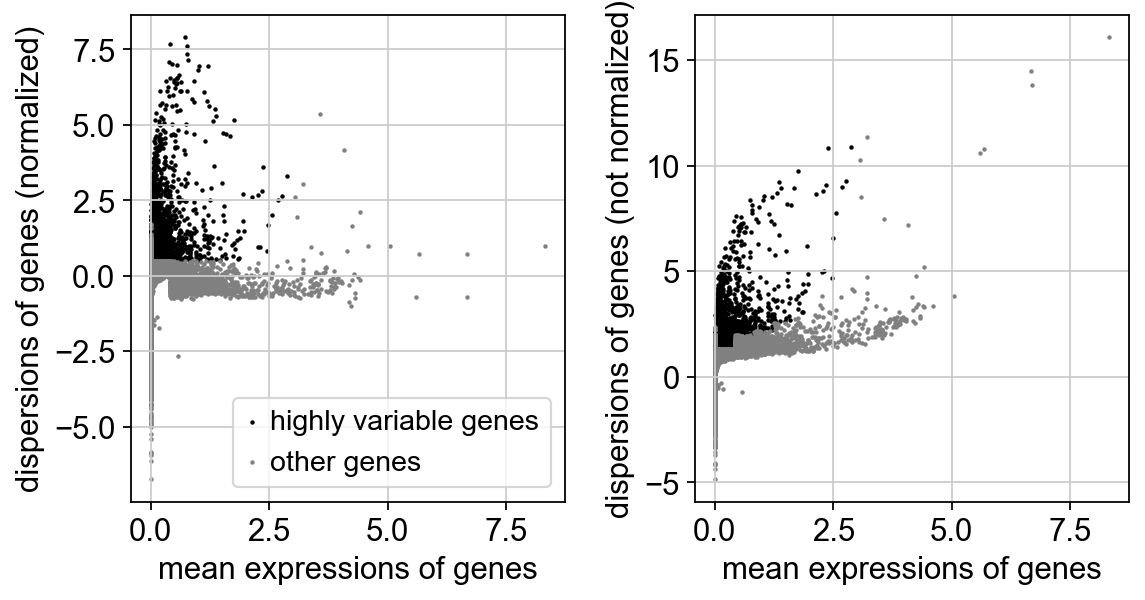
sc.pp.highly_variable_genes(adata_combat)
print("Highly variable genes: %d"%sum(adata_combat.var.highly_variable))
sc.pl.highly_variable_genes(adata_combat)
sc.pp.pca(adata_combat, n_comps=30, use_highly_variable=True, svd_solver='arpack')
sc.pp.neighbors(adata_combat)
sc.tl.umap(adata_combat)
sc.tl.tsne(adata_combat)
# compare var_genes
var_genes_combat = adata_combat.var.highly_variable
print("With all data %d"%sum(var_genes_all))
print("With combat %d"%sum(var_genes_combat))
print("Overlap %d"%sum(var_genes_all & var_genes_combat))
print("With 2 batches %d"%sum(var_select))
print("Overlap %d"%sum(var_genes_combat & var_select))
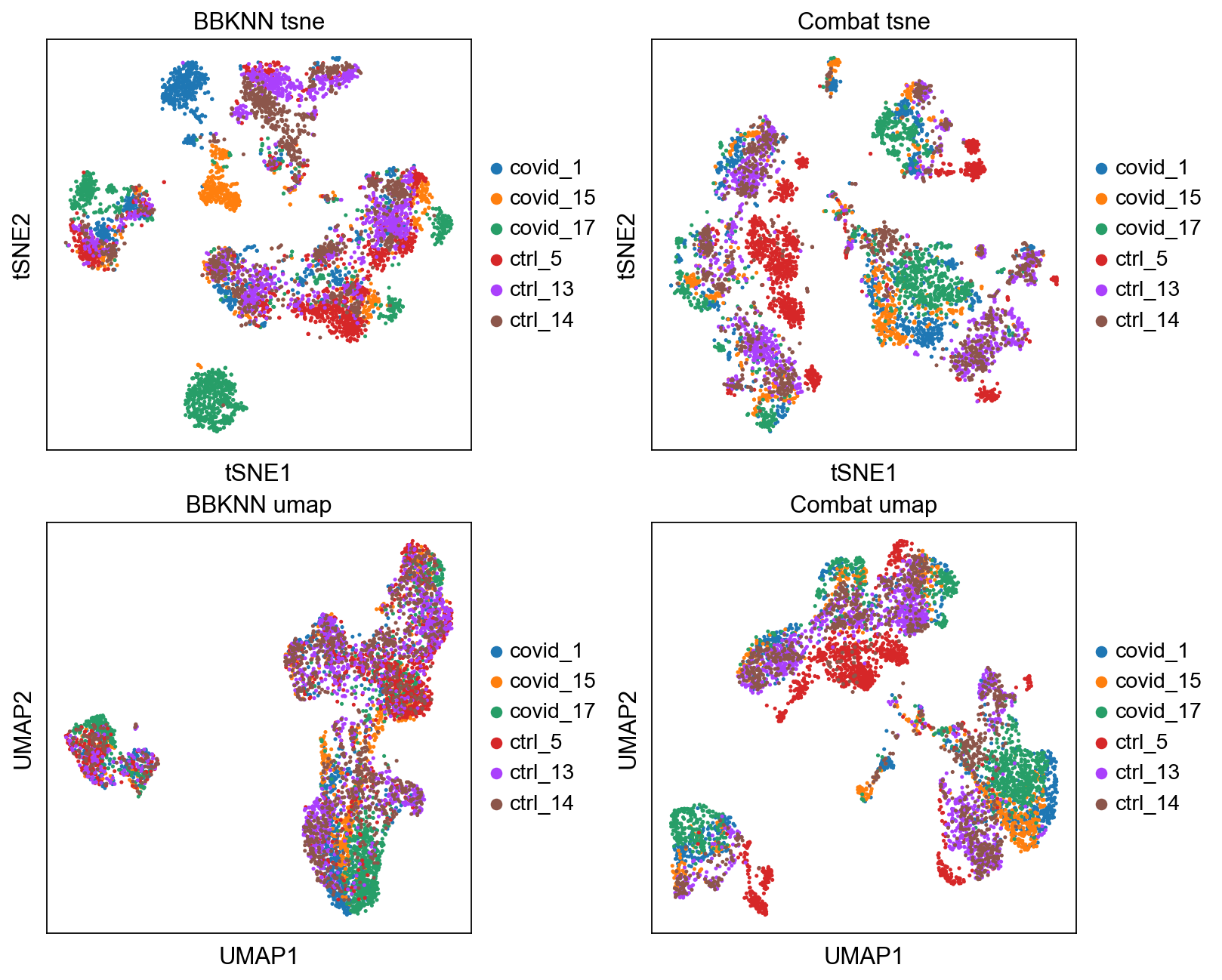
fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.tsne(adata2, color="sample", title="BBKNN tsne", ax=axs[0,0], show=False)
sc.pl.tsne(adata_combat, color="sample", title="Combat tsne", ax=axs[0,1], show=False)
sc.pl.umap(adata2, color="sample", title="BBKNN umap", ax=axs[1,0], show=False)
sc.pl.umap(adata_combat, color="sample", title="Combat umap", ax=axs[1,1], show=False)
#save to file
save_file = './data/results/scanpy_combat_corrected_covid.h5ad'
adata_combat.write_h5ad(save_file)
Scanorama¶
Try out Scanorama for data integration as well.
To run Scanorama, you need to install python-annoy (already included in conda environment) and scanorama with pip.
We can run scanorama to get a corrected matrix with the correct function, or to just get the data projected onto a new common dimension with the function integrate. Or both with the correct_scanpy and setting return_dimred=True. For now, run with just integration.
First we need to create individual AnnData objects from each of the datasets.
# split per batch into new objects.
batches = adata.obs['sample'].cat.categories.tolist()
alldata = {}
for batch in batches:
alldata[batch] = adata2[adata2.obs['sample'] == batch,]
alldata
import scanorama
#subset the individual dataset to the variable genes we defined at the beginning
alldata2 = dict()
for ds in alldata.keys():
print(ds)
alldata2[ds] = alldata[ds][:,var_genes]
#convert to list of AnnData objects
adatas = list(alldata2.values())
# run scanorama.integrate
scanorama.integrate_scanpy(adatas, dimred = 50)
#scanorama adds the corrected matrix to adata.obsm in each of the datasets in adatas.
adatas[0].obsm['X_scanorama'].shape
# Get all the integrated matrices.
scanorama_int = [ad.obsm['X_scanorama'] for ad in adatas]
# make into one matrix.
all_s = np.concatenate(scanorama_int)
print(all_s.shape)
# add to the AnnData object, create a new object first
adata_sc = adata.copy()
adata_sc.obsm["Scanorama"] = all_s
# tsne and umap
sc.pp.neighbors(adata_sc, n_pcs =30, use_rep = "Scanorama")
sc.tl.umap(adata_sc)
sc.tl.tsne(adata_sc, n_pcs = 30, use_rep = "Scanorama")
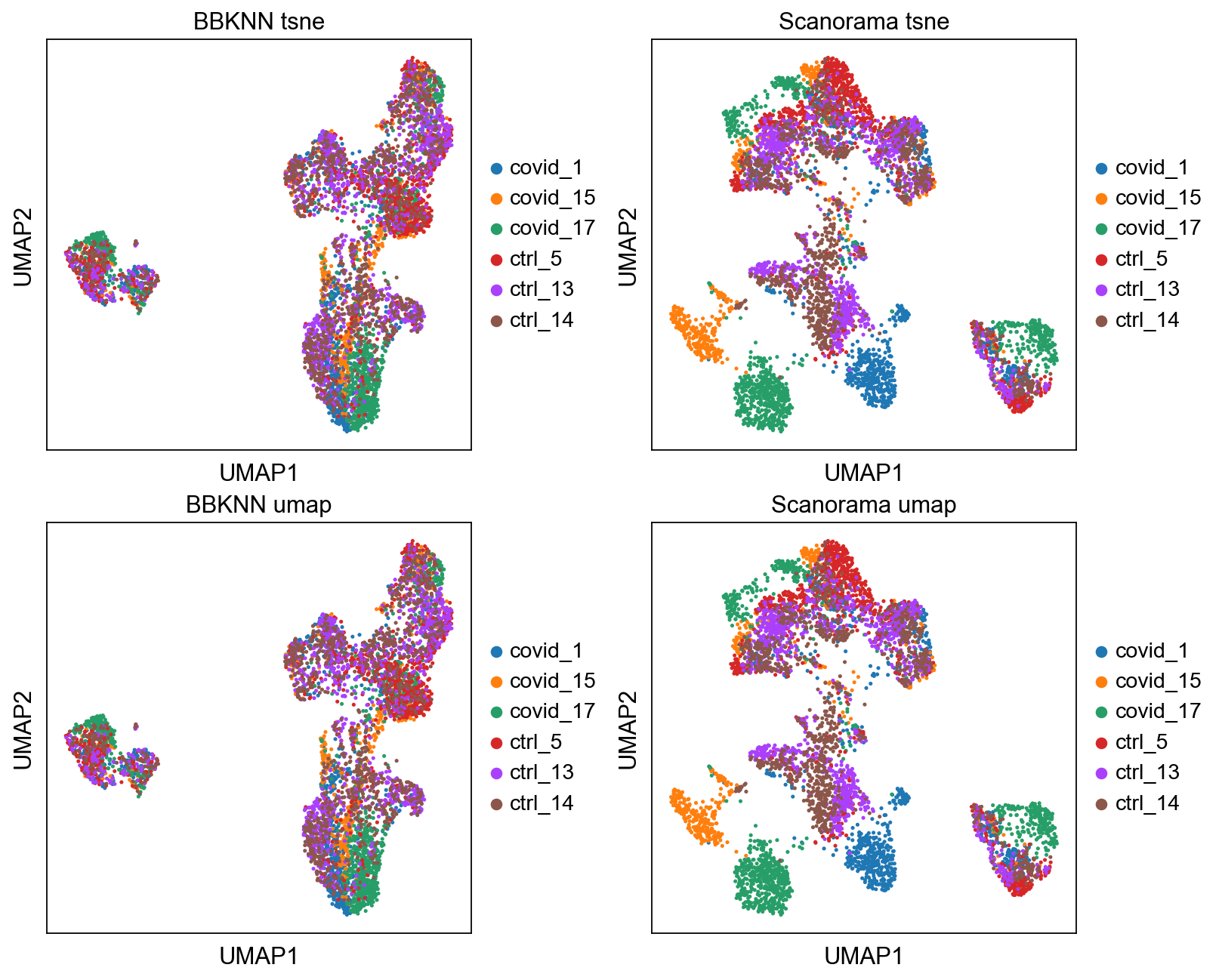
fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.umap(adata2, color="sample", title="BBKNN tsne", ax=axs[0,0], show=False)
sc.pl.umap(adata, color="sample", title="Scanorama tsne", ax=axs[0,1], show=False)
sc.pl.umap(adata2, color="sample", title="BBKNN umap", ax=axs[1,0], show=False)
sc.pl.umap(adata, color="sample", title="Scanorama umap", ax=axs[1,1], show=False)
#save to file
save_file = './data/results/scanpy_scanorama_corrected_covid.h5ad'
adata_sc.write_h5ad(save_file)
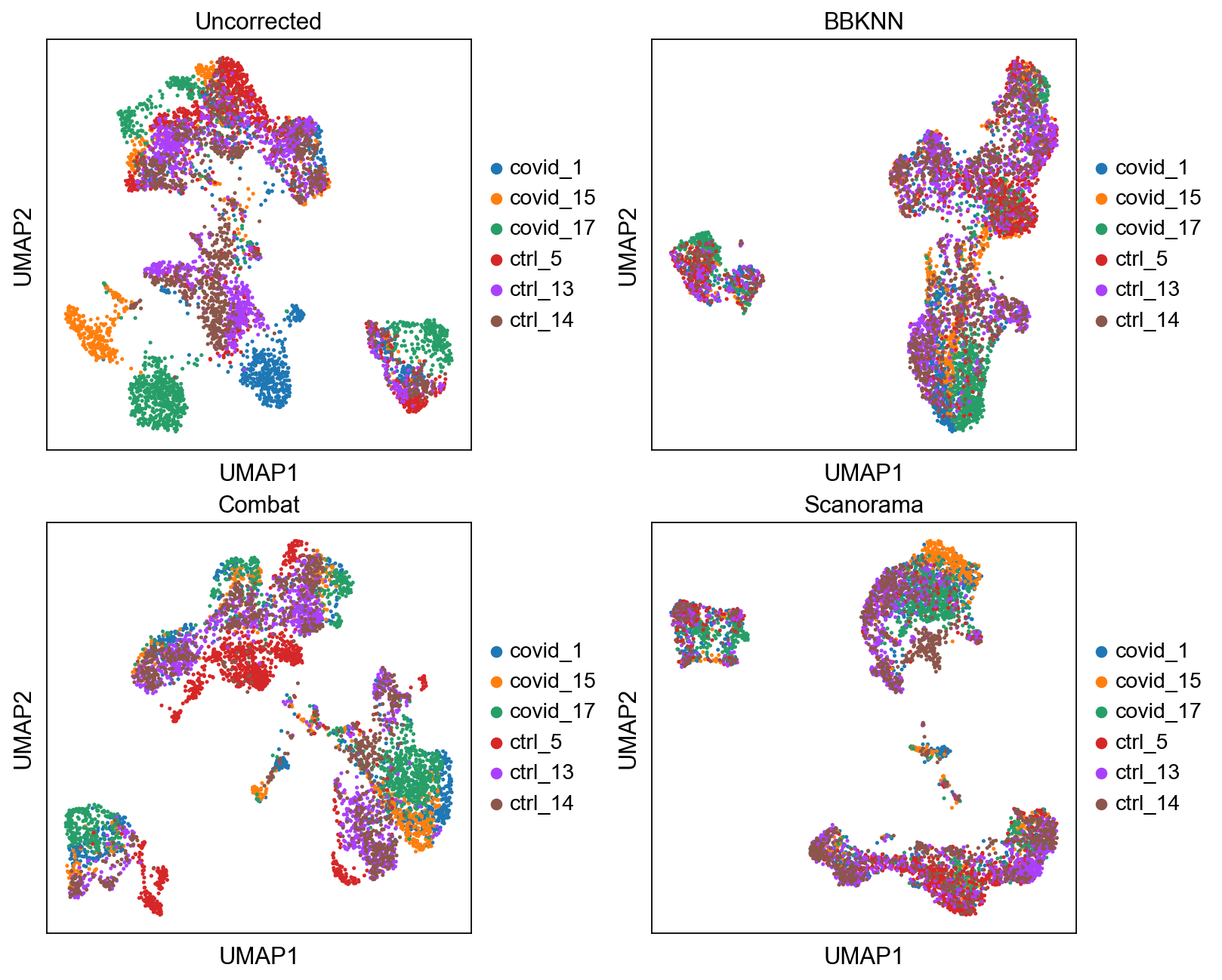
Compare all¶
Plot umap of all the methods we tested here. Which do you think looks better and why?
fig, axs = plt.subplots(2, 2, figsize=(10,8),constrained_layout=True)
sc.pl.umap(adata, color="sample", title="Uncorrected", ax=axs[0,0], show=False)
sc.pl.umap(adata2, color="sample", title="BBKNN", ax=axs[0,1], show=False)
sc.pl.umap(adata_combat, color="sample", title="Combat", ax=axs[1,0], show=False)
sc.pl.umap(adata_sc, color="sample", title="Scanorama", ax=axs[1,1], show=False)
Your turn¶
Have a look at the documentation for BBKNN https://scanpy.readthedocs.io/en/latest/generated/scanpy.external.pp.bbknn.html#scanpy-external-pp-bbknn
Try changing some of the parameteres in BBKNN, such as distance metric, number of PCs and number of neighbors. How does the results change with different parameters? Can you explain why?