Clustering
Created by: Ahmed Mahfouz
Overview
In this tutorial we will look at different approaches to clustering scRNA-seq datasets in order to characterize the different subgroups of cells. Using unsupervised clustering, we will try to identify groups of cells based on the similarities of the transcriptomes without any prior knowledge of the labels.
Load required packages:
suppressMessages(require(tidyverse))
suppressMessages(require(Seurat))
suppressMessages(require(cowplot))
suppressMessages(require(scater))
suppressMessages(require(scran))
suppressMessages(require(igraph))
Datasets
In this tutorial, we will use a small dataset of cells from developing
mouse embryo Deng et
al. 2014. We have
preprocessed the dataset and created a SingleCellExperiment object in
advance. We have also annotated the cells with the cell types identified
in the original publication (it is the cell_type2 column in the
colData slot).
#load expression matrix
deng <- readRDS("session-clustering_files/deng-reads.rds")
deng
## class: SingleCellExperiment
## dim: 22431 268
## metadata(0):
## assays(2): counts logcounts
## rownames(22431): Hvcn1 Gbp7 ... Sox5 Alg11
## rowData names(10): feature_symbol is_feature_control ...
## total_counts log10_total_counts
## colnames(268): 16cell 16cell.1 ... zy.2 zy.3
## colData names(30): cell_type2 cell_type1 ... pct_counts_ERCC
## is_cell_control
## reducedDimNames(0):
## spikeNames(1): ERCC
#look at the cell type annotation
table(colData(deng)$cell_type2)
##
## 16cell 4cell 8cell early2cell earlyblast late2cell
## 50 14 37 8 43 10
## lateblast mid2cell midblast zy
## 30 12 60 4
Feature selection
The first step is to decide which genes to use in clustering the cells. Single cell RNA-seq can profile a huge number of genes in a lot of cells. But most of the genes are not expressed enough to provide a meaningful signal and are often driven by technical noise. Including them could potentially add some unwanted signal that would blur the biological variation. Moreover gene filtering can also speed up the computational time for downstream analysis.
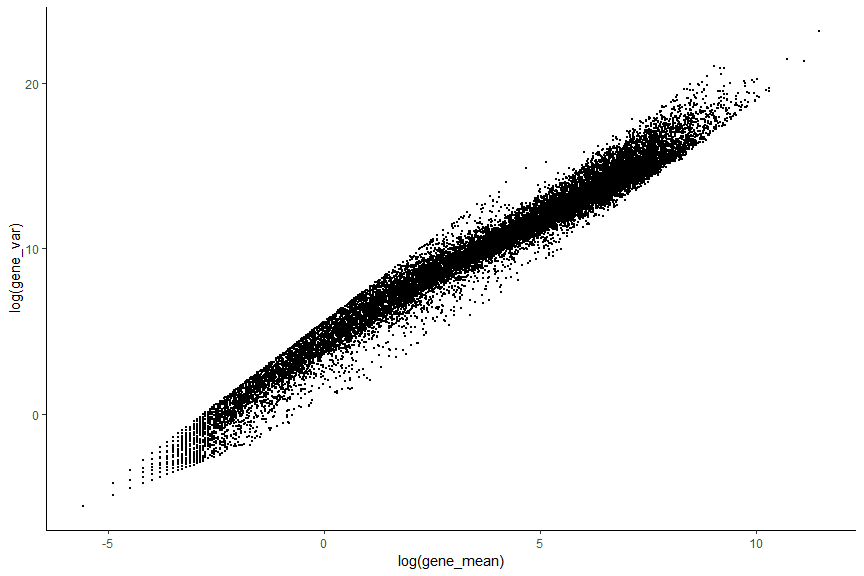
First let’s have a look at the average expression and the variance of all genes. Which genes seem less important and which are likely to be technical noise?
#Calculate gene mean across cell
gene_mean <- rowMeans(counts(deng))
#Calculate gene variance across cell
gene_var <- rowVars(counts(deng))
#ggplot plot
gene_stat_df <- tibble(gene_mean,gene_var)
ggplot(data=gene_stat_df ,aes(x=log(gene_mean), y=log(gene_var))) + geom_point(size=0.5) + theme_classic()
Filtering out low abundance genes
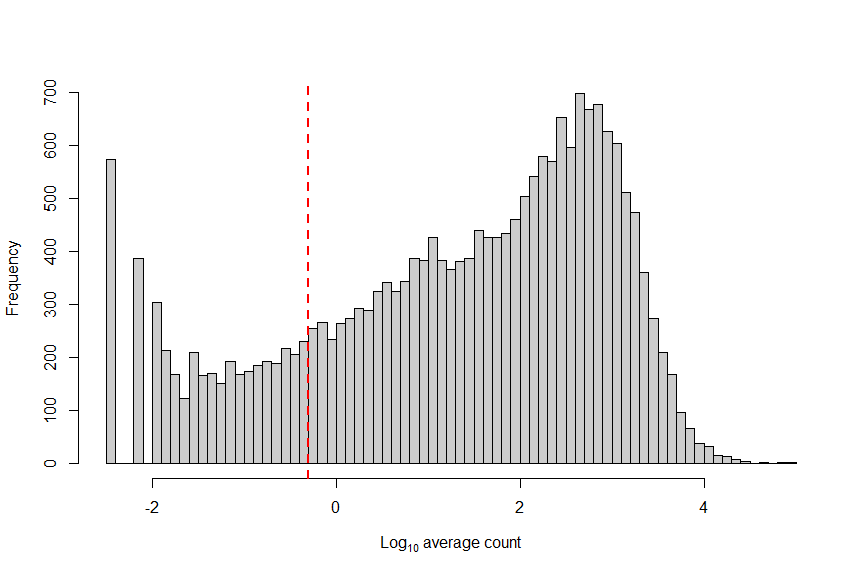
Low-abundance genes are mostly non-informative and are not representative of the biological variance of the data. They are often driven by technical noise such as dropout event. However, their presence in downstream analysis leads often to a lower accuracy since they can interfere with some statistical model that will be used and also will pointlessly increase the computational time which can be critical when working with very large data.
abundant_genes <- gene_mean >= 0.5 #Remove Low abundance genes
# plot low abundance gene filtering
hist(log10(gene_mean), breaks=100, main="", col="grey80",
xlab=expression(Log[10]~"average count"))
abline(v=log10(0.5), col="red", lwd=2, lty=2)
#remove low abundance gene in SingleCellExperiment Object
deng <- deng[abundant_genes,]
dim(deng)
## [1] 17093 268
Filtering genes that are expressed in very few cells
We can also filter some genes that are in a small number of cells. This procedure would remove some outlier genes that are highly expressed in one or two cells. These genes are unwanted for further analysis since they mostly comes from an irregular amplification of artifacts. It is important to note that we might not want to filter with this procedure when the aim of the analysis is to detect a very rare subpopulation in the data.
#Calculate the number of non zero expression for each genes
numcells <- nexprs(deng, byrow=TRUE)
#Filter genes detected in less than 5 cells
numcells2 <- numcells >= 5
deng <- deng[numcells2,]
dim(deng)
## [1] 16946 268
Detecting Highly Variable Genes
HVG assumes that if genes have large differences in expression across cells some of those differences are due to biological difference between the cells rather than technical noise. However,there is a positive relationship between the mean expression of a gene and the variance in the read counts across cells. Keeping only high variance genes, will lead to keeping a lot of highly expressed housekeeping genes that are expressed in every cells and are not representative of the biological variance. This relationship must be corrected for to properly identify HVGs.
We can use one of the following methods (RUN ONLY ONE) to determine the highly variable genes.
Option 1: Model the coefficient of variation as a function of the mean.
# out <- technicalCV2(deng, spike.type=NA, assay.type= "counts")
# out$genes <- rownames(deng)
# out$HVG <- (out$FDR<0.05)
# as_tibble(out)
#
# # plot highly variable genes
# ggplot(data = out) + geom_point(aes(x=log2(mean), y=log2(cv2), color=HVG), size=0.5) + geom_point(aes(x=log2(mean), y=log2(trend)), color="red", size=0.1)
#
# ## save the HVG into metadata for safekeeping
# metadata(deng)$hvg_genes <- rownames(deng)[out$HVG]
Option 2: Model the variance of the biological component as a function of the mean.
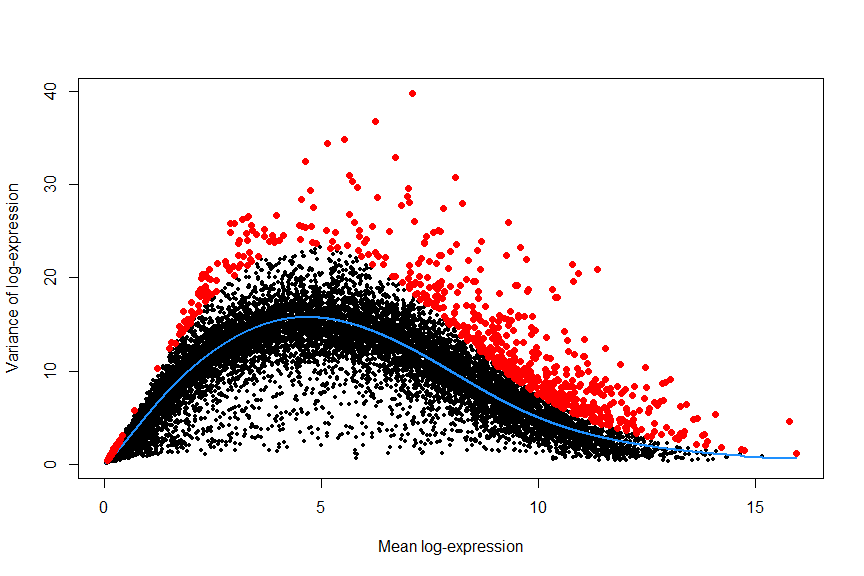
First we estimation the variance in expression for each gene, followed by decomposition of the variance into biological and technical components. HVGs are then identified as those genes with the largest biological components. This avoids prioritizing genes that are highly variable due to technical factors such as sampling noise during RNA capture and library preparation. see the scran vignette for details.
fit <- trendVar(deng, parametric=TRUE, use.spikes = FALSE)
dec <- decomposeVar(deng, fit)
dec$HVG <- (dec$FDR<0.00001)
hvg_genes <- rownames(dec[dec$FDR < 0.00001, ])
# plot highly variable genes
plot(dec$mean, dec$total, pch=16, cex=0.6, xlab="Mean log-expression",
ylab="Variance of log-expression")
o <- order(dec$mean)
lines(dec$mean[o], dec$tech[o], col="dodgerblue", lwd=2)
points(dec$mean[dec$HVG], dec$total[dec$HVG], col="red", pch=16)
## save the decomposed variance table and hvg_genes into metadata for safekeeping
metadata(deng)$hvg_genes <- hvg_genes
metadata(deng)$dec_var <- dec
Dimensionality reduction
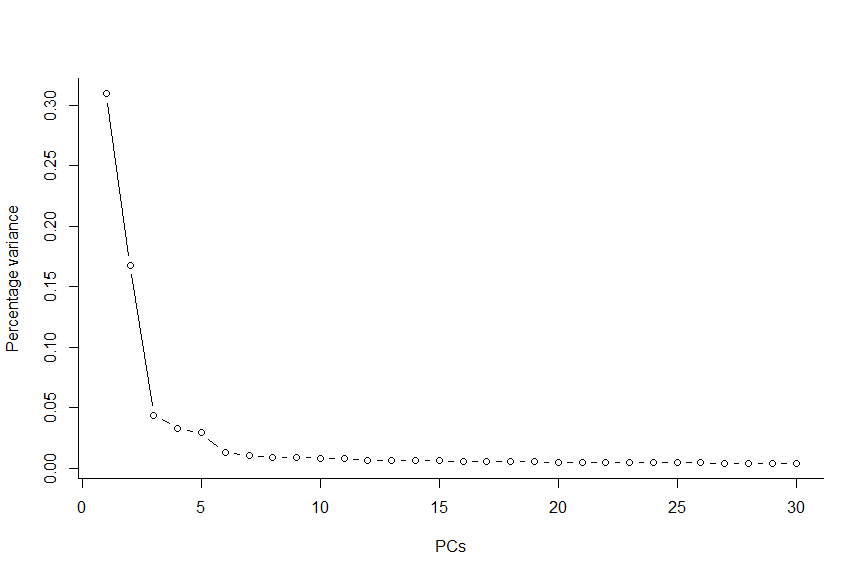
The clustering problem is computationally difficult due to the high level of noise (both technical and biological) and the large number of dimensions (i.e. genes). We can solve these problems by applying dimensionality reduction methods (e.g. PCA, tSNE, and UMAP)
#PCA (select the number of components to calculate)
deng <- runPCA(deng, method = "irlba",
ncomponents = 30,
feature_set = metadata(deng)$hvg_genes)
#Make a scree plot (percentage variance explained per PC) to determine the number of relevant components
X <- attributes(deng@reducedDims$PCA)
plot(X$percentVar~c(1:30), type="b", lwd=1, ylab="Percentage variance" , xlab="PCs" , bty="l" , pch=1)
Make a PCA plot (PC1 vs. PC2)
plotReducedDim(deng, "PCA", colour_by = "cell_type2")
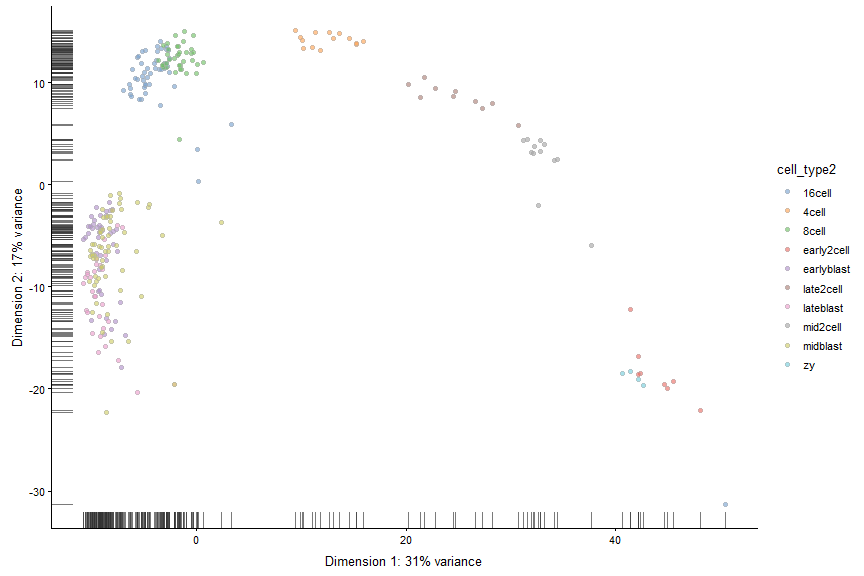
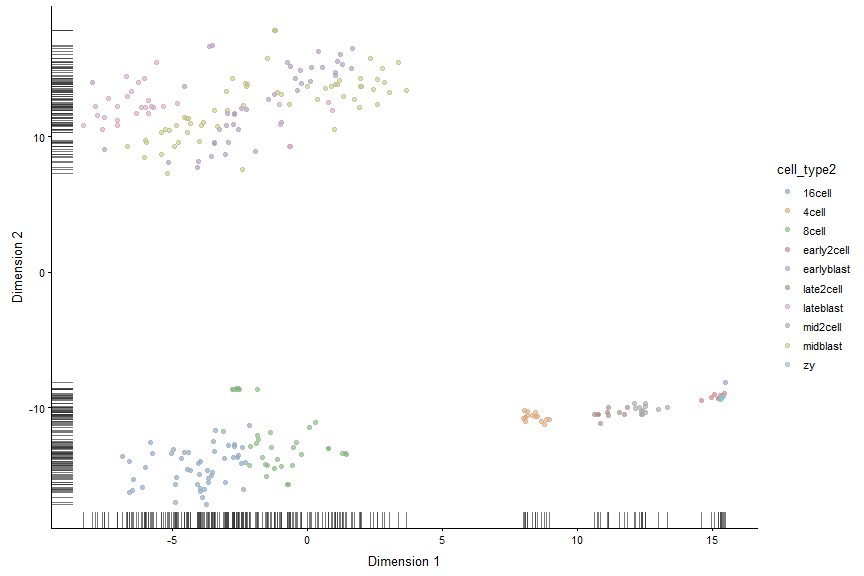
Make a tSNE plot Note: tSNE is a stochastic method. Everytime you run it you will get slightly different results. For convenience we can get the same results if we seet the seed.
#tSNE
deng <- runTSNE(deng,
perplexity = 30,
feature_set = metadata(deng)$hvg_genes,
set.seed = 1)
plotReducedDim(deng, "TSNE", colour_by = "cell_type2")
Clustering
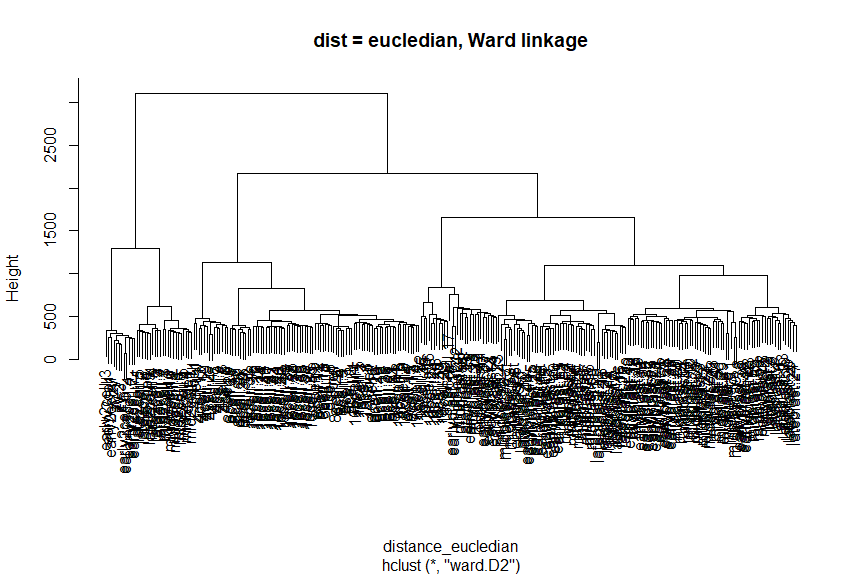
Hierarchical clustering
# Calculate Distances (default: Eucledian distance)
distance_eucledian <- dist(t(logcounts(deng)))
#Perform hierarchical clustering using ward linkage
ward_hclust_eucledian <- hclust(distance_eucledian,method = "ward.D2")
plot(ward_hclust_eucledian, main = "dist = eucledian, Ward linkage")
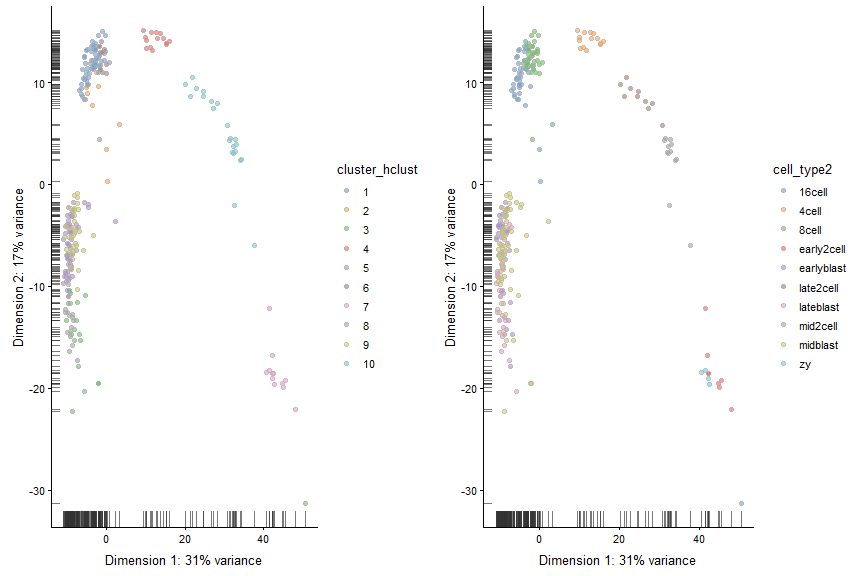
Now cut the dendrogram to generate 10 clusters and plot the cluster labels on the PCA plot.
#Cutting the cluster tree to make 10 groups
cluster_hclust <- cutree(ward_hclust_eucledian,k = 10)
colData(deng)$cluster_hclust <- factor(cluster_hclust)
plot_grid(plotReducedDim(deng, "PCA", colour_by = "cluster_hclust"),
plotReducedDim(deng, "PCA", colour_by = "cell_type2"))
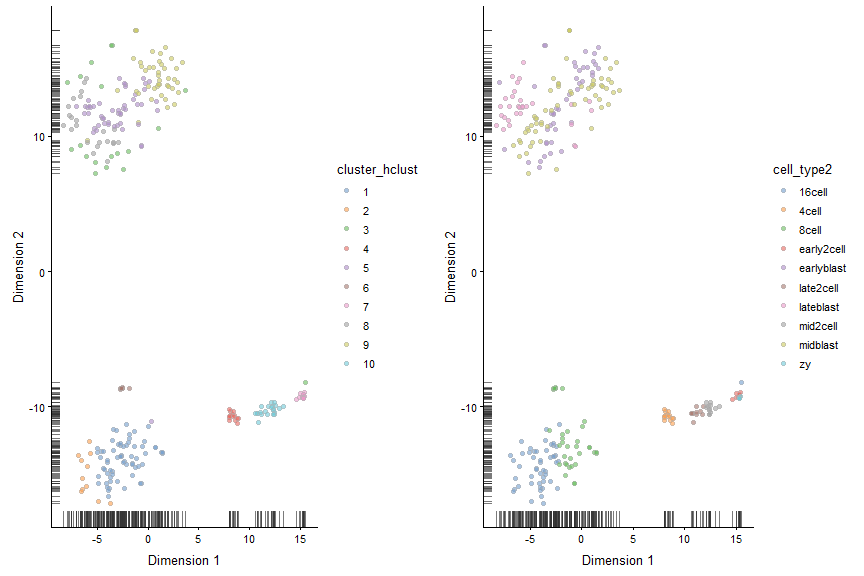
Plot the cluster labels on the tSNE plot.
plot_grid(plotReducedDim(deng, "TSNE", colour_by = "cluster_hclust"),
plotReducedDim(deng, "TSNE", colour_by = "cell_type2"))
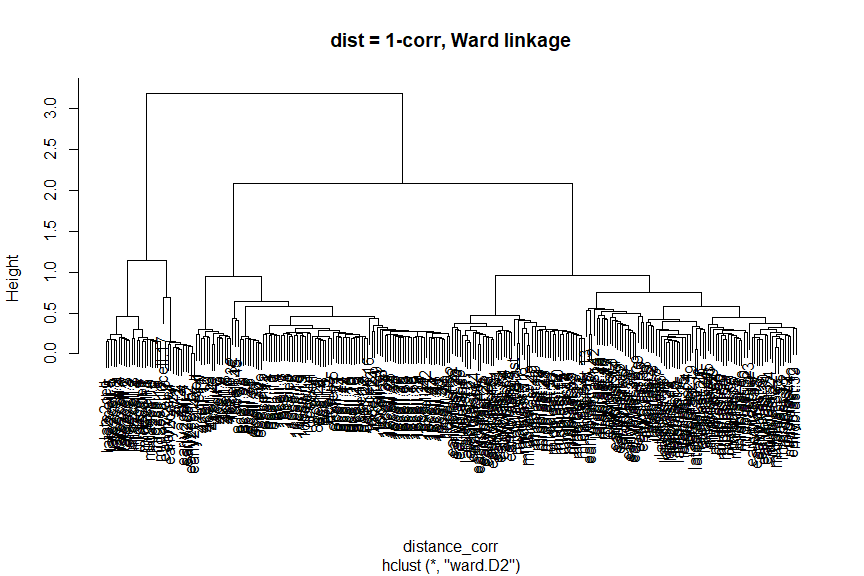
Now let’s try a different distance measure. A commonly used distance measure is 1 - correlation.
# Calculate Distances (1 - correlation)
C <- cor(logcounts(deng))
# Run clustering based on the correlations, where the distance will
# be 1-correlation, e.g. higher distance with lower correlation.
distance_corr <- as.dist(1-C)
#Perform hierarchical clustering using ward linkage
ward_hclust_corr <- hclust(distance_corr,method="ward.D2")
plot(ward_hclust_corr, main = "dist = 1-corr, Ward linkage")
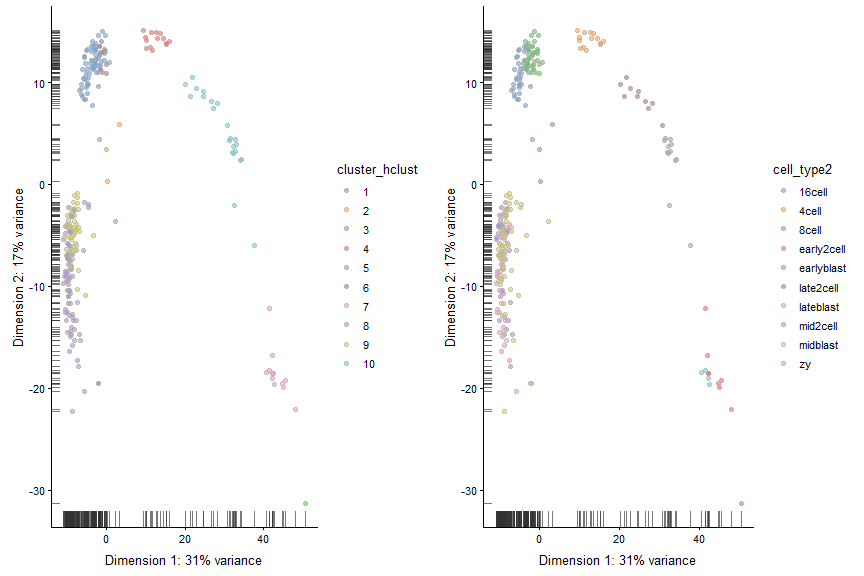
Again, let’s cut the dendrogram to generate 10 clusters and plot the cluster labels on the PCA plot.
#Cutting the cluster tree to make 10 groups
cluster_hclust <- cutree(ward_hclust_corr,k = 10)
colData(deng)$cluster_hclust <- factor(cluster_hclust)
plot_grid(plotReducedDim(deng, "PCA", colour_by = "cluster_hclust"),
plotReducedDim(deng, "PCA", colour_by = "cell_type2"))
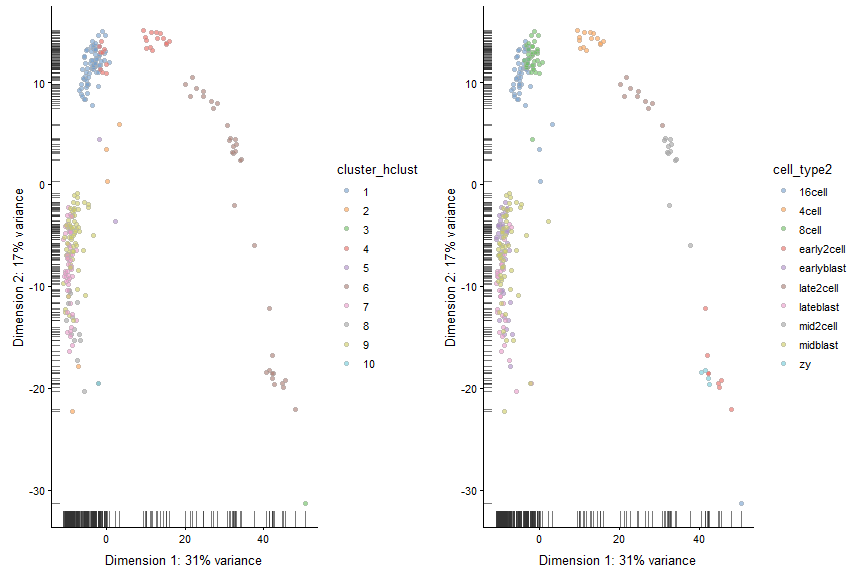
Instead of changing the distance metric, we can change the linkage method. Instead of using Ward’s method, let’s use complete linkage.
# Calculate distances (default: Eucledian distance)
distance_eucledian <- dist(t(logcounts(deng)))
#Perform hierarchical clustering using ward linkage
comp_hclust_eucledian <- hclust(distance_eucledian,method = "complete")
plot(comp_hclust_eucledian, main = "dist = eucledian, complete linkage")

Once more, let’s cut the dendrogram to generate 10 clusters and plot the cluster labels on the PCA plot.
#Cutting the cluster tree to make 10 groups
cluster_hclust <- cutree(comp_hclust_eucledian,k = 10)
colData(deng)$cluster_hclust <- factor(cluster_hclust)
plot_grid(plotReducedDim(deng, "PCA", colour_by = "cluster_hclust"),
plotReducedDim(deng, "PCA", colour_by = "cell_type2"))
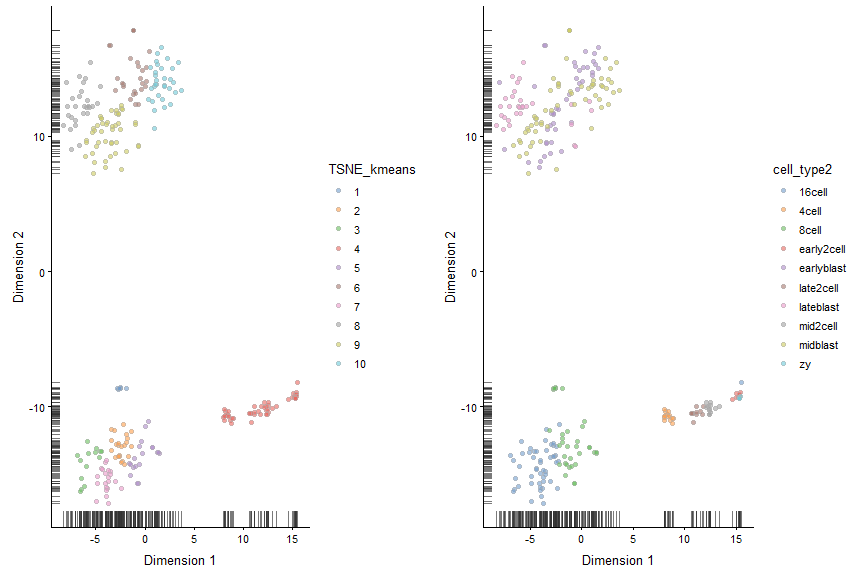
tSNE + Kmeans
# Do kmeans algorithm on tSNE coordinates
deng_kmeans <- kmeans(x = deng@reducedDims$TSNE,centers = 10)
TSNE_kmeans <- factor(deng_kmeans$cluster)
colData(deng)$TSNE_kmeans <- TSNE_kmeans
#Compare with ground truth
plot_grid(plotTSNE(deng, colour_by = "TSNE_kmeans"),
plotTSNE(deng, colour_by = "cell_type2"))
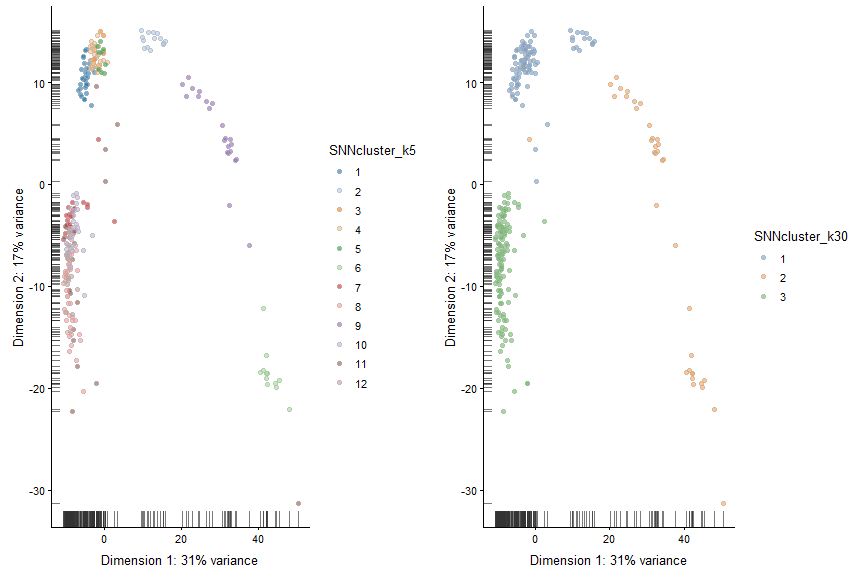
Graph Based Clustering
#k=5
#The k parameter defines the number of closest cells to look for each cells
SNNgraph_k5 <- buildSNNGraph(x = deng, k=5)
SNNcluster_k5 <- cluster_louvain(SNNgraph_k5)
colData(deng)$SNNcluster_k5 <- factor(SNNcluster_k5$membership)
p5<- plotPCA(deng, colour_by="SNNcluster_k5")+ guides(fill=guide_legend(ncol=2))
# k30
SNNgraph_k30 <- buildSNNGraph(x = deng, k=30)
SNNcluster_k30 <- cluster_louvain(SNNgraph_k30)
colData(deng)$SNNcluster_k30 <- factor(SNNcluster_k30$membership)
p30 <- plotPCA(deng, colour_by="SNNcluster_k30")
#plot the different clustering.
plot_grid(p5+ guides(fill=guide_legend(ncol=1)),p30)
Session info
sessionInfo()
## R version 3.5.3 (2019-03-11)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 17763)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_United States.1252
## [2] LC_CTYPE=English_United States.1252
## [3] LC_MONETARY=English_United States.1252
## [4] LC_NUMERIC=C
## [5] LC_TIME=English_United States.1252
##
## attached base packages:
## [1] parallel stats4 stats graphics grDevices utils datasets
## [8] methods base
##
## other attached packages:
## [1] igraph_1.2.4.1 scran_1.10.2
## [3] scater_1.10.1 SingleCellExperiment_1.4.1
## [5] SummarizedExperiment_1.12.0 DelayedArray_0.8.0
## [7] BiocParallel_1.16.6 matrixStats_0.54.0
## [9] Biobase_2.42.0 GenomicRanges_1.34.0
## [11] GenomeInfoDb_1.18.2 IRanges_2.16.0
## [13] S4Vectors_0.20.1 BiocGenerics_0.28.0
## [15] cowplot_0.9.4 Seurat_3.0.0
## [17] forcats_0.4.0 stringr_1.4.0
## [19] dplyr_0.8.0.1 purrr_0.3.2
## [21] readr_1.3.1 tidyr_0.8.3
## [23] tibble_2.1.1 ggplot2_3.1.1
## [25] tidyverse_1.2.1
##
## loaded via a namespace (and not attached):
## [1] readxl_1.3.1 backports_1.1.4
## [3] plyr_1.8.4 lazyeval_0.2.2
## [5] splines_3.5.3 listenv_0.7.0
## [7] digest_0.6.18 htmltools_0.3.6
## [9] viridis_0.5.1 gdata_2.18.0
## [11] magrittr_1.5 cluster_2.0.9
## [13] ROCR_1.0-7 limma_3.38.3
## [15] globals_0.12.4 modelr_0.1.4
## [17] R.utils_2.8.0 colorspace_1.4-1
## [19] rvest_0.3.3 ggrepel_0.8.1
## [21] haven_2.1.0 xfun_0.6
## [23] crayon_1.3.4 RCurl_1.95-4.12
## [25] jsonlite_1.6 survival_2.44-1.1
## [27] zoo_1.8-5 ape_5.3
## [29] glue_1.3.1 gtable_0.3.0
## [31] zlibbioc_1.28.0 XVector_0.22.0
## [33] Rhdf5lib_1.4.3 future.apply_1.2.0
## [35] HDF5Array_1.10.1 scales_1.0.0
## [37] edgeR_3.24.3 bibtex_0.4.2
## [39] Rcpp_1.0.1 metap_1.1
## [41] viridisLite_0.3.0 reticulate_1.12
## [43] rsvd_1.0.0 SDMTools_1.1-221.1
## [45] tsne_0.1-3 htmlwidgets_1.3
## [47] httr_1.4.0 gplots_3.0.1.1
## [49] RColorBrewer_1.1-2 ica_1.0-2
## [51] pkgconfig_2.0.2 R.methodsS3_1.7.1
## [53] locfit_1.5-9.1 dynamicTreeCut_1.63-1
## [55] labeling_0.3 tidyselect_0.2.5
## [57] rlang_0.3.4 reshape2_1.4.3
## [59] munsell_0.5.0 cellranger_1.1.0
## [61] tools_3.5.3 cli_1.1.0
## [63] generics_0.0.2 broom_0.5.2
## [65] ggridges_0.5.1 evaluate_0.13
## [67] yaml_2.2.0 npsurv_0.4-0
## [69] knitr_1.22 fitdistrplus_1.0-14
## [71] caTools_1.17.1.2 RANN_2.6.1
## [73] pbapply_1.4-0 future_1.13.0
## [75] nlme_3.1-140 R.oo_1.22.0
## [77] xml2_1.2.0 compiler_3.5.3
## [79] rstudioapi_0.10 beeswarm_0.2.3
## [81] plotly_4.9.0 png_0.1-7
## [83] lsei_1.2-0 statmod_1.4.30
## [85] stringi_1.4.3 lattice_0.20-38
## [87] Matrix_1.2-17 pillar_1.4.0
## [89] Rdpack_0.11-0 lmtest_0.9-37
## [91] BiocNeighbors_1.0.0 data.table_1.12.2
## [93] bitops_1.0-6 irlba_2.3.3
## [95] gbRd_0.4-11 R6_2.4.0
## [97] KernSmooth_2.23-15 gridExtra_2.3
## [99] vipor_0.4.5 codetools_0.2-16
## [101] MASS_7.3-51.4 gtools_3.8.1
## [103] assertthat_0.2.1 rhdf5_2.26.2
## [105] withr_2.1.2 sctransform_0.2.0
## [107] GenomeInfoDbData_1.2.0 hms_0.4.2
## [109] grid_3.5.3 rmarkdown_1.12
## [111] DelayedMatrixStats_1.4.0 Rtsne_0.15
## [113] lubridate_1.7.4 ggbeeswarm_0.6.0