Tidy Work in Tidyverse
RaukR 2022 • Advanced R for Bioinformatics
Marcin Kierczak
![]()
![]()
1 Introduction
Welcome to the hands-on workshop “Tidy Work in Tidyverse”. Most of the things necessary to complete the tutorials and challenges were covered in the lecture. However, sometimes the tasks require that you check the docs or search online. Not all our solutions are optimal. Let us know if you can do better or solve things in a different way. If stuck, look at hints, next google and if still stuck, turn to TA. It is a lot of material, do not fee bad if you do not solve all tasks. If you completed Challenge 3 you are good and have used the most important features of tidyverse! Good luck!
2 General exercises
Datasets are available here.
2.1 Pipes
Rewrite the following code chunks as pipes (Load package magrittr because tidyverse supports only the %>% pipe!):
2.1.1 Chunk 1
my_cars <- mtcars[, c(1:4, 10)]
my_cars <- my_cars[my_cars$disp > mean(my_cars$disp), ]
my_cars <- colMeans(my_cars)
mtcars %>%
select(c(1:4, 10)) %>%
filter(disp > mean(disp)) %>%
colMeans() -> my_carsWhat is wrong with our solution?
# It is better to have the result assigned on the left hand side: result <- expression. In this case the expression is the **whole** pipe.
# Our 'expression -> result' is correct but can easily be missed when reading the code.2.1.2 Chunk 2
The summary(x) function is a bit special: when you type summary(x) in the console, print is called in an implicit way. Pipe call does not do, so you will have to invoke print in an explicit way. But the %T>% does unbranch for one call only, you will have to make printing of the summary a one single composed call using {}.
summary(cars)
colSums(cars)
cars %T>% {print(summary(.))} %>% colSums()2.1.3 Chunk 3
Rewrite correlations to pipes.
cor(mtcars$gear, mtcars$mpg)
mtcars %$% cor(gear, mpg)cor(mtcars)
mtcars %>% cor()2.1.4 Chunk 4
Given is the dim_summary(nrows, ncols) function which takes matrix nrows and ncols as arguments and prints this info about its dimensions:
dim_summary <- function(nrows, ncols) {
print(
paste0('Matrix M has: ', nrows, ' rows and ', ncols, ' columns.')
)
}Rewrite the code chunks below as pipes:
distr1 <- rnorm(16)
M <- matrix(distr1, ncol = 4)
plot(M)
M <- M + sample(M)
dim_summary(nrows = nrow(M), ncols = ncol(M))distr2 <- rnorm(16)
N <- matrix(distr2, ncol = 4)
colnames(N) <- (letters[1:4])
summary(N)
N <- N + 0P <- M %x% t(N)
heatmap(P)
colnames(P) <- letters[1:dim(P)[2]]
cor(P[ ,'a'], P[ ,'i'])A class of functions, called the replacement functions are of the form function(arguments)<-value and rownames(x) <- c('a', 'b', 'c') is a good example of a replacement function. When writing pipes, we have bear in mind that whole function<- is the name of the replacement function and thus we have to use it as such in the pipe.
Sometimes, it may not be possible to put everything into one single pipe, the results of running two or more pipes have to be used in the final pipe.
dim_summary <- function(nrows, ncols) {
print(paste0('Matrix M has: ', nrows, ' rows and ', ncols, ' columns.'))
}
M <- rnorm(16) %>%
matrix(ncol = 4) %T>%
plot() %>%
`+`(., sample(.)) %T>%
{dim_summary(nrow(.), ncol(.))}
N <- rnorm(16) %>%
matrix(ncol = 4) %>%
`colnames<-`(letters[1:4]) %T>%
summary() %>% `+`(., 0)
P <- M %>%
`%x%`(., t(N)) %T>%
heatmap() %>%
`colnames<-`(letters[1:dim(.)[2]]) %>%
as_data_frame() %$%
cor(a, i)2.2 Tibbles
2.2.1 Task 1
- Convert the
mtcarsdataset to a tibblevehicles. - Select the number of cylinders (
cyl) variable using:- the
[[index]]accessor, - the
[[string]]accessor, - the
$accessor.
- the
- Do the same selection as above, but using pipe and placeholders (use all three ways of accessing a variable).
- Print the tibble.
- Print the 30 first rows of the tibble.
- Change the default behaviour of printing a tibble so that at least 15 and at most 30 rows are printed.
- What is the difference between the
tibble.print_maxanddplyr.print_min? Is there any? Test it. - Convert
vehiclesback to adata.framecalledautomobiles.
# 1
vehicles <- mtcars %>% as_tibble()
# 2
vehicles[['cyl']]
vehicles[[2]]
vehicles$cyl
# 3
vehicles %T>%
{print(.[['cyl']])} %T>%
{print(.[[2]])} %>%
.$cyl
# 4
vehicles
# 5
vehicles %>% head(n = 30)
# 6
options(tibble.print_min = 15, tibble.print_max = 30)
# 7
# In theory there should be no difference. dplyr imports tibble from the tibble package
# and dplyr.width, dplyr.print_min and dplyr.print_min are passed down to the tibble.
# But test both behaviours. First with only the tibble package loaded, later with dplyr # loaded.
# 8
automobiles <- as.data.frame(vehicles)2.2.2 Task 2
Create the following tibble using tribble():
tab <- tribble(
~id, ~event, ~date,
1, 'success', '24-04-2017',
2, 'failed', '25-04-2017',
3, 'failed', '25-04-2017',
4, 'success', '27-04-2017'
)2.2.3 Task 3
Compare the performance of as.data.frame(), as_data_frame() and as_tibble() on a
100 x 30 matrix filled with random integers. Use package microbenchmark. Fill in your result here in the Tidyverse Lab sheet, Tibbles – performance.
tst <- replicate(30, sample(100), simplify = TRUE)
colnames(tst) = paste0(rep('col', times = dim(tst)[2]), 1:dim(tst)[2])
microbenchmark::microbenchmark(
as.data.frame(tst),
as_data_frame(tst),
as_tibble(tst)
)2.2.4 Task 4
Do you think tibbles are lazy? Try to create a tibble that tests whether lazy evaluation applies to tibbles too.
tibble(x = sample(1:10, size = 10, replace = T), y = log10(x))2.3 Parsing
Parse the following vectors using parse_ functions:
vec1 <- c(1, 7.2, 3.84, -5.23)– parse it as double (any problems? why?).- now parse the same vector
c(1, 7.2, 3.84, -5.23)as integer. What happens? - Can you still parse it as integer somehow?
- Parse as double
vec2 <- c('2', '3,45', '?', '-7,28') - Parse correctly
vec3 <- c('2', '3,45', '?', '-7.28') - Parse the following guessing the parser:
vec4 <- c('barrel: 432.7$', 'liter: 15.42PLN', 'gallon costs approx 32.1SEK', 'sunny, wind gusts up till 55m/s') - Can you parse
vec4as number? Do it if you can. - Parse
vec5 <- "25 Dec 2015"as date (hint:?parse_date()). - Parse
10_Jul_1410as date.
vec1 <- c(1, 7.2, 3.84, -5.23)
vec2 <- c('2', '3,45', '?', '-7,28')
vec3 <- c('2', '3,45', '?', '-7.28')
vec4 <- c('barrel: 432.7$', 'liter: 15.42PLN', 'gallon costs approx 32.1SEK', 'sunny, wind gusts up till 55m/s')
vec5 <- "25 Dec 2015"
parse_double(vec1)
parse_integer(vec1)
parse_integer(as.integer(vec1)) # Is it the best way? Hint: rounding.
parse_double(vec2, na = '?', locale = locale(decimal_mark = ','))
parse_number(vec2, na = '?', locale = locale(decimal_mark = ','))
guess_parser(vec4)
parse_guess(vec4)
# Yes, you can:
parse_number(vec4)
parse_date(vec5, format="%d %b %Y")
parse_date("10_Jul_1410", format="%d%.%b%.%Y")3 NYC flights Challenge
The nycflights13 package contains information about all flights that departed from NYC (i.e., EWR, JFK and LGA) in 2013: 336,776 flights with 16 variables. To help understand what causes delays, it also includes a number of other useful datasets: weather, planes, airports, airlines. We will use it to train working with tibbles and dplyr.
3.1 Task 1 – selecting column
- load the
nycflights13package (install if necessary), - read about the data in the package docs,
- inspect the
flightstibble. - select all columns but
carrierandarr_time, - select
carrier,tailnumandorigin, - hide columns from
daythroughcarrier, - select all columns that have to do with
arrival (hint:?tidyselect), - select columns based on a vector
v <- c("arr_time", "sched_arr_time", "arr_delay"), - rename column
desttodestinationusing:select()andrename()
What is the difference between the two approaches?
install.packages('nycflights13')
library('nycflights13')
?nycflights13
flights
flights %>% select(-carrier, -arr_time)
flights %>% select(carrier, tailnum, origin)
flights %>% select(-(day:carrier))
flights %>% select(contains('arr_')) # or
v <- c("arr_time", "sched_arr_time", "arr_delay")
flights %>% select(v) # ambiguous, or better
flights %>% select(all_of(v))
flights %>% select(destination = dest)
flights %>% rename(destination = dest)
# select keeps only the renamed column while rename returns the whole dataset
# with the column renamed3.2 Task 2 – filtering rows
- filter only the flights that arrived ahead of schedule,
- filter the flights that had departure delay between 10 and 33,
- fish out all flights with unknown arrival time,
- retrieve rows 1234:1258 (hint:
?slice), - sample (
?sample_n()) 3 random flights per day in March, - show 5 most departure-delayed flights in January per carrier,
- retrieve all
unique()routes and sort them by destination, - retrieve all
distinct()routes and sort them by destination, - is
unique()more efficient thandistinct()?
flights %>% filter(arr_delay < 0)
flights %>% filter(dep_delay >= 10, dep_delay <= 33) # or
flights %>% filter(between(dep_delay, 10, 33))
flights %>% filter(is.na(arr_time))
flights %>% slice(1234:1258)
nycflights13::flights %>% filter(month == 3) %>%
group_by(day) %>%
slice_sample(n = 3)
nycflights13::flights %>%
filter(month == 1) %>%
group_by(carrier) %>%
slice_max(dep_delay, n = 5)
nycflights13::flights %>%
select(origin, dest) %>%
unique() %>%
arrange(dest)
nycflights13::flights %>%
mutate(route = paste(origin, dest, sep="-")) %>%
select(route) %>%
unique()
nycflights13::flights %>%
select(origin, dest) %>%
distinct() %>%
arrange(dest)
# or
flights %>%
mutate(route = paste(origin, dest, sep="-")) %>%
distinct(route)
microbenchmark::microbenchmark(
unique = nycflights13::flights %>%
select(origin, dest) %>%
unique() %>%
arrange(dest),
distinct = nycflights13::flights %>%
distinct(origin, dest) %>%
arrange(dest),
times = 10L
)
Distinct is faster.3.3 Task 3 – Trans(mutations)
air_timeis the amount of time in minutes spent in the air. Add a new columnair_spdthat will contain aircraft’s airspeed in mph,as above, but keep only the new
air_spdvariable,use
rownames_to_column()onmtcarsto add car model as an extra column,
flights %>% mutate(air_spd = distance/(air_time / 60))
flights %>% transmute(air_spd = distance/(air_time / 60))
mtcars %>% rownames_to_column('model')3.4 Task 4 – groups and counts
- use
group_by(),summarise()andn()to see how many planes were delayed (departure) every month,
flights %>%
filter(dep_delay > 0) %>%
group_by(month) %>%
summarise(num_dep_delayed = n())- do the same but using
tally()andcount(),
flights %>%
filter(dep_delay > 0) %>%
group_by(month) %>%
tally()
flights %>%
filter(dep_delay > 0) %>%
count(month)- what was the mean
dep_delayper month?
flights %>%
group_by(month) %>%
summarise(mean_dep_delay = mean(dep_delay, na.rm = T))- count the number of incoming delayed flights from each unique origin and sort origins by this count (descending),
flights %>%
filter(arr_delay > 0) %>%
group_by(origin) %>%
summarise(cnt = n()) %>%
arrange(desc(cnt))- do the same using
tally()
flights %>%
filter(arr_delay > 0) %>%
group_by(origin) %>%
tally(sort = T)- use
summarise()to sum totaldep_delayper month in hours,
flights %>%
group_by(month) %>%
summarize(tot_dep_delay = sum(dep_delay/60, na.rm = T))- use the
wtparameter ofcount()(works withtally()too) to achieve the same,
flights %>%
group_by(month) %>%
count(wt = dep_delay/60)- run
group_size()oncarrierwhat does it return?
flights %>%
group_by(carrier) %>%
group_size()- use
n_groups()to check the number of unique origin-carrier pairs,
flights %>%
group_by(carrier) %>%
n_groups() Note on ungroup: Depending on the version of dplyr, you may or may need to use the ungroup() if you want to group your data on some other variables:
flights %>%
group_by(origin) %>%
mutate(mean_delay_orig = (mean(dep_delay, na.rm = T) + mean(arr_delay, na.rm = T)) / 2) %>%
ungroup() %>%
group_by(carrier) %>%
mutate(mean_delay_carr = (mean(dep_delay, na.rm = T) + mean(arr_delay, na.rm = T)) / 2) %>%
select(origin, carrier, mean_delay_orig, mean_delay_carr)may or may need ungroup depending on your dplyr version. In the newer versions, summarise and mutate drop one aggregation level.
3.5 Task 5 – joins
Given the following tibbles set1 and set2:
set1 <- tribble(
~id, ~color,
'id1', 'grey',
'id1', 'red',
'id2', 'green',
'id3', 'blue'
)
set2 <- tribble(
~id, ~size,
'id2', 'XL',
'id3', 'M',
'id4', 'M'
)
set1
set2Perform joins on id that result in the grey area from the Venn diagrams below. We have not talked about all possible joins, so read the docs if you do not know which join to use.

left_join(set1, set2, by = 'id')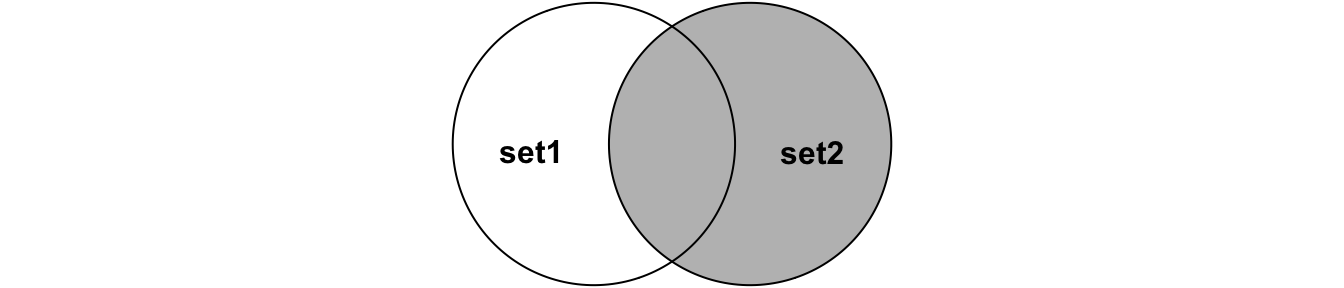
right_join(set1, set2, by = 'id')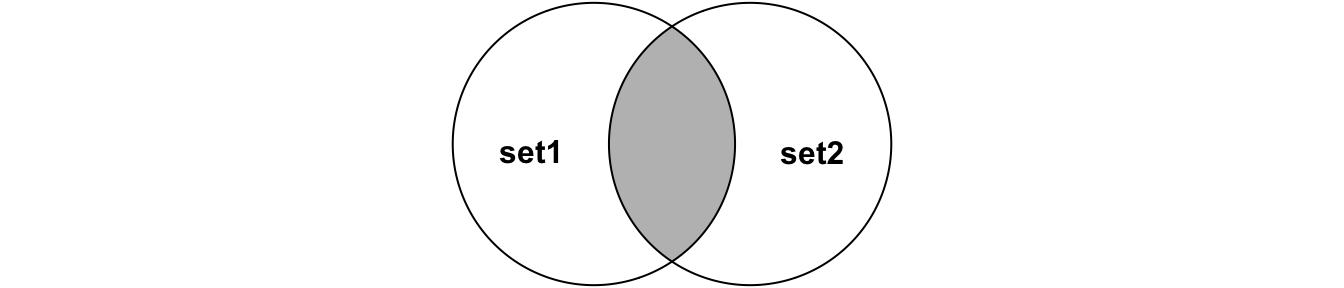
inner_join(set1, set2, by = 'id') # or
semi_join(set1, set2, by = 'id') # semi_join removes duplicates in x
# and also returns only columns from x.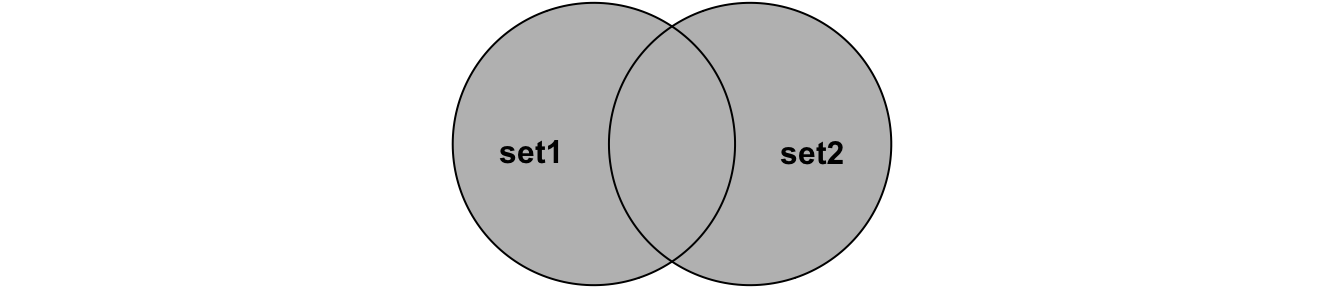
full_join(set1, set2, by = 'id') # or
anti_join(set1, set2, by = 'id') # or4 Tidying data
Now time to do some data tidying. First install a package with some untidy data:
#renv::install("rstudio/EDAWR")
library(EDAWR)- tidy
casesso that years are not in separate columns, but in the column calledyearcontaining a value per each year.
tidy_cases <- cases %>%
pivot_longer(-country, names_to = "year", values_to = "count")- now time for the
pollutiondataset. Tidy it so that there separate columns forlargeandsmallpollution values.
tidy_pollution <- pollution %>%
pivot_wider(city, names_from = size, values_from = amount)- the
stormsdataset contains thedatecolumn. Make it into 3 columns:year,monthandday. Store the result astidy_storms
tidy_storms <- storms %>%
separate(col = date,
into = c("year", "month", "day"),
sep = "-")- now, merge
year,monthanddayintidy_stormsinto adatecolumn again but in the “DD/MM/YYYY” format.
tidy_storms %>% unite(col = "date", 4:6, sep = "/")5 Nanopore Channel Activity Challenge
5.1 Introduction
You will be given a fastq file coming from MinION sequencer (Oxford Nanopore). This file contains test reads from the chicken genome. The flow-cell used here has 512 channels, each channel consists of 4 pores and only one pore is active at a time. Once your sequence gets stuck for some reason, the device will attempt to remove it from the pore by playing with reversing polarity on that pore. If this was successful, the pore will be re-used. Your task will be to visualise reading events from the meta-data in the fastq dataset and to see how each and every channel behaved. Also, you will plot the distribution of reading times.
Datasets are available here.
5.2 Preparations
First, we will need to load the necessary libraries. I will give you a hint – you need the following libraries:
here– not necessary, but it is an elegant way of reading the data locally from the project folder,tidyverse– well, quite obvious why,ShortReadfrom Bioconductor – to deal with short reads infastq,lubridate– to figure out reading times.
library(here)
library(tidyverse)
library(ShortRead)
library(lubridate)5.3 Reading data
Now, let’s read the fastq data. Check ShortRead documentation to see how to read our fastq file. Also, try to use package here. If you write: data <- here::here('data/my.fastq'), the my.fastq file will be read from the data folder which is a sub folder of your project root, i.e. the folder where your r script is. It is a good practice and also prevents Jenny Bryan from coming to your office and setting your computer on fire.
Now think a bit, to plot reading events, do we need all the data in the file or only some specific part? You may want to see some few first lines of the fastq to learn about the data structure.
raw_data <- here::here('topic_tidyverse_Marcin/lab/lab_assets/FUL1_fastqs_GRID2.fastq')
f <- ShortRead::FastqFile(raw_data)
rfq <- ShortRead::readFastq(f)
headers <- rfq@id
close(f)5.4 Extracting information you need
In this step, we are extracting data from fastq headers of each and every read in the fastq file. Not super efficient and perhaps the slowest step of the whole analyses. Can you do it better than our example solution?
Desired output: a table (tibble/data.frame) with reads as rows and meta-data as columns.
Use strsplit() to explode string data into columns and str_remove_all() to get rid of unwanted characters. Since we did not talk much about regular expressions and the stringr package:
- To split string on a particular character, group of characters use
strsplit. Here we split on comma.
text <- "This text is long, or not?"
strsplit(text, ',')- To remove everything following a given character, e.g. comma:
str_remove_all(text, ",.*")
data <- dplyr::as_tibble(matrix(NA_character_, ncol = 6, nrow = length(headers)), .name_repair = 'minimal')
colnames(data) <- c('id', 'run_id', 'sample_id', 'read', 'channel', 'start_time')
for (i in 1:length(headers)) {
data[i,] <- toString(headers[[i]]) %>%
strsplit(' ') %>%
unlist() %>%
str_remove_all(".*=") %>% t()
}5.5 Preparing tidy dataset
Now, the fun part begins:
- add column
start_dttmthat represents start time for a given read as properdatetimeobject (readlubridatedocs) and - add column
chanthat is the proper numeric representation of the channel, - group reads by channel,
- arrange them by time,
- add time to next read (NA if this was the last read) and
- sort by channel again.
Read about lead()
data2 <- data %>%
mutate(start_dttm = as_datetime(start_time)) %>%
mutate(chan=as.numeric(channel)) %>%
group_by(chan) %>%
arrange(start_dttm) %>%
mutate(time_diff = lead(start_dttm) - start_dttm) %>%
arrange(chan)5.6 Plotting events per channel
Here, we want to see what was happening in each channel over time. Plot the data you have just prepared so that:
- each point is the start of a new read,
- colour corresponds to the lag to the next read.
Can you visualise this in a better way? Different geometry?
ggplot(data2, mapping = aes(x = start_dttm,
y = as.factor(chan),
col = as.numeric(time_diff)
)
) +
geom_point(size = .5) +
theme_bw()
5.7 Distribution of time intervals
Now, we want to see how time-to-next-read is distributed. Since it has a veeeeery long right tail, I am cutting off everything above 200 seconds (just by eyeballing).
- plot time-to-next-read is distribution (you can use base-R
histogram), - can you find a better cutoff value?
# Show time-to-next read distribution
# thr <- mean(data2$time_diff, na.rm = T) + 3 * sd(data2$time_diff, na.rm = T)
tmp <- data2 %>%
ungroup() %>%
filter(time_diff < 200) %>%
select(time_diff)
hist(as.numeric(tmp$time_diff), breaks = 1000, las=1)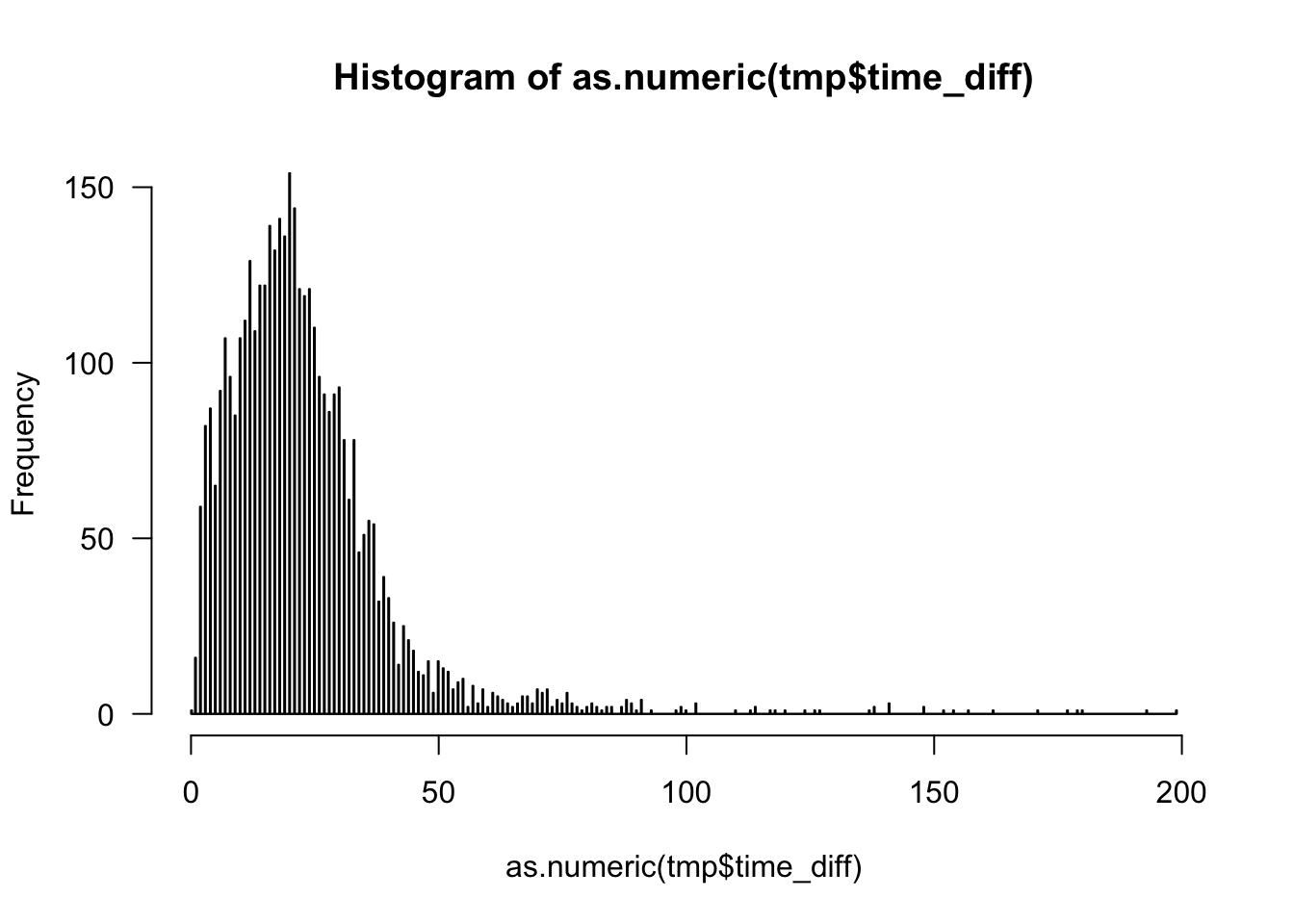
6 Species Identification Challenge
In this challenge, your task will be to analyse species composition of some samples. The samples, were actual products containing parts of plants. DNA has been isolated form the samples and an amplicon metabarcoding was performed using two sets of primers: for the ITS1 and the ITS2 region. Each sample had 3 technical replicates. Your task will be to transform BLAST output to a tidy form suitable for further analyses or visualisation.
6.1 Load necessary libraries
We will obviously need tidyverse, we will also do some string manipulations with stringr also here package is good to have.
library(tidyverse)
library(stringr)
library(here)6.2 Input variables
Here, we will define our input variables. We need:
filethat contains the path to the dataset,sample_nameis a string, the name of the sample you want to analyse,thresholdis an integer saying what is a the minimal number of replicates that have to contain an OTU in order to call it a true positive (TP),stricta logical. If set to TRUE, only the OTUs deemed TP will be shown.
Below we set some example values:
# Change the path to your project path, where your data is
file <- here::here("docs/tidyverse_Marcin/lab/lab_assets/blast_result.csv")
sample_name <- 'SAMPLE12'
threshold <- 1
strict <- F6.3 Reading the data
Now, you should read the data:
species_orig <- read_csv(file, col_names = c("sample","its","replicate","OTU","size","hit","perc_ident","score","family","species")) %>%
select(-score)
head(species_orig,n = 10)As you see, the following information are included in the data:
sampleis simply the name of the sample,itsis either ITS1 or ITS2 and tells which set of PCR primers has been used,replicatecontains information on which replicate the sequences come from,OTUis a unique identifier of the so-called Operational Taxonomic Unit, an OTU often corresponds to one species but not always. Sometimes 2 OTUs represent the same species, sometimes 1 OTU consists of more than one species,sizeis the number of reads that support that particular OTU,hitis the BLAST hit identifier. The 4 top BLAST hits are reported per OTU,perc_identityis the percentage identity of the sequence to the BLAST hit,familyis the identified plant family,speciesis the identified plant species.
6.4 Number of replicates per species
Create a new dataset species that contains an extra column n_replicates. The column contains number of replicates this particular species is present in. Do it per sample and its.
species <- species_orig %>%
group_by(sample, its, species) %>%
mutate(n_replicates = n_distinct(replicate)) %>%
ungroup()
head(species,n = 10)6.5 Filter out unwanted samples
Now, your task is to filter out all but your sample_name samples from the dataset.
Call the resulting dataset my_sample.
my_sample <- species %>%
filter(sample == sample_name)6.6 Missing observations
What happens if a set of primers failed to amplify or if one replicate was lost?
Use complete() to make sure you have NA values in such cases.
my_sample <- my_sample %>%
complete(its = c("ITS1", "ITS2"),
replicate = c("R1","R2","R3"))6.7 Sorting issue
Look, the first sample in the table is SAMPLE10. Why not SAMPLE1?
That’s a sorting issue: if sorted as character, 10 will come before 1. WE have to fix this by adding trailing zero to the values in OTU. We do not expect more than 99 OTUs in a sample, so it is ok with only one trailing 0 (otherwise the 100-th sample will spoil our sorting and come out like: SAMPLE100, SAMPLE01, SAMPLE10). We will need to use regular expression:
- all values in the
OTUcolumn that follow pattern “OTUdigit” we need to change to “OTU0digit”. Regular expression that matches this isOTU([0-9]$)and it should be replaced by:OTU0\\1. Ask your TAs to explain this if you do not know much about regular expressions and pattern matching.
my_sample <- my_sample %>%
mutate(OTU = str_replace(OTU,pattern = "OTU([0-9]$)",
replacement = "OTU0\\1"))
head(my_sample,n = 10)6.8 Supporting reads
Sometimes, an OTU generates two or more top BLAST hits that come from the same species. We have decided to sum reads in such cases. Do it!
my_sample <- my_sample %>%
ungroup() %>%
group_by(sample, its, replicate, OTU, species, n_replicates) %>%
summarise(n_reads = sum(size)) %>%
ungroup() %>%
group_by(its, species, OTU)
head(my_sample,n=10)6.9 Within-OTU species diversity
Now, we want to see how many identifications an OTU got. Implement this. Store the result in a new tibble diversity.
diversity <- my_sample %>%
ungroup() %>%
group_by(its, replicate, OTU) %>%
summarise(n_species = n())
head(diversity,n=10)6.10 Adding diversity data
Add the diversity data to my_sample using appropriate join function. Also, remove the column with sample names since we are dealing with only one sample.
my_sample <- my_sample %>%
left_join(diversity) %>%
select(-sample)
head(my_sample,n=10)- what columns did we join on in our example solution?
6.11 Visualising the data
Can you think of a good way of visualising the data? Think of:
- Type of plot you want. The simpler the better?
- Which variables you would like to visualise? We have chosen
ITS,replicate,n_reads,n_replicates,OTU,threshold,n_speciesandspecie. Well, pretty much all of them :-) - How do you represent variables: colours, shapes, separate plots, sizes?
- What transformations do you need to apply before visualising the data?
Our example solution involves some ggplot2 magics. But would base-R be good enough for this type of plot?
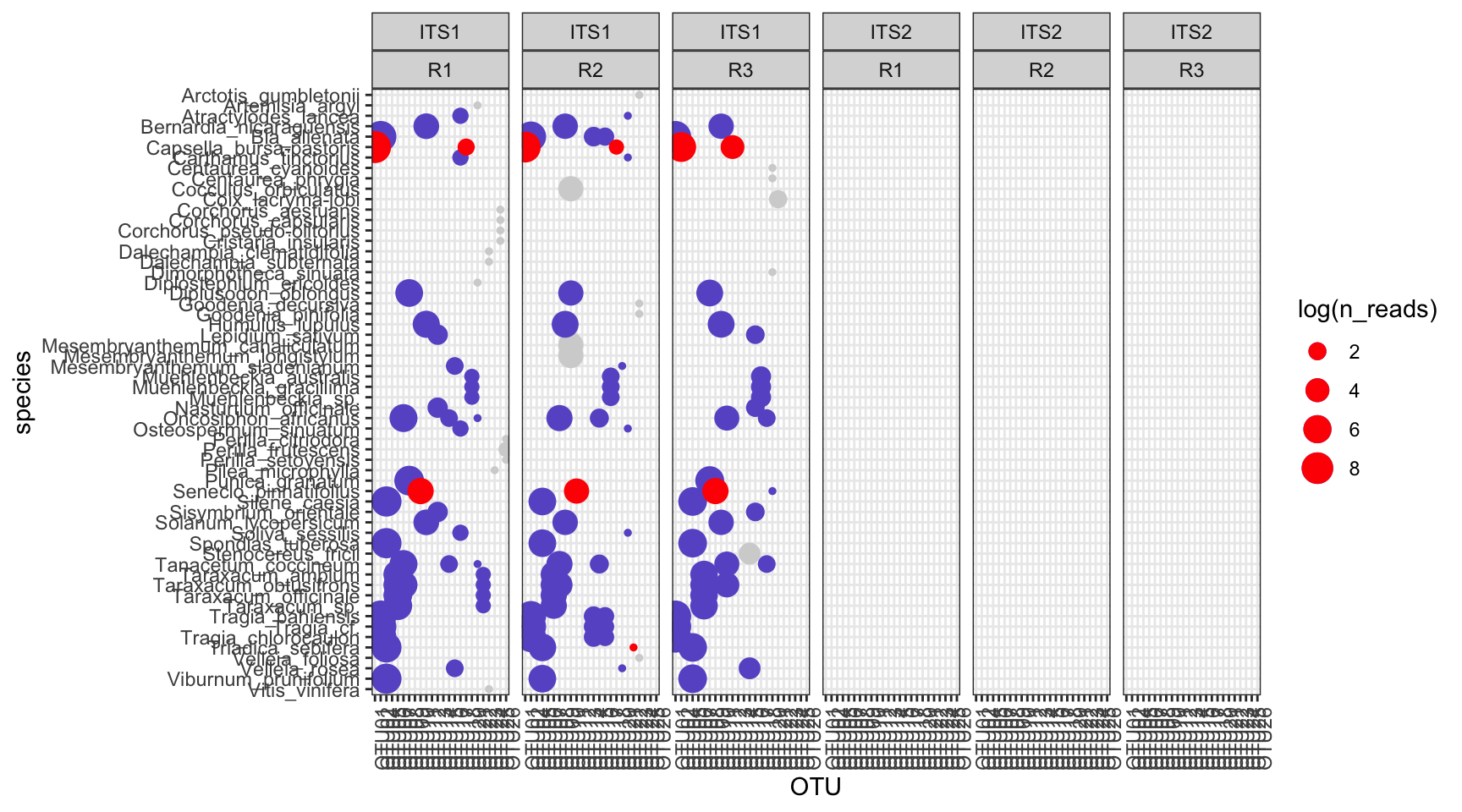
Figure 6.1: Red – only one species in the current OTU, blue – identification above the threshold, grey – identification below the threshold
7 Wildlife Aircraft Strikes Challenge
Use the FAA report and tidyverse to learn more about aircraft incidents with wildlife. Use your imagination and NYC data science blog for inspiration!
8 Session info
## R version 4.1.1 (2021-08-10)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] lubridate_1.7.10 ShortRead_1.52.0
## [3] GenomicAlignments_1.30.0 SummarizedExperiment_1.24.0
## [5] Biobase_2.54.0 MatrixGenerics_1.6.0
## [7] matrixStats_0.62.0 Rsamtools_2.10.0
## [9] GenomicRanges_1.46.1 Biostrings_2.62.0
## [11] GenomeInfoDb_1.30.1 XVector_0.34.0
## [13] IRanges_2.28.0 S4Vectors_0.32.4
## [15] BiocParallel_1.28.3 BiocGenerics_0.40.0
## [17] here_1.0.1 EDAWR_0.1
## [19] eulerr_6.1.1 bsplus_0.1.3
## [21] forcats_0.5.1 stringr_1.4.0
## [23] dplyr_1.0.7 purrr_0.3.4
## [25] readr_1.4.0 tidyr_1.1.3
## [27] tibble_3.1.2 tidyverse_1.3.1
## [29] ggplot2_3.3.5 fontawesome_0.2.2
## [31] captioner_2.2.3 bookdown_0.22
## [33] knitr_1.33
##
## loaded via a namespace (and not attached):
## [1] bitops_1.0-7 fs_1.5.0 RColorBrewer_1.1-2
## [4] httr_1.4.2 rprojroot_2.0.2 tools_4.1.1
## [7] backports_1.2.1 bslib_0.3.1 utf8_1.2.1
## [10] R6_2.5.0 DBI_1.1.1 colorspace_2.0-2
## [13] withr_2.4.2 tidyselect_1.1.1 compiler_4.1.1
## [16] cli_3.0.0 rvest_1.0.0 xml2_1.3.2
## [19] DelayedArray_0.20.0 labeling_0.4.2 sass_0.4.1
## [22] scales_1.1.1 digest_0.6.27 rmarkdown_2.13
## [25] jpeg_0.1-9 pkgconfig_2.0.3 htmltools_0.5.2
## [28] dbplyr_2.1.1 fastmap_1.1.0 highr_0.9
## [31] rlang_0.4.11 readxl_1.3.1 rstudioapi_0.13
## [34] farver_2.1.0 jquerylib_0.1.4 generics_0.1.0
## [37] hwriter_1.3.2.1 jsonlite_1.7.2 RCurl_1.98-1.7
## [40] magrittr_2.0.1 GenomeInfoDbData_1.2.7 Matrix_1.3-4
## [43] Rcpp_1.0.7 munsell_0.5.0 fansi_0.5.0
## [46] lifecycle_1.0.0 stringi_1.6.2 yaml_2.2.1
## [49] zlibbioc_1.40.0 grid_4.1.1 parallel_4.1.1
## [52] crayon_1.4.1 lattice_0.20-44 haven_2.4.1
## [55] hms_1.1.0 polylabelr_0.2.0 pillar_1.6.1
## [58] reprex_2.0.0 glue_1.4.2 evaluate_0.14
## [61] latticeExtra_0.6-29 modelr_0.1.8 png_0.1-7
## [64] vctrs_0.3.8 cellranger_1.1.0 gtable_0.3.0
## [67] polyclip_1.10-0 assertthat_0.2.1 xfun_0.30
## [70] broom_0.7.8 ellipsis_0.3.2Built on: 16-Jun-2022 at 12:04:16.
2022 • SciLifeLab • NBIS • RaukR

